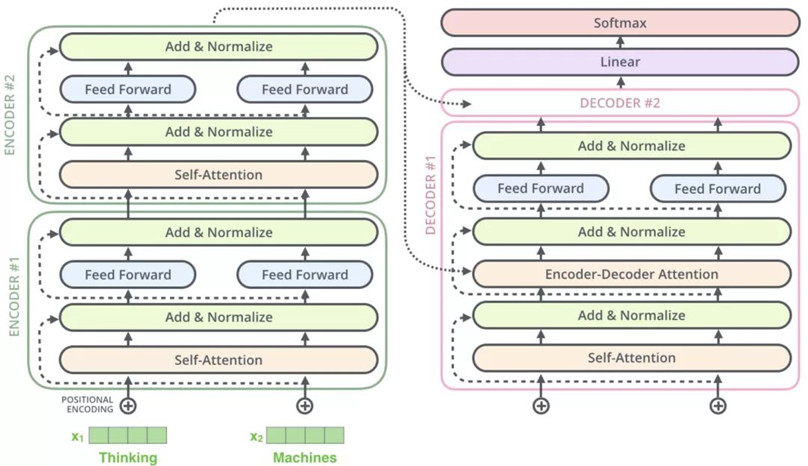
一、transformer的架构图
主要分为两大块,Encoders和Decoders,两块分别由6个Encoder和Decoder组成。其实Encoders的功能就是抽取特征的,抽取出来的特征就交给Decoders,Decoders用Encoders抽取到的特征去做具体的任务,类比到常见的机器学习任务,也是这么回事,先做特征,然后由特征去做分类、回归等任务。
二、单个Encoder详解
架构图左边的Encoders由6个Encoder组成,每个Encoder里面都包含一样的网络结构,主要由Self-Attention、Feed Forward、ResNet&Layer Normalization组成。
1、Self-Attention主要做了什么?
self-attention在Encoder中首先计算的是Q*K,即词与词之间的相似度矩阵,然后根据相似度(包括与自己的相似度)与V相乘,最后每个词形成带注意力的词向量。直观理解就是,每个word最终的词向量都是由与之相似的一系列词加权求和构成的,相似度越大,贡献度就越高,反之就贡献度小。注意在做Attention的时候会把每句话pad的部分都置为0来mask掉,因为本身这部分就是为了句子对齐而补的,不参与计算,称之为Padding Mask。
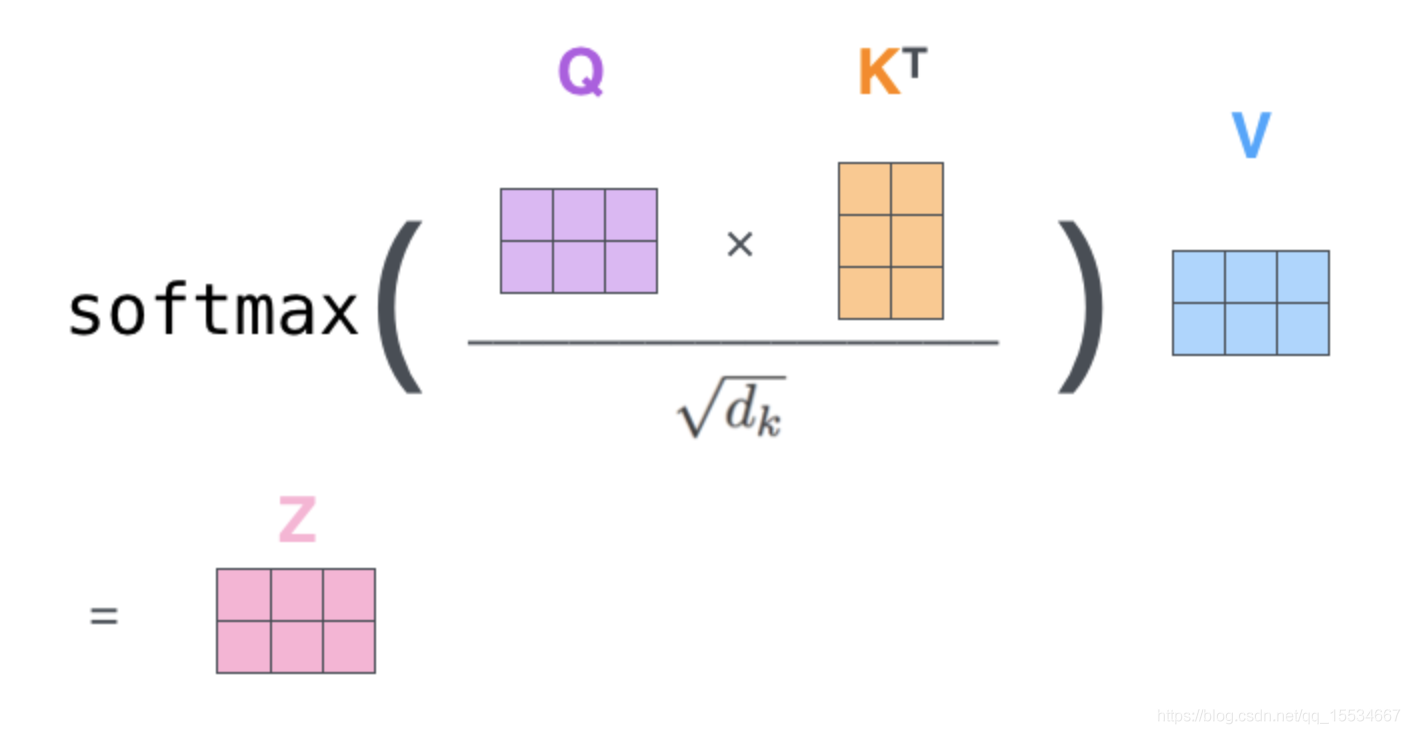
至于为什么要除以√dk,是因为如果数值过大,进入softmax后的概率分布会集中于一个位置,其它位置的概率基本都接近0,如此一来反向传播的时候导数基本都为0,模型无法学习。详细参考:深入理解softmax函数
