一丶浅谈导入表
首先,导出表我们已经学过了,作用就是在程序加载的时候,把自己要调用的API的地址,不断地填写到IAT表中
不过我们要知道三个概念,
1.程序运行的时候,导入表直接把调用的API地址填写到IAT表格中
2.程序运行的时候,用到那个API,才会填写到IAT表中(延时加载技术,下面讲解)
3.程序还没运行的时候,在PE中函数的地址就已经写死了.
何为延时加载
我们知道,如果你写的API有几万个,那么一开始就填写到IAT表格中,那么你的程序会很慢.
那么就会使用延时加载表(也是数据目录中的)那么用到那个,才填写.
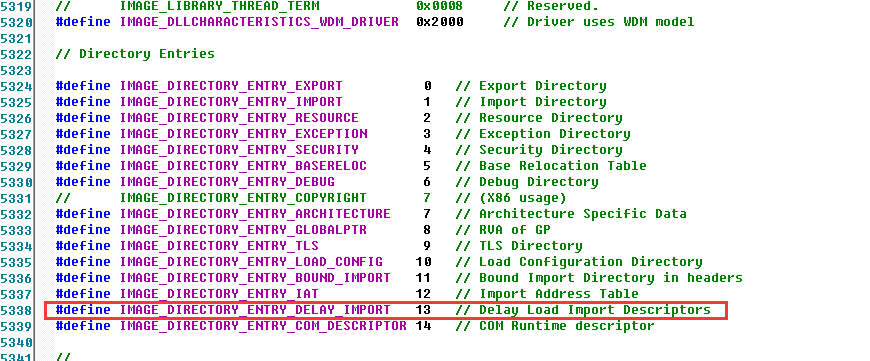
可以查看结构体(数据目录的结构体)下面可以找到这个表格.这个就是延时加载表
二丶何为导出表?
导出表,作用就是我们写的DLL或者EXE导出的函数,那么会记载这些函数.作用就是这个
那么是你自己设计导出表,你要怎么设计.
按照我的思路:
1.我会设计一个 入口地址表(RVA存贮,用来计算模块 + 入口地址的RVA等于函数地址)
2.我还会设计一个 保存函数名字的表
3.我还会设计一个,保存序号的表
大体就怎么多.
设想一下,我们如果要保存一个导出函数,并且还有调用它,是不是需要保存函数名字,但是因为导出的时候还要有序号导出,那么是不是要保存序号,不光保存序号,我们是不是还要通过一定手段让模块地址+偏移寻到函数位置.
表格设计大体流程
EntryPoint 里面保存RVA(入口地址表)
order 序号表格保存序号的
FunctionName 函数名称表
当然,函数导出的时候可能还会有记录个数的
那么看下具体的结构体是怎么样子的吧.
不出意外就会和我们的表设计的差不多.
typedef struct _IMAGE_EXPORT_DIRECTORY { DWORD Characteristics; //标志,未用 DWORD TimeDateStamp; //时间 WORD MajorVersion; //主版本 WORD MinorVersion; //副版本 DWORD Name; //指向导出表文件名的字符串 DWORD Base; //导出函数的起始序号 DWORD NumberOfFunctions; //所有导出函数的个数 DWORD NumberOfNames; //以函数名导出的函数个数 DWORD AddressOfFunctions; // 导出函数地址表RVA(入口地址) DWORD AddressOfNames; // 函数名称地址表RVA(名称表) DWORD AddressOfNameOrdinals; // 函数序号地址表(序号表) } IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
可以看出,确实是差不多的.
那么看下这里的重要成员
1.执行导出表文件名的字符串
2.base 导出函数的起始序号
3.导出函数地址表RVA
4.函数名称地址表RVA
5.函数序号地址表
这里我们随便找个DLL,使用010模版,看下结构到底怎么存储的(先要定位)
三丶定位导出表
1.找出导出表RVA偏移
首先,我们要在数据目录里面查看DLL的第一项,也就是导出表的地址的RVA偏移是多少.
