目录大纲:
1.全局(静态)对象的识别,(全局静态全局一样的,都是编译期间检查,所以当做全局对象看即可.)
1.1 探究本质,理解构造和析构的生成,以及调用方式(重要,如果不想知道,可以看总结.)
2.对象做函数参数的识别
3.返回值为对象的识别
4.对象为静态局部的识别
5.堆中对象识别
5.1. malloc和new的区别,free 和delete的区别
6.对象数组
6.1, delete对象和 delete[] 对象数组的区别
一丶全局对象的识别
对于全局对象,以及全局变量等等.这些初始化,都是在ininterm中初始化的,和全局变量初始化的位置一样,如果不太懂,请看.以前博客链接:
http://www.cnblogs.com/iBinary/p/7912427.html
建立高级代码,查看其调用栈.(最后会总结)
高级代码:
class MyTest { MyTest(); ~MyTest(); }; MyTest::MyTest() { printf("111 "); } MyTest::~MyTest() { printf("222 "); } MyTest test(); //创建对象在全局 int main(int argc, char* argv[]) { return 0; }
查看调用栈回朔:
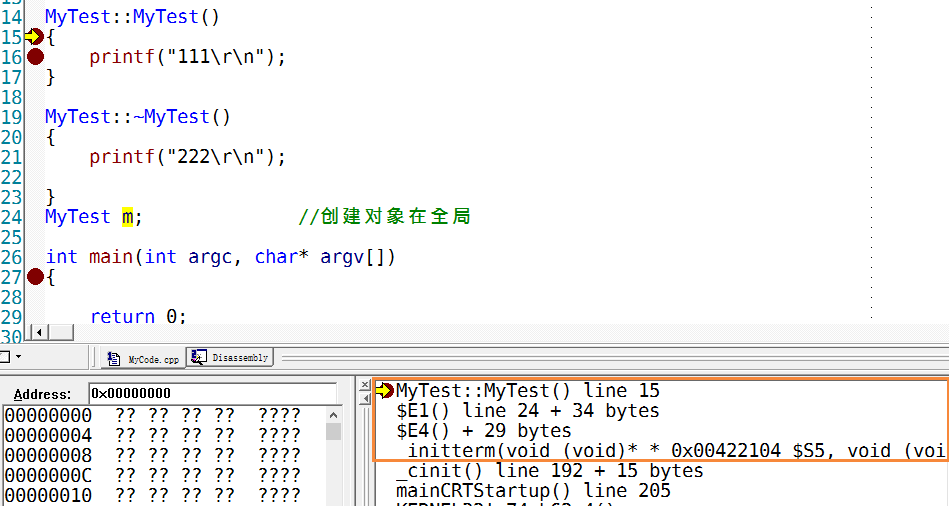
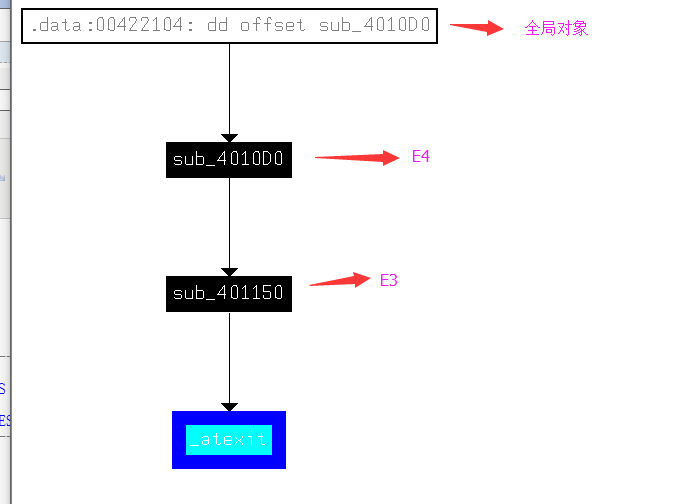
调用栈的顺序依次是