2、为什么Self-Attention会有效,而不使用普通全连接呢?
首先,self-attention与普通的全连接相比,其获得的是动态的权重。全连接中的权重参数,对所有的样本都是固定的;attention模式下,不同的样本其权重是不一样的,这里的权重就可以理解为上述的相似度分数,这个权重分是根据样本中词与词之间的相似度计算得出的,所以是动态变化的,而且能够把句子中词与词之间的关系直观反映出来。
其次,全连接和attention机制的作用对象也不一样。全连接作用的是将一个实体从一个特征空间到另一个特征空间的映射,是单个实体内部的挖掘,比如NLP中就是把某个512维度的词向量映射到2048维度而已,但个词不同特征维度的组合映射转换等操作;而attention模式则是对来自同一个特征空间的多个实体进行整合,比如一句话中多个词之间根据关系进行加权组合,每个词的维度都还是512维不变。
最后,因为attention的这种关注词与词之间的关系,而且越相似的词,其词向量也比较接近,使得一个句子中无关紧要的词其表征就会弱一些,而越重要的词及其相似的词表征就更凸显一些,这就叫做近朱者赤近墨者黑,与强手做朋友,自己也变强了,然后整个句子就聚焦到了重要词上。如果采用普通全连接可能也能做到,但是训练会很费劲,难以收敛;而Attention把关注局部信息这一重要部分单独进行设计,减少了整个网络的压力,使网络无需在输入特征的重要程度上下功夫,易于收敛。简单来说,把网络看成你在做作业题。当你读题和解题的时候,会对题目描述的不同部分进行不同程度的关注,然后进行解题。但如果有人进行了题干分析,让你直接了解了题目描述哪些部分更重要时,那么做对的几率就会高好多。
3、Feed Forward主要起什么作用?