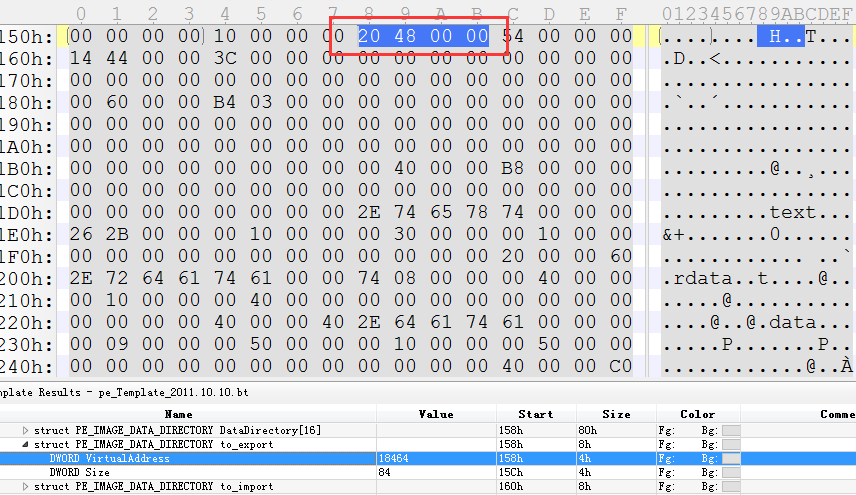
可以看出,是4820的RVA偏移,大小是84个字节
2.判断属于哪一个节
既然知道是4820了,那么节中的虚拟地址肯定是40开头的.小于50的 因为4820 > 40开头, < 50开头
首先第一个节.text

4096代表了1000h,肯定不是,相差太远.
第二个节.radata
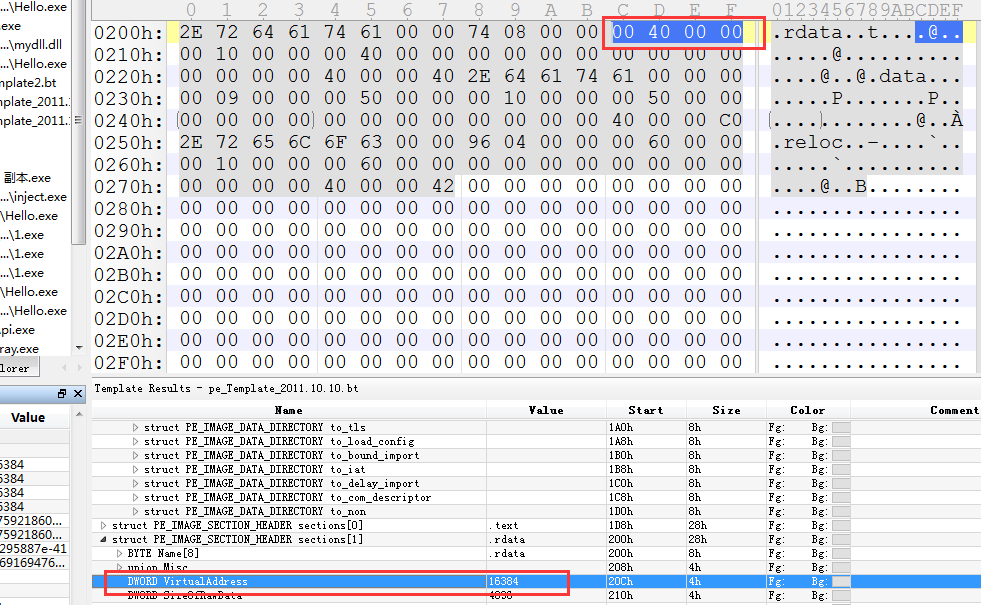
是40开头的,那么就是了
3.算出FOA位置
既然知道是.radata节中的,那么直接算出FOA(简称FA)的位置即可
RVA = 4820
FA = RVA - 节虚拟地址(上面找的4000h) + 上面找的节的文件偏移大小
文件偏移截图:
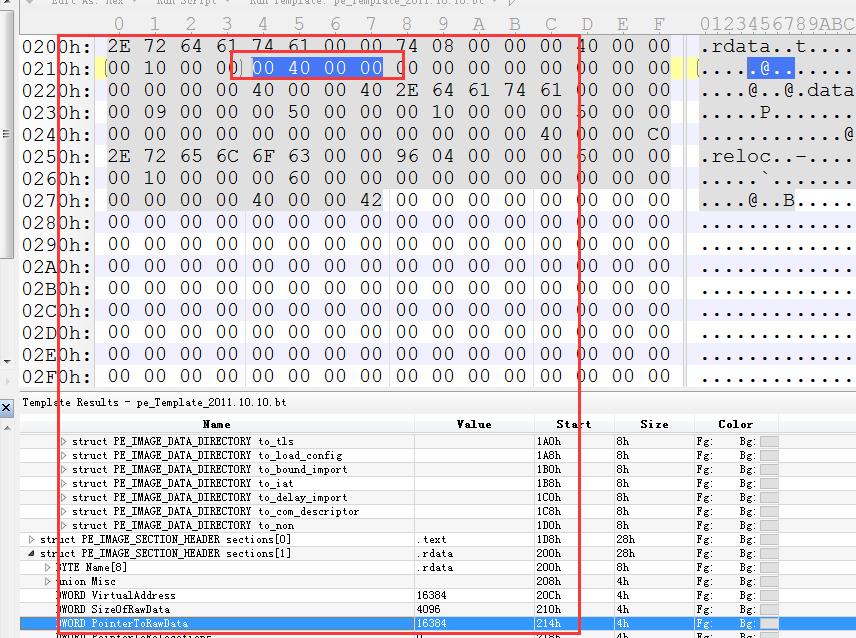
公式代入得到:
FA = 4820 - 4000 + 4000
FA = 4820
通过计算,我们发现还是4820的位置,为什么这么巧?
