import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import os
import re
import datetime
# 显存自适应分配
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu,True)
gpu_ok = tf.test.is_gpu_available()
print("tf version:", tf.__version__)
print("use GPU", gpu_ok) # 判断是否使用gpu进行训练
读取数据
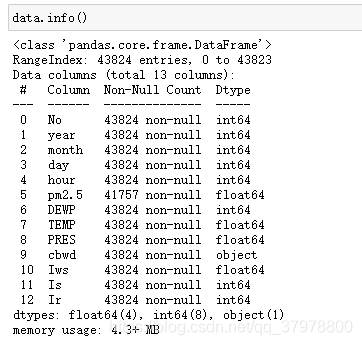
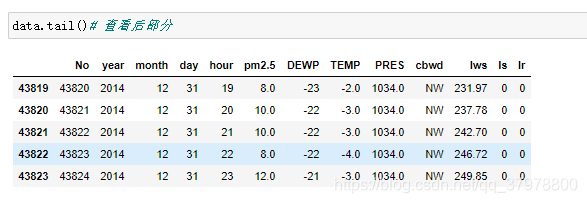
data = pd.read_csv ("F:/py/ziliao/数据集/PRSA_data_2010.1.1-2014.12.31.csv")

预处理

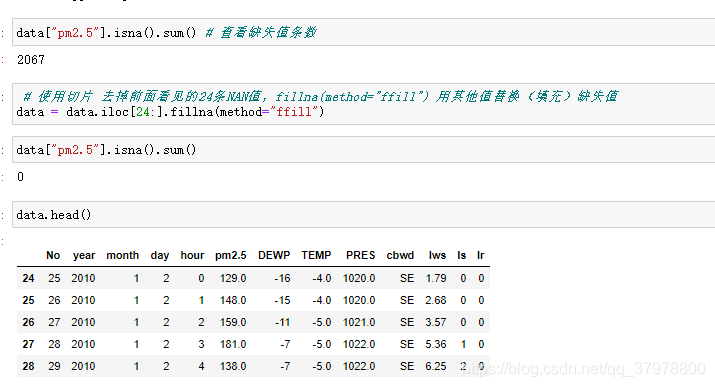
时间合并

data["tm"] = data.apply(lambda x:datetime.datetime(year=x["year"],
month=x["month"],
day=x["day"],
hour=x["hour"]),
axis=1
) # 组合时间 并加入数据集 命名tm
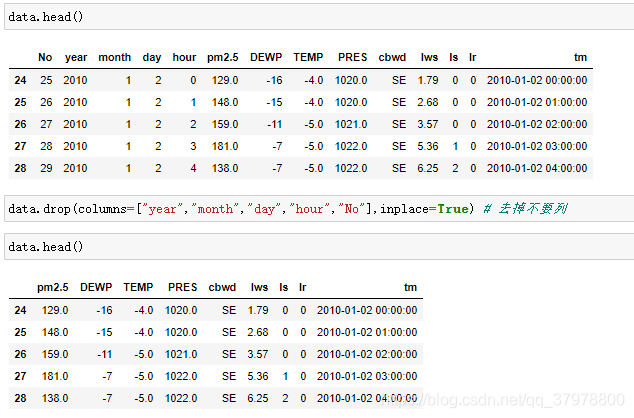
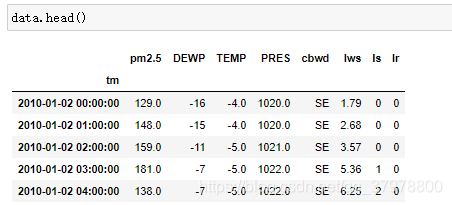
data = data.set_index("tm")# 设置tm为数据集的索引

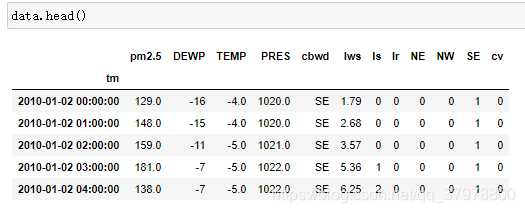
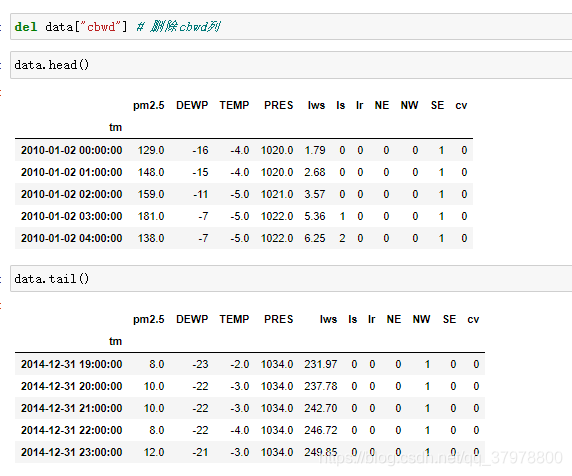
data = data.join(pd.get_dummies(data.cbwd)) # 把风向转换成独热编码
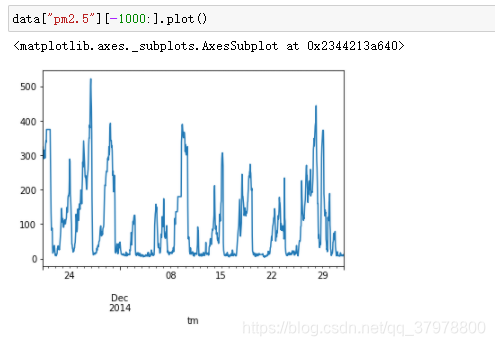
构造训练数据与目标数据
# 样本中是每隔一小时采集一次数据,
# 我们可以用前5天的数据去预测明天的pm2.5的值
# 从当前点来看 前5天的数据为 train数据 后一天的数据为label
# 如 今天是 2020年1月6日 我们手里有1月1日到5日的数据 那么我们需要预测的数据就是明天的值
seq_length = 5 * 24
delay = 24
data_ = []
for i in range(len(data)-seq_length-delay):
data_.append(data.iloc[i:i+seq_length+delay])
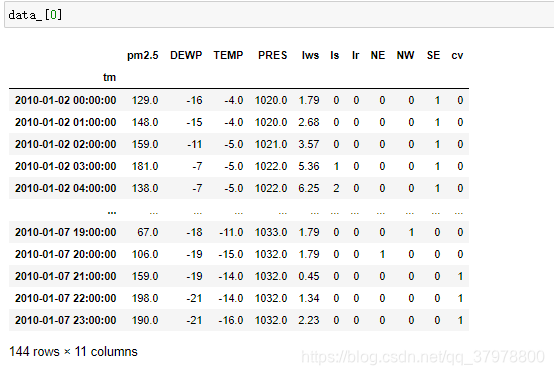
data_ = np.array([df.values for df in data_])