feed forward是两层的full-connection层,中间隐藏层的输出维度为dff=2048,这里还要加入全连接的原因大概如下:
Multi-Head Attention的结构中主要进行的都是矩阵乘法,都属性线性变换,而深度学习更重要的一点就在于非线性变换,非线性变换的学习能力强于线性变换,因为它能够学习更复杂的数据模式。
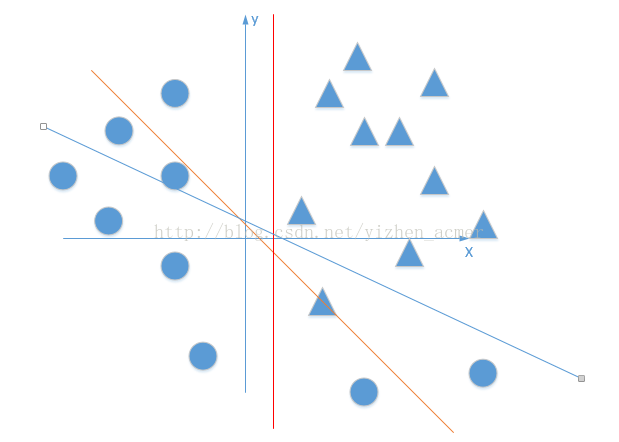
图1)线性直线无论怎么旋转,都不能完全将三角形和圆形分开。 图2)加入了激活函数后,就可以将线性变成非线性,就能够分开了。
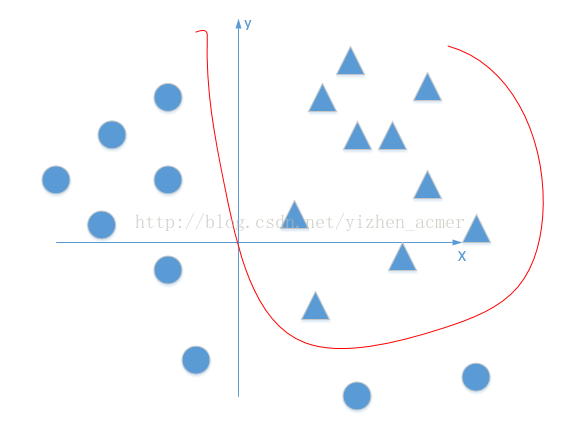
所以,虽然通过Attention机制每个word都学习到了新的representation,但是其表征能力并不强,可以通过激活函数实现非线性变换,增强其表达能力。激活函数可以使得数值较大的部分得到加强,数值较小的部分进行抑制,从而使得相关部分表达更好。
同时,在Attention机制后面加了LayerNorm使得数值都标准化到了激活函数的作用区域,让Relu更好地发挥作用。
最后,Feed Forward层先将数据从低维(512维)映射到高维空间(2048维)再映射回低维(512维),可以学习到更加抽象的特征,使得单词的representation表达能力更强,更合适的表示word和context中其它word之间的关系。
4、Layer Normalization
在transformer中,每一个子层(self-attetion,Feed Forward Neural Network)之后都会接一个残差模块(ResNet),并且有一个Layer normalization。Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。
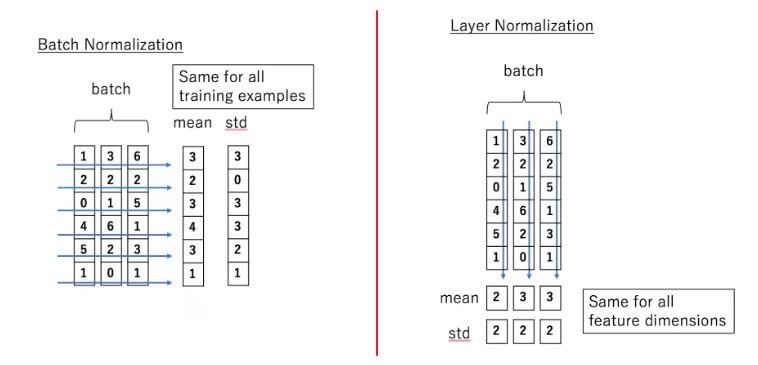
在CV中常用BN进行归一化,而NLP中同一batch的不同样本之间并没有信息关联性,做归一化没有意义,而且由于不同的句子长度不同,强行归一化反倒会损失样本之间的差异性,所以NLP中常选用LN进行归一化,只考虑同一句子内部的归一化。可以认为NLP场景中一个样本内部的维度是相互关联的,所以在信息归一化时,能够把一部分不重要的复杂信息损失掉,让整个分布更加平稳,减少内部之间的差异性,这样既能加速模型收敛,又能降低模型的方差。

详细可以参考:transformer 为什么使用 layer normalization
5、为什么需要Multi-Head注意力机制呢?
