一.定义
HDFS(Hadoop Distributed File System):它是一个文件系统,用于储存文件,通过目录树来定位文件。同时,它是分布式的,由很多服务器联系起来实现其功能,集群的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读入的场景,且不支持文件的修改。适合用来做数据分析,不适合做网盘应用。
二.优点
1.高容错性:
a):数据自动保存为多个副本。它通过增加副本的方式,提高容错性
b) : 某一个副本丢失以后,它可以自动恢复
2.适合处理大数据
a) : 数据规模:能够处理数据的规模达到GB,TB,甚至PB级别的数据
b:):文件规模:能处理百万规模以上的文件数量,数量非常之大
3.可以构建在廉价的及其之上,通过多副本机制,提高可用性
三.缺点
1.不适合低延时的数据访问,比如毫秒级的存储数据,这是不可能做到的
2.无法高效的对大量小文件进行储存
a:储存大量小文件的话,它会占用NameNode的大量内存来春村文件目录和块信息,这样是不可取的,因为NameNode的内存总是有限的。
b:小文件的寻址时间会超过读取时间,它违反了HDFS的设计目标
3.不支持并发写入,文件的随机修改
a:一个文件只能有一个写,不允许多个线程同时写
b:仅支持追加模式(append),不能够将已经写好的文件进行修改。
四.HDFS组成架构
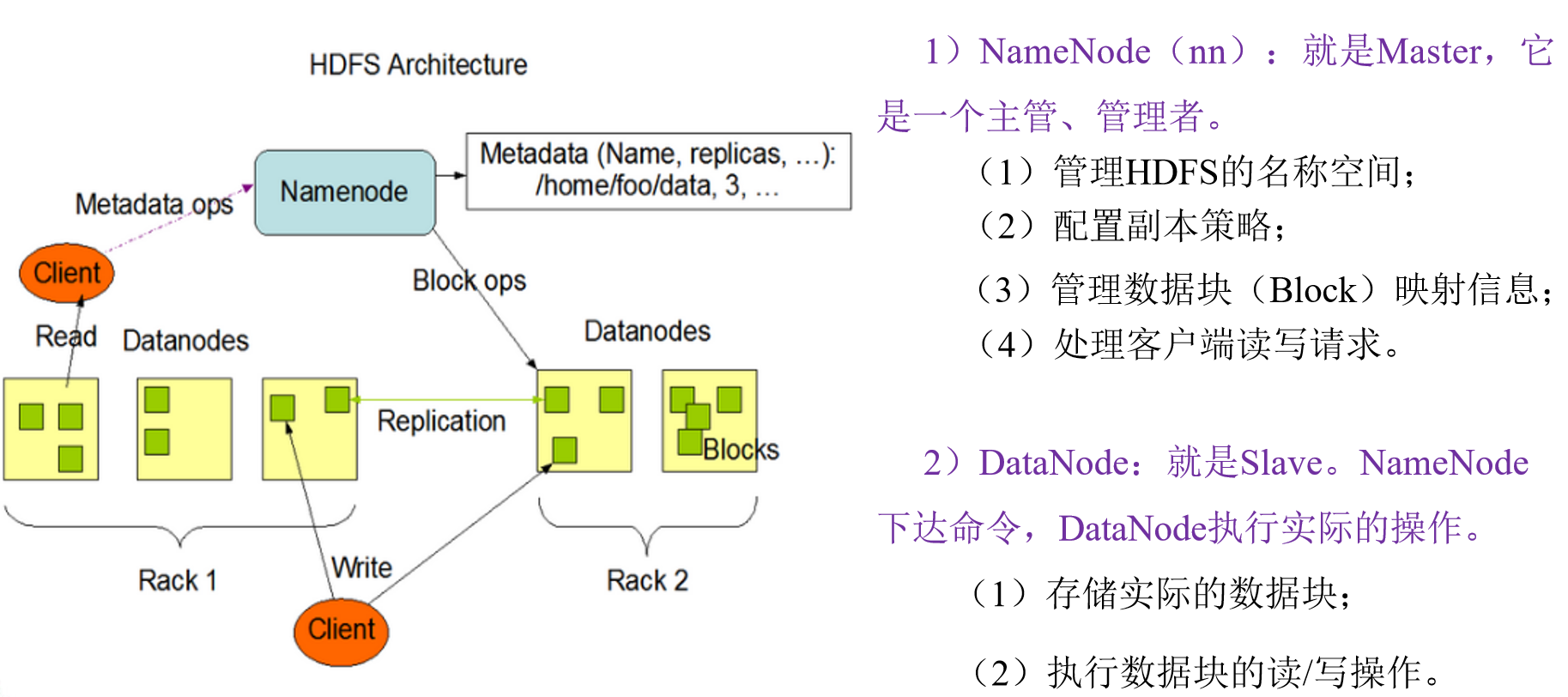
HDFS在储存文件的时候,以块block为单位,而不是以文件为单位。NameNode会记录所有的读写请求,并下放给DataNode进行实施。每一个DataNode只能够保存一个文件的副本。

客户端Client也是haoop的一部分,而非我们实际用户所使用的客户端。
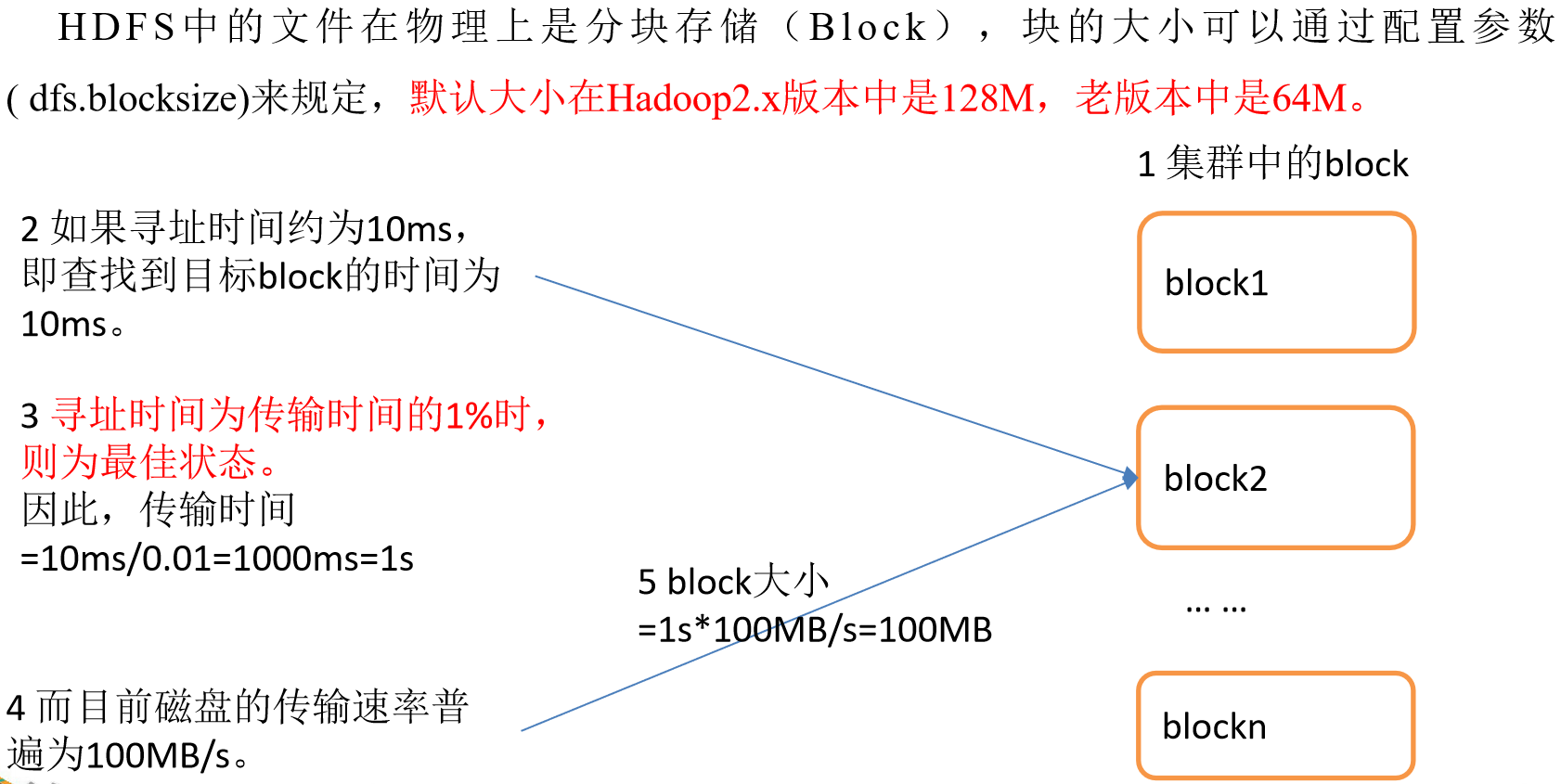
重点:但是块的大小不能设置太小,也不能设置太大
-
太大
- 在一些分块读取的场景,不够灵活,会带来额外的网络消耗
- 在上传文件时,一旦发生故障,会造成资源的浪费
-
太小
- 同样大小的文件,会占用过多的NN的元数据空间
- 在进行读写操作时,会消耗额外的寻址时间,因为块太小,在相同内存的情况下意味着地址addresses就会变多,这样就会消耗更长的时间来进行寻址。