np.random.shuffle(data_)# 乱序
提取训练特征和目标值
# 提取训练特征和目标值
x = data_[:,:5*24,:] # 特征
x.shape
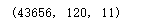
y = data_[:,-1,0] # 目标值
y.shape
# 划分数据集及 前百分之80为训练集 后百分20为测试集
split_b = int(data_.shape[0]*0.8)
train_x = x[:split_b]
train_y = y[:split_b]
test_x = x[split_b:]
test_y = y[split_b:]
train_x.shape,train_y.shape
test_x.shape,test_y.shape

标准化
mean = train_x.mean(axis=0) # 按列求均值
std = train_x.std(axis=0) # 按列求方差
train_x = (train_x-mean)/std
test_x = (test_x-mean)/std
基础建模-多层感知机进行预测
batch_size = 128
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(train_x.shape[1:])))
model.add(tf.keras.layers.Dense(32,activation="relu"))
model.add(tf.keras.layers.Dense(1))
model.compile(
optimizer="adam",
loss="mae", # 平均绝对误差
metrics=["acc"]
)
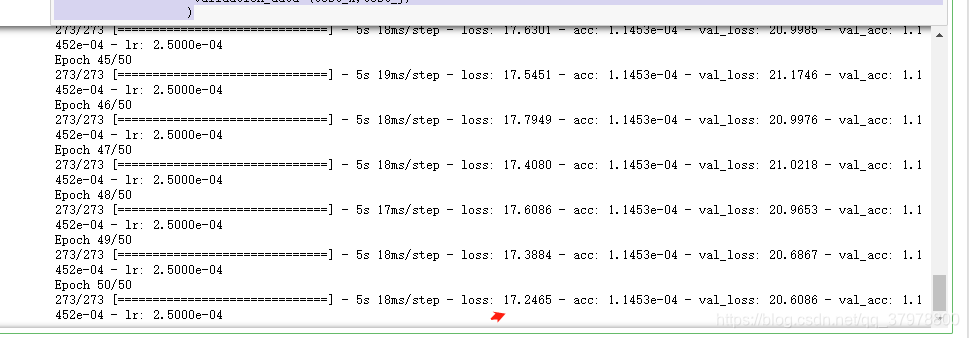
history = model.fit(train_x,train_y,
batch_size=batch_size,
epochs=50,
validation_data=(test_x,test_y)
)


LSTM网络建模
model2 = tf.keras.Sequential()
model2.add(tf.keras.layers.LSTM(32,input_shape=(120,11)))
model2.add(tf.keras.layers.Dense(1))
model2.compile(
optimizer="adam",
loss="mae", # 平均绝对误差
metrics=["acc"]
)
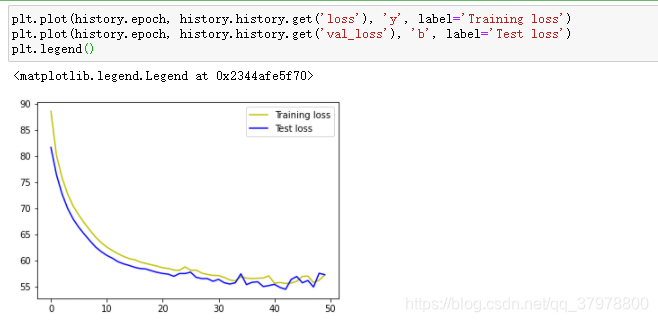
history = model2.fit(train_x,train_y,
batch_size=batch_size,
epochs=50,
validation_data=(test_x,test_y)
)
LSTM层的优化(堆叠)
model3 = tf.keras.Sequential()
model3.add(tf.keras.layers.LSTM(32,input_shape=(120,11),return_sequences=True))
model3.add(tf.keras.layers.LSTM(32,return_sequences=True))
model3.add(tf.keras.layers.LSTM(32,return_sequences=True))
model3.add(tf.keras.layers.LSTM(32))
model3.add(tf.keras.layers.Dense(1))
# 降低学习速率
lr_reduce = tf.keras.callbacks.ReduceLROnPlateau("val_loss",patience=3,factor=0.5,min_lr=0.000001)
model3.compile(
optimizer="adam",
loss="mae", # 平均绝对误差
metrics=["acc"]
)
history = model3.fit(train_x,train_y,
batch_size=batch_size,
epochs=50,
callbacks=[lr_reduce],
validation_data=(test_x,test_y)
)