以 【The animal didn't cross the street because it was too tired】这句话为例子,这里的it在句子中指代什么呢?


当我们在编码器#5(栈中最上层编码器)中编码“it”这个单词的时,注意力机制的部分会去关注“The Animal”,将它的表示的一部分编入“it”的编码中;然而另外的head中“it”的注意力就聚焦到了“tired”上面。所以最后,当我们编码“it”一词时,一个注意力头集中在“animal”上,而另一个则集中在“tired”上,从某种意义上说,模型对“it”一词的表达在某种程度上是“animal”和“tired”的代表,这就是Multi-Head的作用。
三、单个Decoder详解
Decoder与Encoder在结构上有一些变化,主要有如下几部分组成:
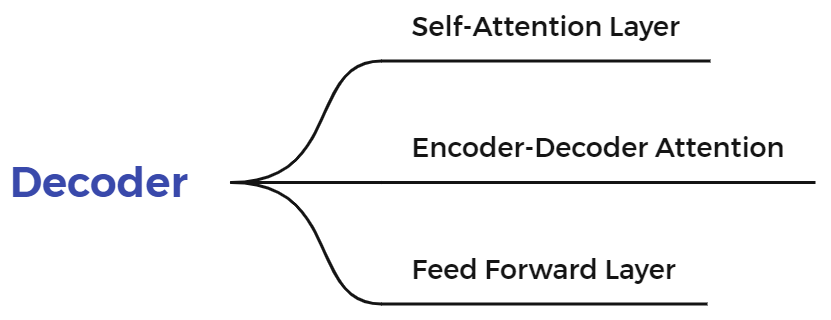
1、Decoder中的Self-Attention与Encoder有什么区别?