initterm -> E4(代理) - > E1(代理) ,熟悉完探究原理和本质的时候再来讲解E4 和E1代理是干啥用的.
1.1探究原理,追求本质.构造和析构的生成,构造的调用和析构的调用
1.熟悉 ininterm原理
我们以前讲过 ininterm函数里面的原理和本质(不熟悉看下方图)它会根据函数的起始和结束地址,循环遍历并且调用同一接口的函数进行初始化动作.
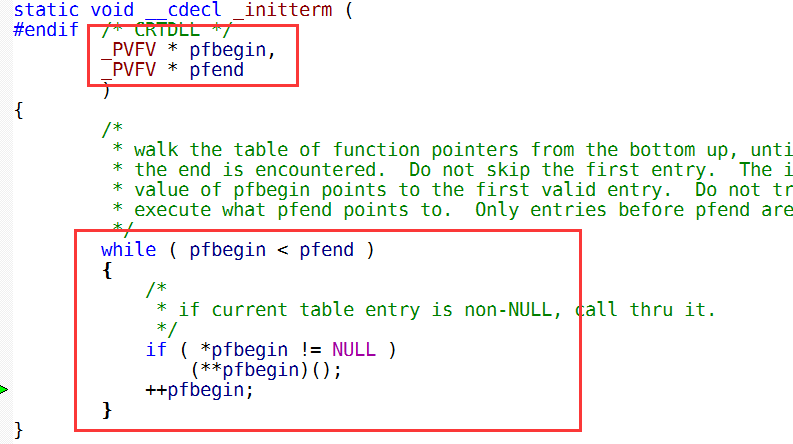
那么现在E4代理函数就是统一接口的,也就是说, ininterm函数循环的函数指针调用,都是调用E4代理函数
2.熟悉构造函数何时调用,E1代理, E3代理函数.
现在我们知道了ininterm函数为了统一接口,所以弄出来了一个E4代理函数,为了统一接口
E4代理函数内部:
那么E4代理里面做了什么事情.
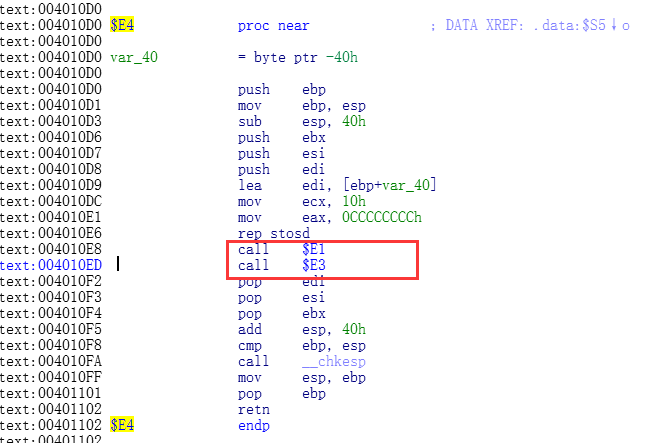
可以看出,E4代理里面调用了E1代理和E3代理
关于E1代理,我们知道,它是为了统一参数而生成的一个代理,其内部调用我们的真正代码,(也就是构造函数)
E1函数代理内部
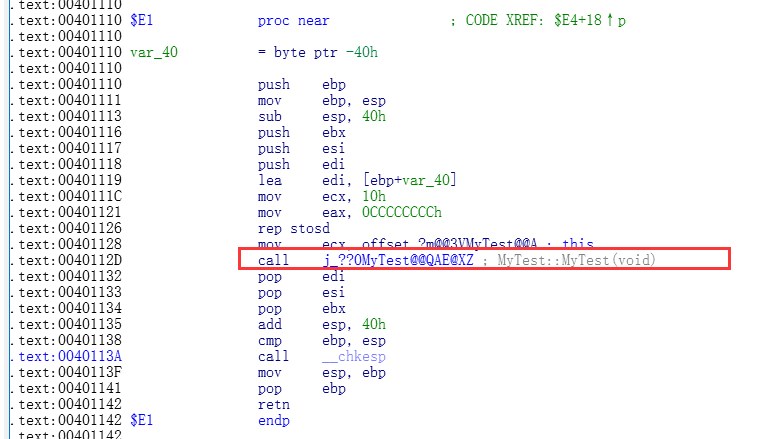
E3代理,E3代理稍后讲解,我们要知道E3是干什么用的要先知道一个C库函数的作用.
3.E3代理内部,以及C库函数作用
C库函数,atexit 注册函数回调,main函数结尾的时候进行收尾动作(也就是释放资源的动作)
这个C库函数在C语言时代就是释放资源的.
看下MSDN声明.

