1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页
2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享
3,Queue 中存放的是所有的代理,我们要分离出可用的代理,所以再搞个队列,存放可用代理,
4,检测速度过慢,效率低,引入 gevent,猴子补丁 一次多个检测
5,将分离出的有用代理存入 mongodb
另开个进程操作
6, flask web 框架 , API接口,
7,调度,每次开启时先对数据库中的代理进行检测,

因为maogo db无法远程连接,所以改成了用 json 存数据到本地的方法,一样可以实现代理
configure 是配置文件,把免费代理的网址放入 parser_list 中,
可以放入多个免费代理的网址, url 由 for 循环生成,实现翻页的功能,
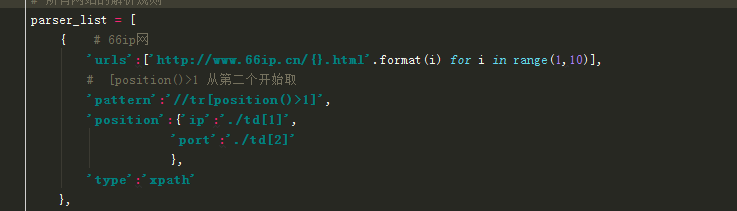
Parser 解析方法,由 configure 传过来的 type 判断是用 xpath 还是用 re 解析,
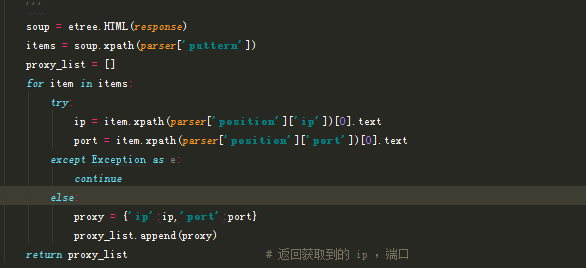
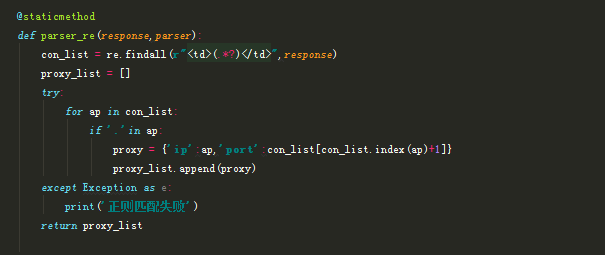
Server 在 flask 的基础上实现 API 接口,
spider_ 为运行的主程序,实现 ip ,端口的爬取,检测,存储,再检测再存储...