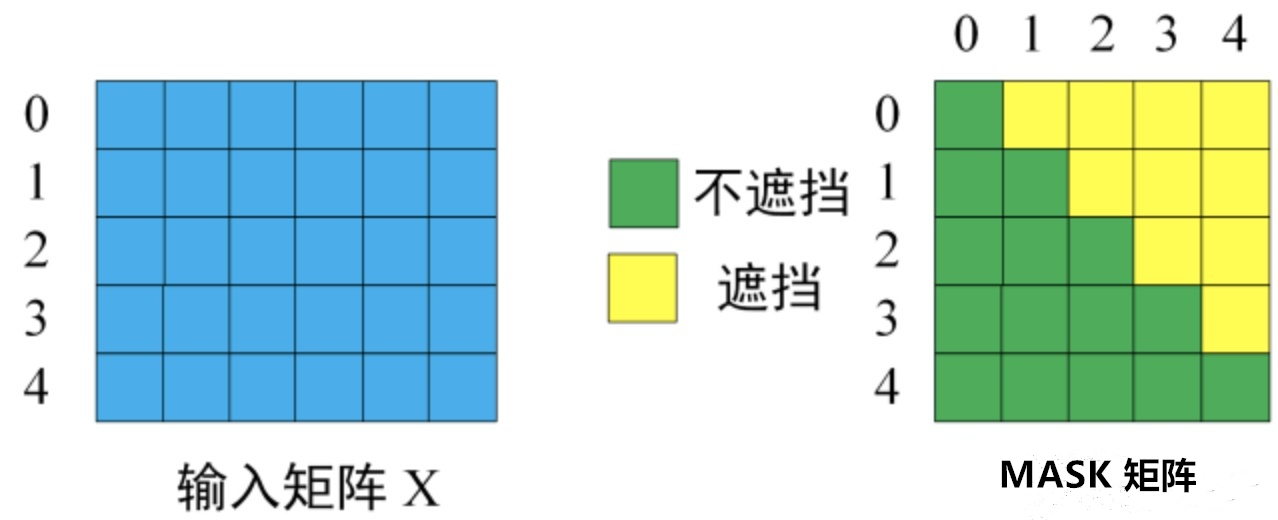
Decoder中采用的是Mask Attention,也就是一句话中左边的word看不到右边的word信息,这是因为在真实翻译的场景中也是word by word依次翻译出来的,在翻译当前词的时候肯定是不知道下一个翻译词是什么,所以在模型训练的时候就mask掉右边的信息让模型去学习,称之为Sequence mask。具体如何实现呢:
假设target序列有m个token,那么可以构建m*m的矩阵,以主对角线为界,上三角的元素设置为-INF,这样在后续的softmax中其attention值趋于0,做到了mask的效果,并且mask操作是在计算出Q,K点积之后,softmax之前。
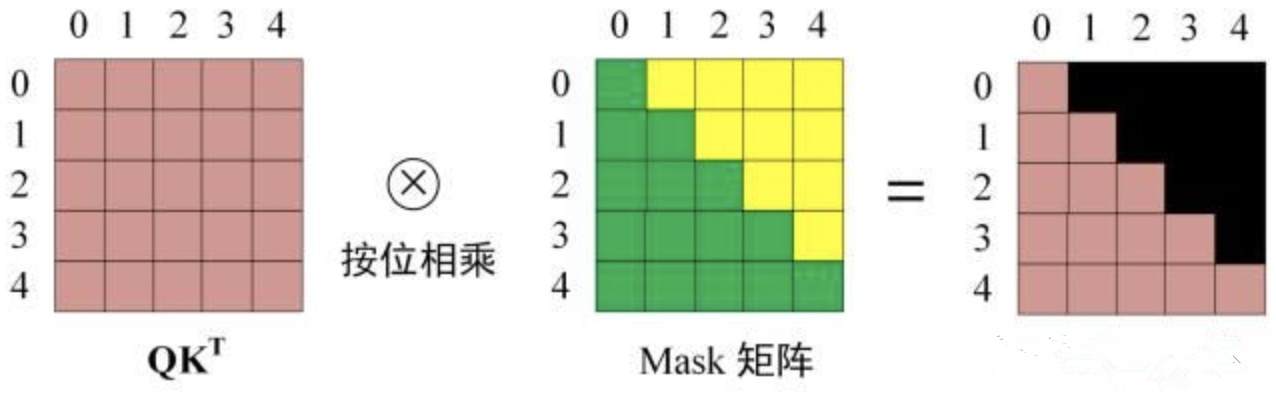
这里最后同样也会把每句话pad的部分都置为0来mask掉,即Padding Mask,与Encoder的操作一致。
2、Encoder-Decoder Attention是怎么计算的?其可解释意义又是什么?
