win 下安装 scrapy
先安装 pip install wheel
py 库下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
在这个网址中下载 Scrapy 和 twisted ,pywin32
下载 twisted,在其所在文件夹十打开 cmd , pip install 安装 ,之后安装 Scrapy,
用这行命令
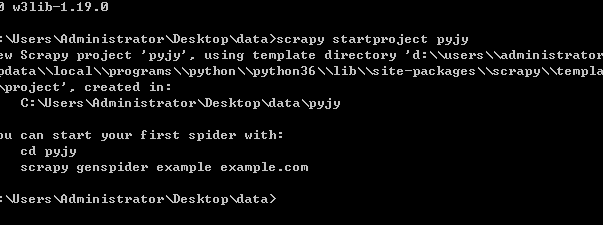
scrapy startproject pyjy
测试是否成功,如果 成功 在 C:UsersAdministratordata 下将有新项目

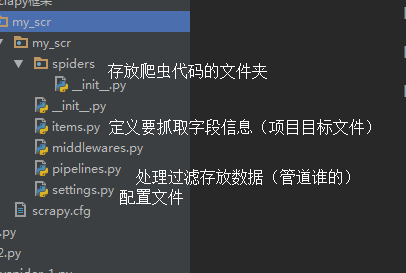
创建 spiders 文件,:打开该文件夹,在该文件夹下打开cmd,
