JavaScript解释器在浏览器中是单线程的,这意味着浏览器在同一时间内只执行一个事件,对于其他的事件我们把它们排队在一个称为 执行栈(调用栈)
的地方。下表是一个单线程栈的抽象视图:
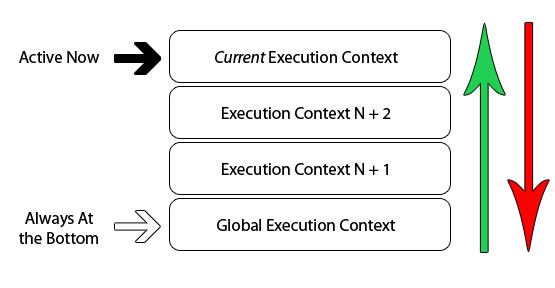
我们已经知道,当浏览器第一次加载你的script,它默认的进了全局执行环境。如果在你的全局代码中你调用了一个函数,那么执行流就会进入到你调用的函数当中,创建一个新的执行环境并且把这个环境添加到执行栈的顶部。
如果你在当前的函数中调用了其他函数,同样的事会再次发生。执行流进入内部函数,并且创建一个新的执行环境,把它添加到已经存在的执行栈的顶部。浏览器始终执行当前在栈顶部的执行环境。一旦函数完成了当前的执行环境,它就会被弹出栈的顶部, 把控制权返回给栈中的下个执行环境。
事件循环机制:上面讲了执行栈中的所有任务从顶向下同步执行;但当遇到一些需要异步执行的任务,如ajax、setTimeout等时,会立即返回函数,然后将异步操作交给浏览器内核中的其他模块处理(如timer、network、DOM Binding模块),接着主线程继续往下执行 栈中的任务。
当上面说的异步操作完成后如ajax接受完响应、setTimeout到达指定延时;这些任务 即回调函数会被放入到任务队列中。一般不同的异步任务的回调函数会放入不同的任务队列之中。(分为宏任务和微任务;优先执行微任务队列)
只有当执行栈为空时,执行引擎才会去看任务队列有无可执行的任务;如果有,就取一个放入到执行栈中执行。执行完后,执行栈为空,便又去检查任务队列。 不断地循环重复上述过程的机制,就是“事件循环”。
引自Philip Roberts的演讲《Help, I'm stuck in an event-loop》中的图来表示:
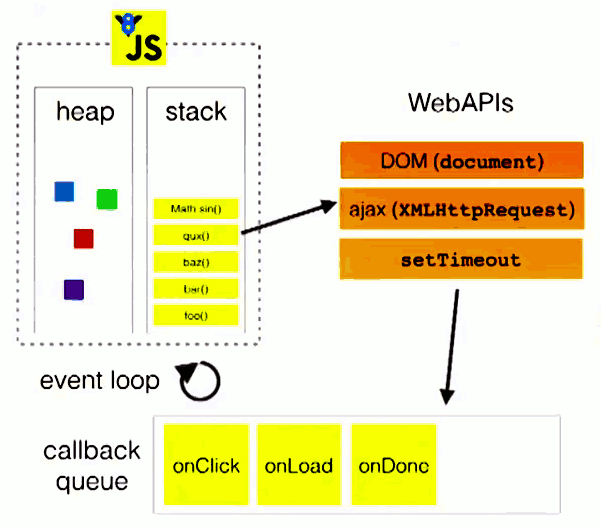
有个可以注意的地方: 因为事件循环这种执行机制,所以会导致一些异步任务的准确执行时间是不可控的,例如setTimeout(callback, 1000); 这条语句,只能保证是在1秒后将回调函数放入相应任务队列的队尾,但具体会多久后执行是不确定的;也许是立即就可以执行,又也许在队列头部还有许多耗时较久的任务,那么就可能会在很长时间后才开始执行callback。