这里的Query来自Decoder中self-attention的输出,Key和Value都是来自Encoder中的最终输出值即Key=Value。
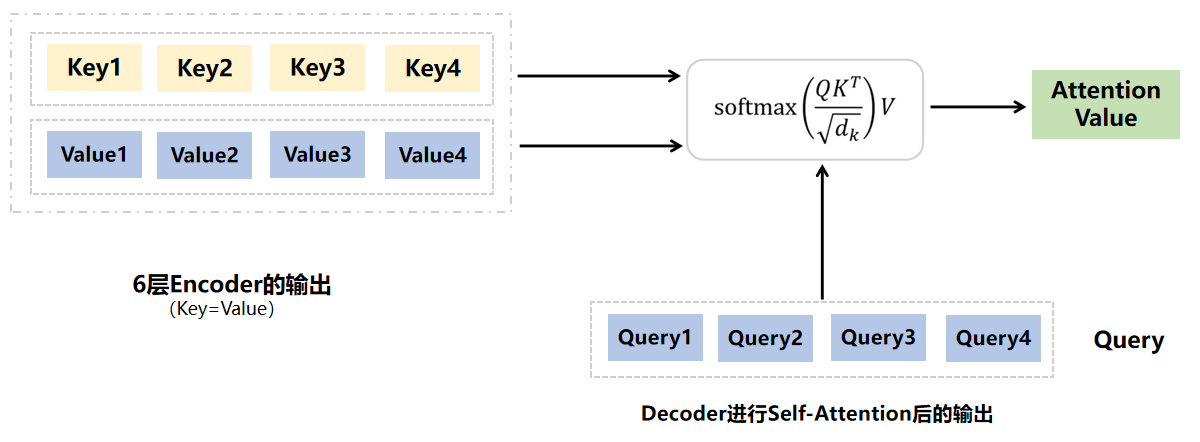
其可解释意义就是,Encoders的最终输出就是利用原始输入经过6层Encoder抽取的特征,然后利用这些特征去做具体的场景任务,比如这里的翻译场景,但是翻译都是word by word进行的,所以在每次翻译当前word的时候,都需要利用已翻译word的信息与Encoders抽取的特征进行attention计算,这样就能使得抽取出来的特征进行动态变化,每次翻译的时候聚焦不同的部分,达到精准、快速收敛的目的。所以,归根结底来看,最终所使用的的特征还是Encoders里抽取出来的特征,decoder的输入只是让这些特征进行动态聚焦。
四、图示训练过程
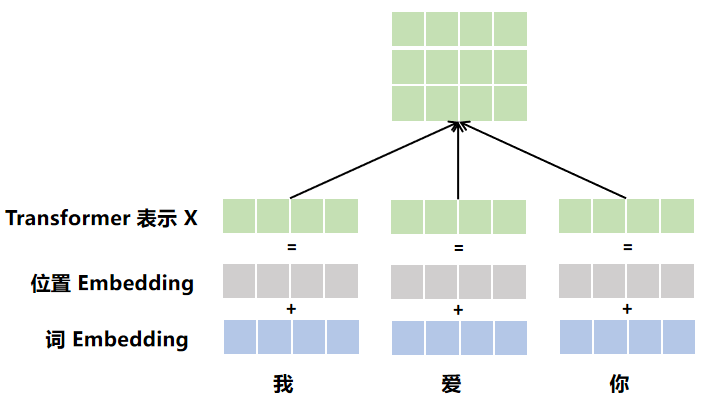
1)构造transformer的输入矩阵X