原因是虚拟地址和文件偏移位置存储都是一样的.所以记录的RVA则是在文件中的位置.
4.通过FA找到导出表位置
我们得到FA是4820,那么我们使用010 Editer中的ctrl + G的功能,快速定位位置.


我们选中了84个字节,那么这84个字节则是导出表的大小了,在数据目录中有记录导出表的大小,所以直接定位即可.
四丶导出表的存储方式
1.第一部分讲解
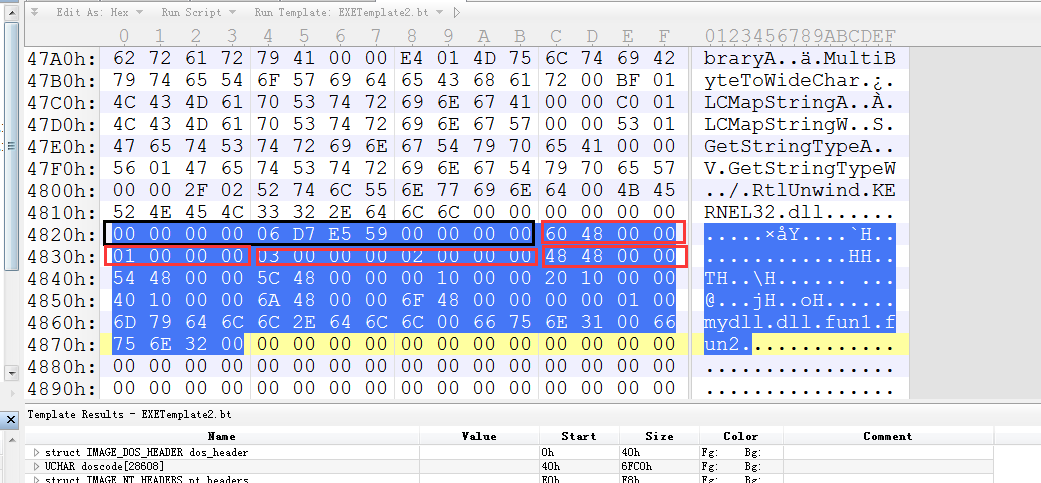
截图一下截取太多,不好讲解,这里截取一部分,下面接着截取4840下面的
首先,黑色方块中的无用不重要,所以不讲解.
红色方块第一个: 成员NAME 这个是一个RVA的偏移,指向了DLL的名称,可以的同学,可以看下4860(因为RVA是4860,但是虚拟地址和文件偏移是一样的,所以现在的情况是FA = RVA,不用转换了)的位置,是不是DLL的名称,以0结尾
红色方块第二个,base成员,起始的导出序号,这个很重要,一会讲解
红色方块第三个,这个我直接把两个4字节弄在一起来,要分开来看, 第一个四个字节,3,表示了所有导出函数是3个(函数名字,或者序号导出都计算)
第二个四个字节: 显示2,表示了按照名字导出的函数有两个.
红色方块第四个: 这个重要了.存放的是函数的地址表.
如果会看FA位置的同学请看. 存放的00001000 第一个函数地址偏移 第二个函数地址偏移 00001020 第三个函数地址偏移00001040
为什么存放的是函数地址偏移,因为这个是个DLL,加载到程序的时候,DLL模块不固定,所以比如存放偏移
这样就可以通过 ImageBase + 偏移,定位导出函数的地址了.
所以现在大家应该知道为什么GetprocAddress(模块,函数名)为什么要给模块了吗? 就是要通过模块+偏移的位置定位导出函数地址调用
2.第二部分讲解
首先,讲解第二部分之前,我们要把第一部分的存储信息截图下来,方便对照查看.