注册一个C约定的函数回调即可.看下程序例子:
高级代码:
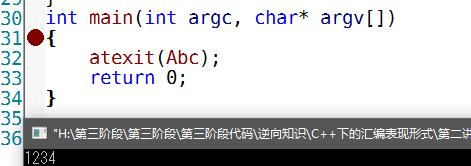
void Abc() { printf("1234 "); } int main(int argc, char* argv[]) { atexit(Abc); //注册 C约定函数指针,当main函数结束的时候操作系统调用这个函数. return 0; }
运行程序结果
正文:
atexit可以注册多个回调,而这些会是一个线性表,里面储存了你注册的函数地址.当main函数结束的时候会调用

而内部

do exit函数内部会执行核心代码:

代码含义,一开始没有注册的时候, 线性表的头和尾都是一样的位置
当你注册了那么线性表则会增加4个字节存储你注册的函数回调地址.
可以看出上面代码逻辑
从后往前调用,执行函数指针, 而这个函数则是你注册的函数回调.
E3代理含义:
明白其上面的 atexit函数的原理,那么现在看看其E3内部的实现
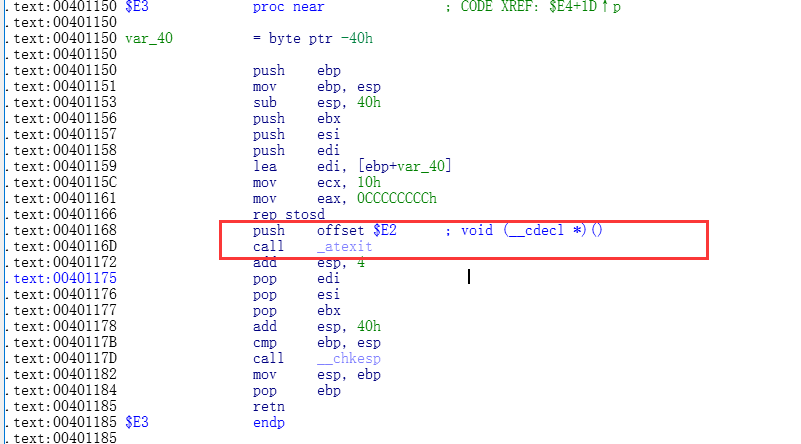
E3内部其实是将E2函数注册进了atexit函数,当结束的时候则会调用E2
那么现在看看E2
E2函数内部:
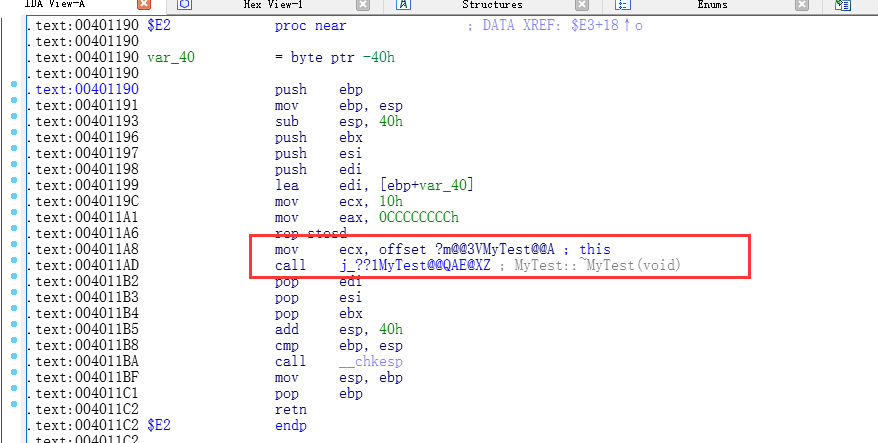
E2函数内部则会调用析构函数,有人会说,为什么不直接将析构注册为函数回调,这样直接调用atexit不就在释放的时候,从后往前依次调用析构的了吗.
答:
因为atexit的参数的c约定回调,而析构是thiscall,调用约定,所以内部必须包含一层才可以.
总结:
当为全局对象的时候
1.会在ininterm里面进行初始化动作
2.会产生代理函数,这个代理函数是为了使ininterm函数的代码正常初始化而产生的一个统一接口的函数,暂且称为E4 (名字可能不一样)
3.E4函数代理是为了统一接口,其内部又调用了 构造函数代理 (E1),和析构函数代理(E3)
4.E1代理函数是为了统一参数用的,其内部是调用构造的,如果是有参数构造,则在E1代理函数内部可以看到传参的.
5.E3代理函数是为了注册析构函数的,为了使atexit函数正常运行而注册的(atexit和ininterm类似,一个从前往后,一个从后往前)
6.E2是E3内部给atexit函数注册的回调,这样在析构的时候则调用E2即可.
7.E2函数内部是真正的调用析构的.
调用流程图:

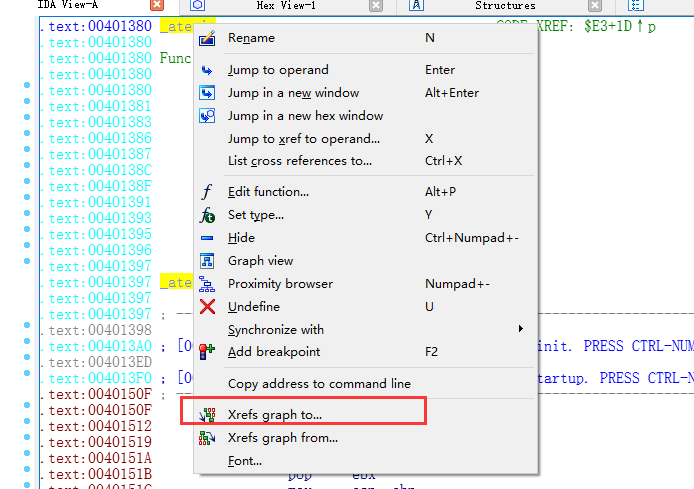
实战中反汇编查找全局对象
既然我们知道了atexit函数会调用析构,那么我们在IDA中搜索atexit函数,看看谁引用了它,则可以把全局对象一网打尽.
二丶对象作为函数参数的识别
高级代码:
PS: 为了节省篇幅,类的定义不在重复截图,重复定义了.
void foo(MyTest test) { printf("333 "); } int main(int argc, char* argv[]) { MyTest t; //定义对象 foo(t); //对象当做参数传递 return 0; }
Debug下的汇编:

很明显的特征
1.函数调用前会调用一次构造
2.调用函数
3.函数结束之前调用析构. (foo函数内部,为了节省篇幅,和Release)
4.函数结束之后继续调用构造
Release版本汇编:
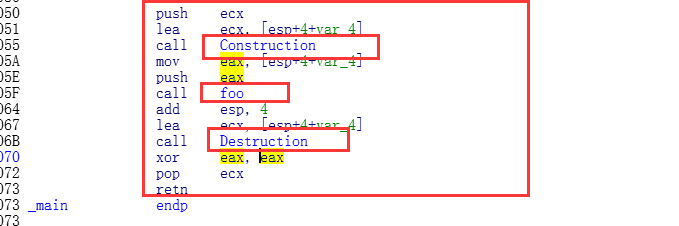
上面包含了 1 2 4步,其中第三步是在 foo函数内部调用的析构
foo 函数内部
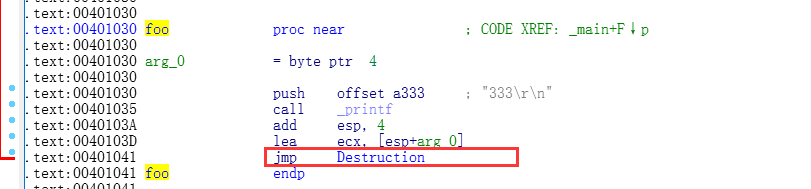
内部会有个Jmp来调用析构
总结:
当函数参数为对象的时候.
1.会先在函数外部进行构造一次
2.调用函数
3.函数内部调用一次析构
4.函数结束之后的外面调用一次析构函数.
PS: 注意,局部对象和传参的区别,局部对象会在函数内部进行调用构造,而传参的时候是在函数外面进行的初始化动作
三丶返回值为对象的识别
当返回值为对象的时候,会有两种情况
1.定义的时候产生拷贝动作
2.使用的时候产生临时对象
例如:
MyTest t = Getobj(); 定义t的同时,接受Getobj返回的对象,则会产生拷贝构造
t = Getobj(): 定义完obj然后使用t接受Getobj()则会产生临时对象.不产生拷贝构造
以上都是C++语言,不熟悉的同学复习一下构造析构以及拷贝构造的内容即可.
1.拷贝动作的时候其返回对象的识别.
高级代码:
MyTest Getobj() { MyTest obj; return obj; } int main(int argc, char* argv[]) { MyTest t = Getobj(); //定义同时,接受返回对象 return 0; }
Debug下的汇编代码:
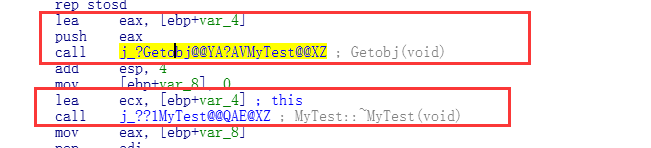
1.调用的时候,当做参数传递给Getobj
3.函数结束之后调用析构
2.函数内部调用构造和析构
(其中2在Getobj里面,看Release版本)
Release下的汇编
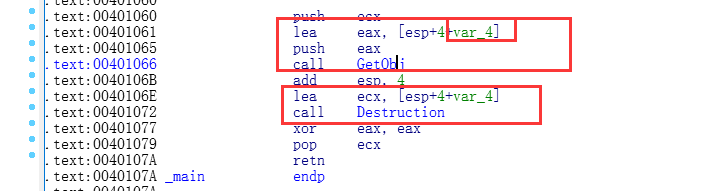
上面是第一步和第三步
第二步函数内部:

其内部调用构造和析构
总结:
1.this指针会当做参数传递给函数, Mytest t = Getobj() t会当做参数传递
2.其函数内部开始的时候会调用构造函数,结束之前调用析构
3.函数结束之后,外部会调用析构函数.
PS: 当代吗为引用的时候,其作用域跟着引用走 Mytest &t = Getobj();
2.使用的时候产生临时对象的情况下
高级代码:
MyTest Getobj() { MyTest obj; return obj; } int main(int argc, char* argv[]) { MyTest t ; t = Getobj(); //定义完毕之后使用 return 0; }
Debug下的汇编

1. T变量进行构造
2.产生临时对象,调用GetObj, 其中Getobj内部会构造和析构,然后返回临时一般来那个
3.返回的临时变量给栈变量保存,然后 mov edx,[ecx] 给edx赋值
4.临时变量拷贝给t
5.临时变量析构
6.main结束前局部变量析构
Release下的汇编