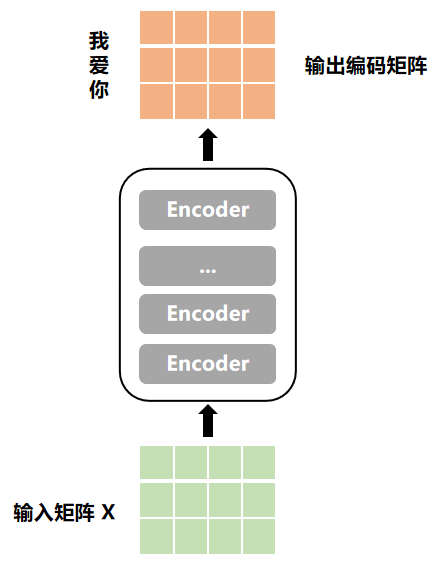
2) Encoders进行编码
3)Decoder进行预测
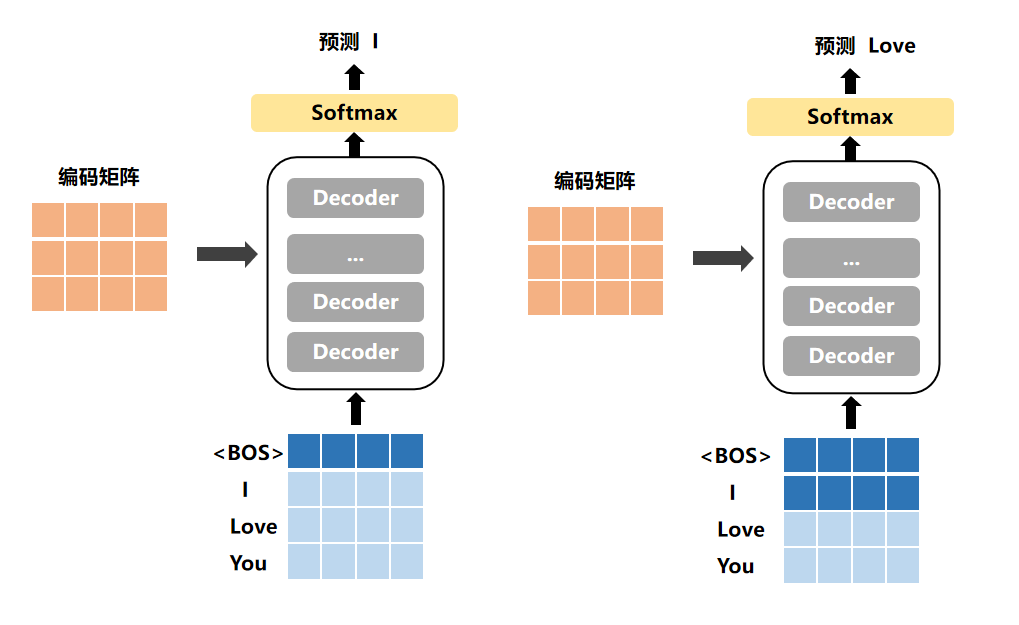
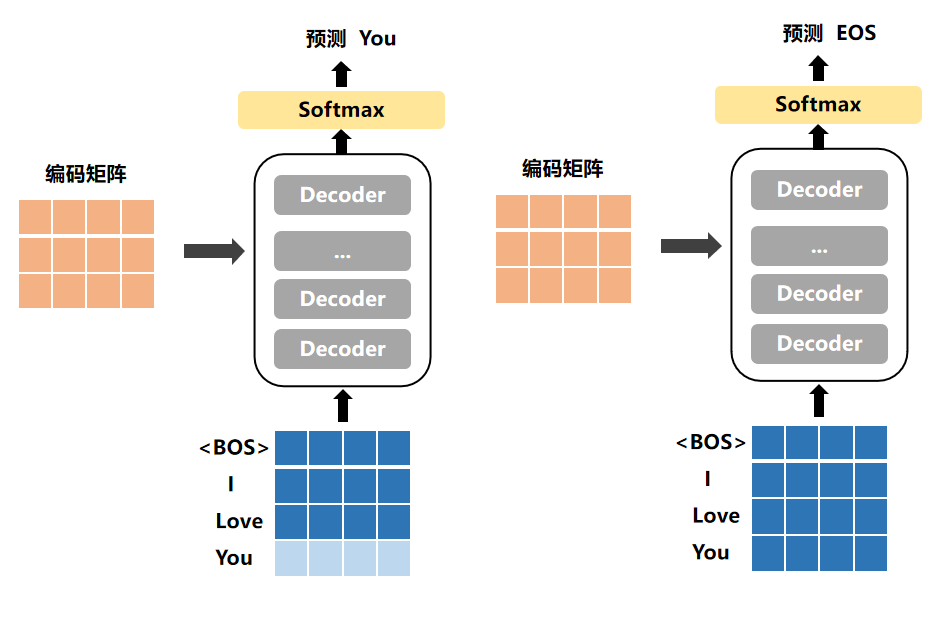
在机器翻译中,例如要翻译的是【我爱你】→【I Love You】,首先会对X和Y 两段分别补上【BOS】和【EOS】代表句子的开始和结尾,那么构建的样本为:
X=【BOS,我,爱,你,EOS】
Y=【BOS,I,Love,You,EOS】
所以,Transformer的输入input=X,然而Decoder的输入input=【BOS,I,Love,You】,其要预测的y值就是【I,Love,You,EOS】,所以最后计算loss的时候,是y和Y[1:]计算,参照上述Decoders预测过程。
参考:https://cloud.tencent.com/developer/article/1589988