






















import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import glob
import os
os.listdir('../input/anime-faces/data/data')[:10]

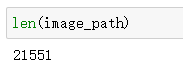
image_path = glob.glob('../input/anime-faces/data/data/*.png')
def load_preprosess_image(path):
image = tf.io.read_file(path)
image = tf.image.decode_png(image, channels=3)
# image = tf.image.resize_with_crop_or_pad(image, 256, 256)
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
image_ds = tf.data.Dataset.from_tensor_slices(image_path)
AUTOTUNE = tf.data.experimental.AUTOTUNE
image_ds = image_ds.map(load_preprosess_image, num_parallel_calls=AUTOTUNE)

BATCH_SIZE = 256
image_count = len(image_path)
image_ds = image_ds.shuffle(image_count).batch(BATCH_SIZE)
image_ds = image_ds.prefetch(AUTOTUNE)
def generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(8*8*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((8, 8, 256))) #8*8*256
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU()) #8*8*128
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU()) #16*16*128
model.add(layers.Conv2DTranspose(32, (5, 5), strides=(2, 2), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU()) #32*32*32
model.add(layers.Conv2DTranspose(3, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
#64*64*3
return model
generator = generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
#plt.imshow((generated_image[0, :, :, :3] + 1)/2)
def discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(32, (5, 5), strides=(2, 2), padding='same',
input_shape=[64, 64, 3]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3)) # 32*32*32
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3)) # 16*16*64
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# model.add(layers.Dropout(0.3)) # 8*8*128
model.add(layers.Conv2D(256, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU()) # 4*4*256
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(1024))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(1))
return model
discriminator = discriminator_model()
decision = discriminator(generated_image)
print(decision)
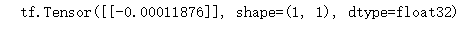
def discriminator_loss(real_output, fake_output):
return tf.reduce_mean(fake_output) - tf.reduce_mean(real_output)
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
generator_optimizer = tf.keras.optimizers.RMSprop(1e-4)
discriminator_optimizer = tf.keras.optimizers.RMSprop(5e-5)
EPOCHS = 800
noise_dim = 100
num_examples_to_generate = 4
seed = tf.random.normal([num_examples_to_generate, noise_dim])
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
for idx, grad in enumerate(gradients_of_discriminator):
gradients_of_discriminator[idx] = tf.clip_by_value(grad, -0.01, 0.01)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
return gen_loss, disc_loss
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(6, 6))
for i in range(predictions.shape[0]):
plt.subplot(2, 2, i+1)
plt.imshow((predictions[i, :, :, :] + 1)/2)
plt.axis('off')
# plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
epoch_loss_avg_gen = tf.keras.metrics.Mean('g_loss')
epoch_loss_avg_disc = tf.keras.metrics.Mean('d_loss')
g_loss_results = []
d_loss_results = []
def train(dataset, epochs):
for epoch in range(epochs):
for image_batch in dataset:
g_loss, d_loss = train_step(image_batch)
epoch_loss_avg_gen(g_loss)
epoch_loss_avg_disc(d_loss)
g_loss_results.append(epoch_loss_avg_gen.result())
d_loss_results.append(epoch_loss_avg_disc.result())
epoch_loss_avg_gen.reset_states()
epoch_loss_avg_disc.reset_states()
# print('.', end='')
# print()
if epoch%10 == 0:
# print('epoch:', epoch, 'g_loss:', g_loss, 'd_loss:', d_loss)
generate_and_save_images(generator,
epoch + 1,
seed)
generate_and_save_images(generator,
epochs,
seed)
train(image_ds, EPOCHS)


plt.plot(range(1, len(g_loss_results)+1), g_loss_results, label='g_loss')
plt.plot(range(1, len(d_loss_results)+1), d_loss_results, label='d_loss')
plt.legend()

代码二
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
real_img = tf.placeholder(tf.float32, [None, 784], name='real_img')
noise_img = tf.placeholder(tf.float32, [None, 100], name='noise_img')
def generator(noise_img, hidden_units, out_dim, reuse=False):
with tf.variable_scope("generator", reuse=reuse):
hidden1 = tf.layers.dense(noise_img, hidden_units)
hidden1 = tf.nn.relu(hidden1)
# logits & outputs
logits = tf.layers.dense(hidden1, out_dim)
outputs = tf.nn.sigmoid(logits)
return logits, outputs
def discriminator(img, hidden_units, reuse=False):
with tf.variable_scope("discriminator", reuse=reuse):
# hidden layer
hidden1 = tf.layers.dense(img, hidden_units)
hidden1 = tf.nn.relu(hidden1)
# logits & outputs
outputs = tf.layers.dense(hidden1, 1)
return outputs
def plot_images(samples):
fig, axes = plt.subplots(nrows=1, ncols=25, sharex=True, sharey=True, figsize=(50,2))
for img, ax in zip(samples, axes):
ax.imshow(img.reshape((28, 28)), cmap='Greys_r')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
fig.tight_layout(pad=0)
img_size = 784
noise_size = 100
hidden_units = 128
learning_rate = 0.0001
g_logits, g_outputs = generator(noise_img, hidden_units, img_size)
# discriminator
d_real = discriminator(real_img, hidden_units)
d_fake = discriminator(g_outputs, hidden_units, reuse=True)
d_loss = tf.reduce_mean(d_real) - tf.reduce_mean(d_fake)
g_loss = -tf.reduce_mean(d_fake)
train_vars = tf.trainable_variables()
g_vars = [var for var in train_vars if var.name.startswith("generator")]
d_vars = [var for var in train_vars if var.name.startswith("discriminator")]
d_train_opt = tf.train.RMSPropOptimizer(learning_rate).minimize(-d_loss, var_list=d_vars)
g_train_opt = tf.train.RMSPropOptimizer(learning_rate).minimize(g_loss, var_list=g_vars)
clip_d = [p.assign(tf.clip_by_value(p, -0.01, 0.01)) for p in d_vars] # 对discriminator变量使用clip
batch_size = 32
n_sample = 25
samples = []
losses = []
saver = tf.train.Saver(var_list = g_vars)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for it in range(1000000):
for _ in range(5):
batch_images, _ = mnist.train.next_batch(batch_size)
batch_noise = np.random.uniform(-1, 1, size=(batch_size, noise_size))
_ = sess.run([d_train_opt, clip_d], feed_dict={real_img: batch_images, noise_img: batch_noise})
_ = sess.run(g_train_opt, feed_dict={noise_img: batch_noise})
if it%10000 == 0:
sample_noise = np.random.uniform(-1, 1, size=(n_sample, noise_size))
_, samples = sess.run(generator(noise_img, hidden_units, img_size, reuse=True),
feed_dict={noise_img: sample_noise})
plot_images(samples)
# 每一轮结束计算loss
train_loss_d = sess.run(d_loss,
feed_dict = {real_img: batch_images,
noise_img: batch_noise})
# generator loss
train_loss_g = sess.run(g_loss,
feed_dict = {noise_img: batch_noise})
print("Epoch {}/{}...".format(it, 1000000),
"Discriminator Loss: {:.4f}...".format(train_loss_d),
"Generator Loss: {:.4f}".format(train_loss_g))
# 记录各类loss值
losses.append((train_loss_d, train_loss_g))
# 存储checkpoints
saver.save(sess, './checkpoints/generator.ckpt')