输入 scrapy genspider example example.com
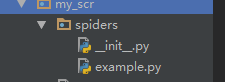
此时可以看到多了个 py 文件
查看可执行文件: scrapy list

运行命令: scrapy crawl example
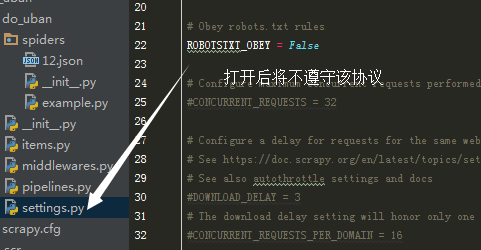
robots协议
当 parse 方法没有运行,

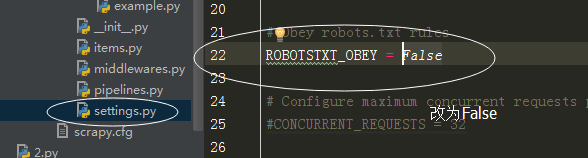
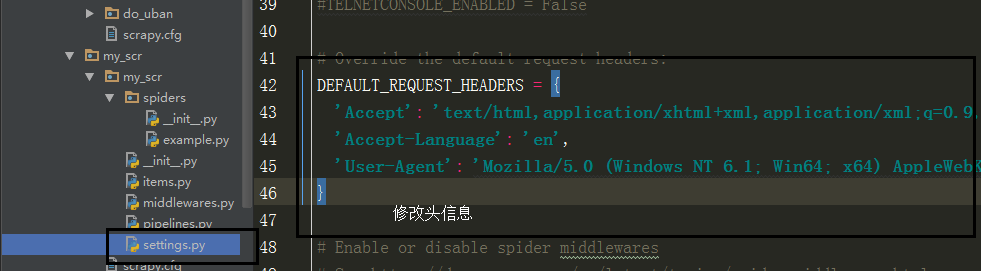
修改头文件
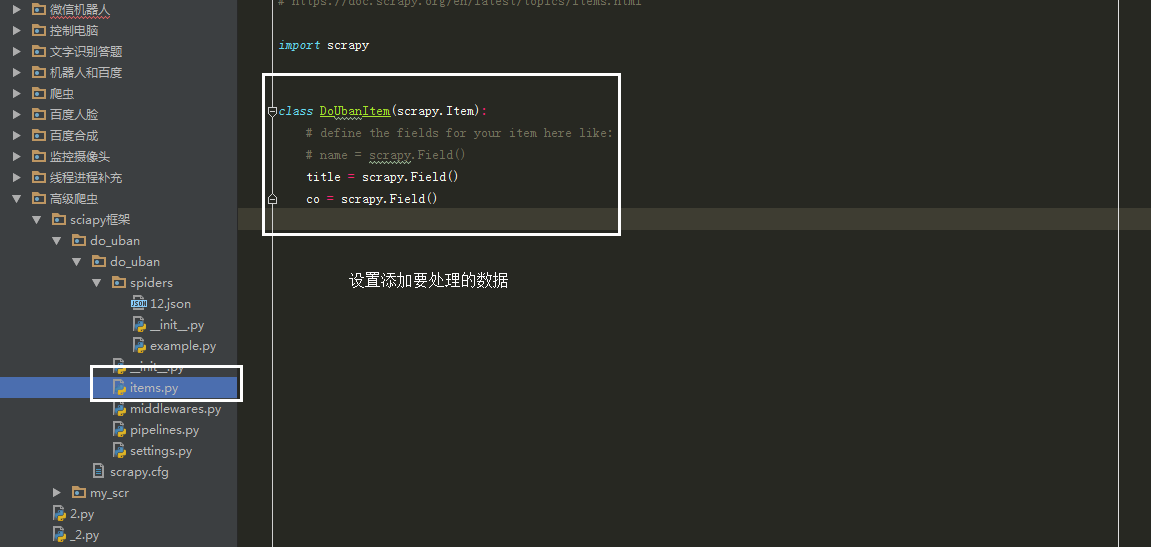
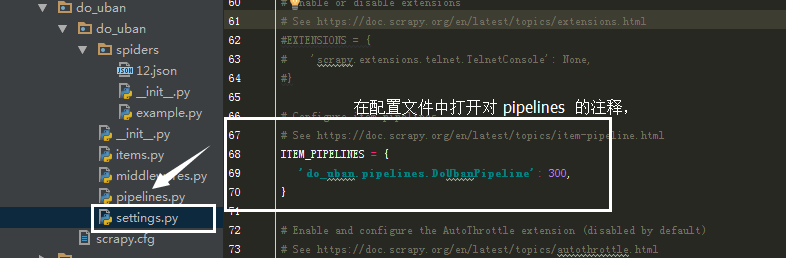