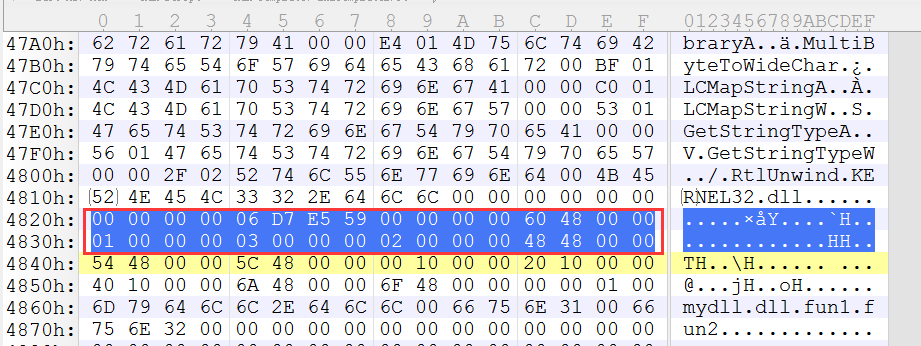
第二部分截图:

可以看出,我画了4个颜色的方框
看法: 黄色对应着橘黄色
深红色,对应着绿色
首先黄色方块: 代表的函数名称的表,指向函数名称的字符串位置 RVA,通过转化(FA = RVA)得出4854的位置是指向字符串的位置.
那么就会指导橘黄色的开头位置了,也就是4854的位置,但是注意一下,因为导出的函数,函数名字是不固定的,那么其实函数名称表执行的这个区域还是一个偏移.
而这个偏移,才真正的指向了函数名称的字符串(注意,0结尾)可边长的.
那么486A的位置就是 导出函数的名称了. 也就是fun1
橘黄色有两个4字节,第一个RVA偏移,是指向了fun1的函数名字,那么第二个就是指向了fun2的名字,那么由此可以得出,按照名字导出,我们总共得到了两个字符串.(fun1,和fun2)
深红色位置:
深红色位置指向了一个偏移,这个偏移也就是绿色方框的开头,分为2个字节2个字节
那么绿色是2个2个字节.
这个深红色位置,就是序号表的RVA偏移,我们知道DLL导出可以是序号导出,那么这个地方就是存储的是序号.
导出函数的时候,默认不写序号,则对应的是从0开始,0 1 2 3顺序排列,这里导出了2个函数,那么对应就有两个序号,分别是0和1
通过上面讲解,基本了解了导出表的存储格式,但是下面的讲解,才会真正的重要.
五丶BASE成员,导出序号,函数导出,以及函数地址表之间的关系
1.函数名称,序号表,以及和函数地址表中的关系
首先我们要知道,DLL的导出函数可以按照序号导出,也可以按照函数名字导出,但是怎么和函数地址表关联起来那?
首先,我们先看不按照序号导出,按照函数名字来获取函数的地址(函数地址表中)
上面我们分析过了
我们会需要函数名字,入口地址,以及序号,而下面的结构体也正好应验了.
那么重新写一下
EntryPoint (可以理解为函数地址表,存放的是导出函数的地址)
那么刚才我们看了,有三个
00001000 fun1的偏移
00001020 fun2的偏移
00001040 fun3的偏移,只不过没有名字
Order 序号表格
0 fun1的默认序号
1 fun2的默认序号
FunctionName (函数名称表格)
fun1
fun2
首先关系是这样的,我们通过fun1的字符串,去查找序号表,通过序号表则找到偏移了.
比如我们要加载 fun1,那么fun1的序号表中默认是0位置,所以找到的序号0了,也就是第一项(注意,序号表可以理解为Switch(序号))然后0位置存放的就是函数地址表,也就是000010000
那么就得出了fun1的RVA偏移了
那么现在知道一个完整的GetprocAddress(模块,函数名)是怎么运行的了吧
首先,模块肯定是要知道的,
函数名字给了,那么去序号表中看是第几项,找到序号表中的对应第几项,那么就去函数地址表中寻得第几项,那么正好就得出偏移了
那么现在模块 + 偏移,正好找出导出函数 fun1的地址了.
2.Base,序号表之间的关系
首先我们重新编译下DLL,这次是按照序号导出

可以看出,我们默认指定的fun1的序号是1,fun2是2,fun3是3
那么为什么序号表中是0 1 2 那?
原因是这样的
1.如果我们通过函数名字查找,比如找fun1,那么序号就是0,也就是第一项,那么通过0就可以找到fun1的偏移了
2.如果我们通过序号查找,比如我们输入3,我们要调用fun3了,那么这个时候,序号表中根本就没有3,怎么办?
此时Base成员的作用就来了,它默认是1,那么我们输入3序号的时候,会减去base的值,得出的下标,再去序号表中查找.
那么3 - 1 = 2,2当做下标去序号表中查找,找到了第三项,也就是02了,通过02找fun3的偏移,也是对的.
所以现在是由两种方式,
第一种就是名字导入,fun1默认不加序号就是从0开始的,去序号表中查0就能找到偏移.
第二种就是专门按照序号导入的,那么此时你输入的序号-base才真正的是函数的偏移了.