Release汇编和Debug一样,减少了变量,进行了优化.
总结:
使用时获得对象则产生临时对象
1.局部对象进行构造
2.调用函数的时候产生临时对象,其内部产生构造和析构
3.返回的时候返回值给使用的对象赋值
4.临时对象析构
5.main结束时局部对象析构.
MyTest Getobj() { MyTest obj; return obj; } int main(int argc, char* argv[]) { MyTest *t ; t = &Getobj(); //定义完毕之后使用 t->m_dwNumber = 1; return 0; }
Debug下反汇编
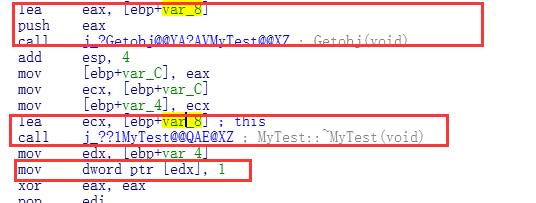
我们会发现
返回的临时对象会给t保存
但是紧接着析构了,但是此时指针调用了临时对象里面的成员,并且给它赋值了.所以以后写代码要注意,这种错误编译器检测不出来.虽然支持这个语法.但是肯定会出错,而且是莫名其妙的错误
四丶对象为静态局部的识别
高级代码:
int main(int argc, char* argv[]) { static MyTest t ; return 0; }
Debug下的汇编
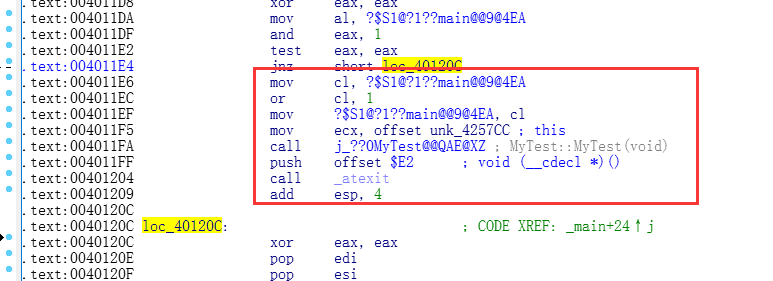
会生成一个检查标志,根据这个标志判断,是否调用构造和析构
会跳过一个 构造和注册析构的一块区域
总结:
生成检查标志,跳过构造和注册析构代理.
五.堆中对象识别
高级代码:
MyTest *t = new MyTest ;
Debug下的汇编:
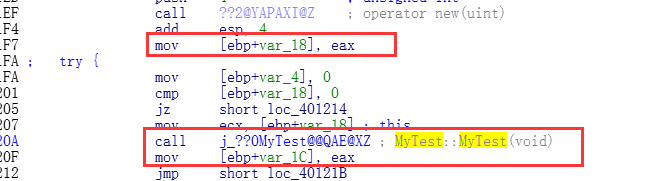
new 和malloc是一样的,new是对malloc的一个封装. 只会申请空间,但是会产生额外的代码,中间会判断标志,申请成功的返回值为0或者为1,如果为0则不构造,如果为1则构造
但是注意:这里的额外代码只是判断是否进行构造,你自己也要进行判断.
Delete语法
Delete语法会调用析构,也会生成额外语法.

当Delete的时候会传入1, 这个是按位来的, 如果最低位为1,则是代表释放内存,那么就调用析构并且释放,如果为0,则仅仅代表了调用析构.
为什么会这样:
在早期,硬件资源匮乏,内存想重复利用.
所以会有人显示的调用构造(vc6.0中可以)然后显示的调用析构进行管理,示例:
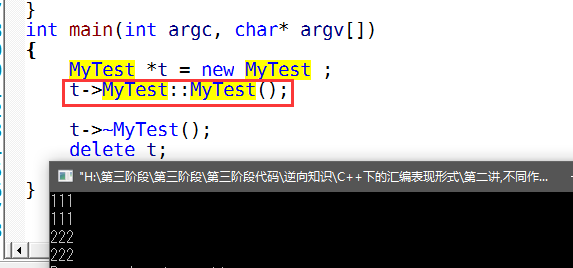
加上类域则可以调用构造了,那么析构我们是显示调用,所以看看汇编代码,会传入0,不会释放内存的.

总结:
1.new 和malloc 一样,new是对malloc的一个封装,但是会产生额外代码,用来判断是否进行构造
2.delete的时候,会传入0 和1来判断是否是调用析构并释放内存(1) ,或者只调用析构(0)
转载于:
作者:IBinary
出处:http://www.cnblogs.com/iBinary/