豆瓣数据



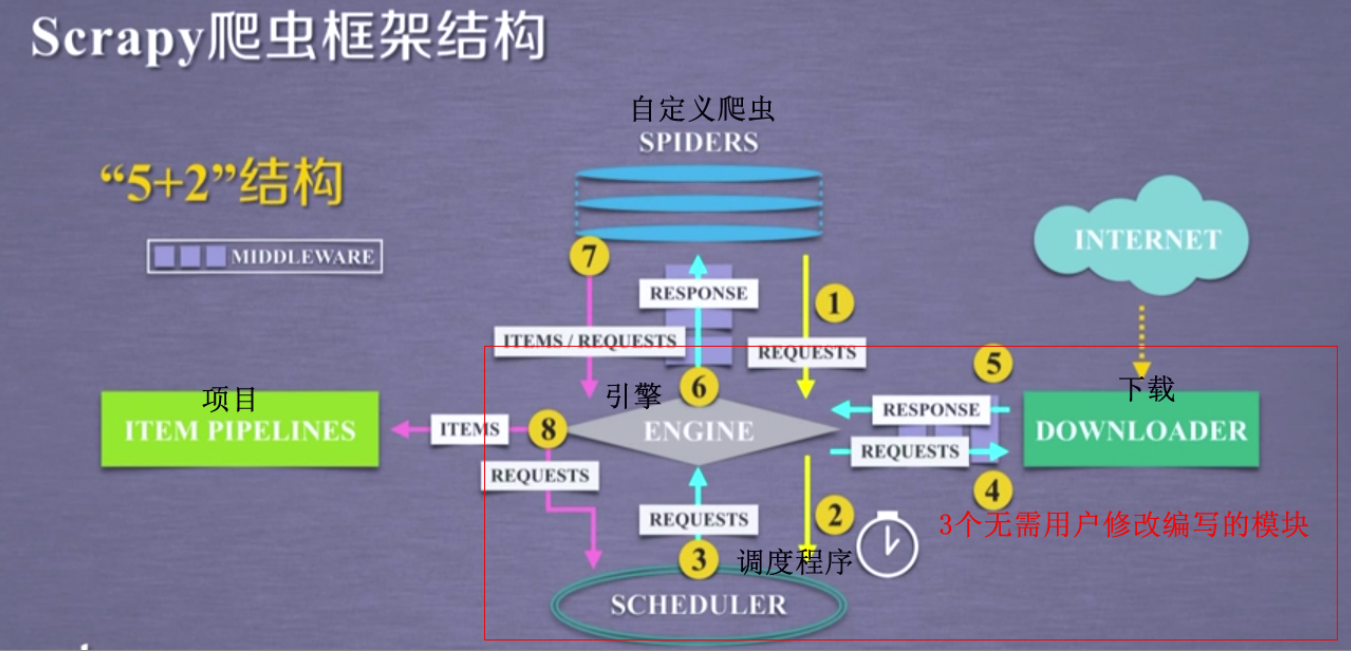
由 scheduler 发送访问请求,经过 engine 到达 downloader ,如果用户要对这些请求做配置,在这些模块之间有个下载中间件
在这个中间件中实现用户对这三个模块间的数据流可配置的控制。
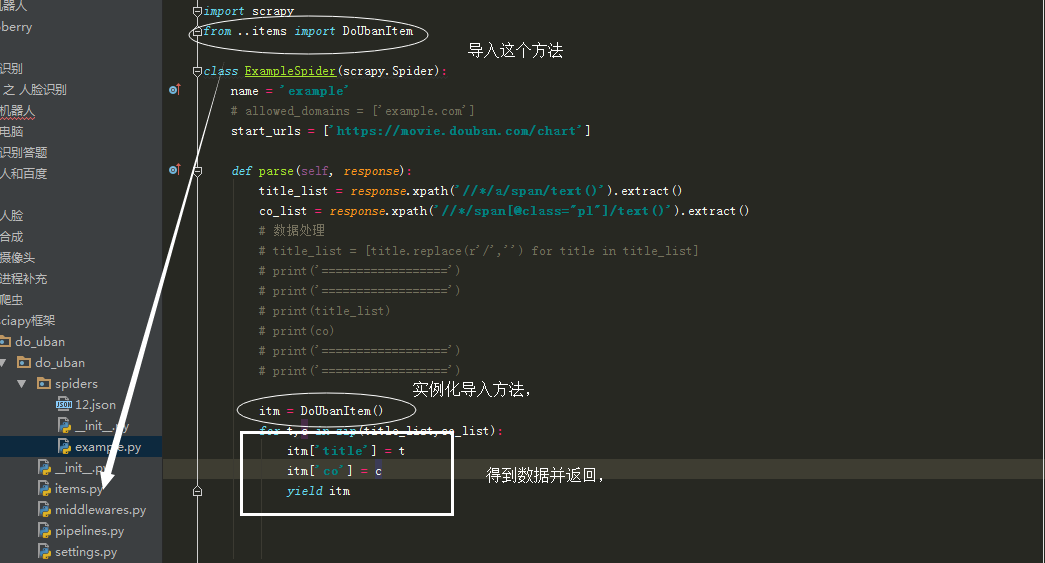
spiders 对整个框架提供最裙的访问连接,同时对每次返回的内容进行解析,再次产生爬取请求,解析 downloader 返回的用户响应,产生爬取向,产生额外的爬取请求
itempipelines 以流水线处理 spiders 产生的爬取向
在 spiders 和 engine 之间还有个爬虫中间件,是对 spiders 产生的请求或爬取向进行再处理







