一、概述
Albert是谷歌在Bert基础上设计的一个精简模型,主要为了解决Bert参数过大、训练过慢的问题。Albert主要通过两个参数削减技术克服预训练模型扩展的障碍:
- 1、Factorized embedding parameterization(embedding参数因式分解),将大的词嵌入矩阵分解为两个小的矩阵,从而将隐藏层与词典的大小关系分割开来,两者不再有直接关系,使得隐藏层的节点数扩展不再受限制,后面会详细介绍。
- 2、Cross-layer parameter sharing(跨层参数共享),这样就可以避免参数量随着网络的深度增加而增加。
两种技术都显著降低了参数量,同时不对其性能造成明显影响。Albert配置类似于Bert-large级别的,但参数量减少了18倍,训练速度提升了1.7倍。同时参数削减技术还扮演了正则化的角色,有力增强了模型的泛华能力。
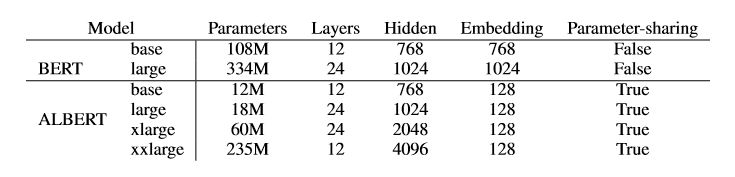
其实Albert共做了三大方面的改造,除了上面两项参数削减技术之外,还有句间连贯性损失(Inter-sentence coherence loss),不同于NSP(next sentence predict)任务,本次任务为sentence-order predict (SOP),下面会分别详细介绍Albert这三项改造。
二、Albert的三大改造
1、Factorized embedding parameterization(Embedding参数因式分解)
这里我们设定词的embedding size用E表示,隐藏层的大小用H表示,在Bert、XLNet、RoBERTa中E≡H的,即两者永远相等的。但是这种设置,无论从模型角度还是实用性角度考虑,都是欠优的,原因如下:
1)模型视角
词嵌入训练是为了让模型学习到上下文无关的向量,也就是最后生成的向量不仅仅局限于某一片段的上下文语境中,而是能够从本质上代表本词的全局语境;而bert的隐藏层学习学出来的是上下文相关的向量,最终一层层学出来的词向量正是为了能够最大限度结合当前训练文本的语境,与当前文本片段语境越贴切越好。所以,类似于bert这种预训练模型,可以将E和H分别设定更好,这样H可以设置的更大,能够包含更多的信息,甚至可以根据需要设置H>>E。
2)实用视角
NLP中的字典大小V通常是非常大的,例如bert的V=30000,如果E≡H,增大H,那么词嵌入矩阵VxE也将变得非常大,将导致产生数十亿的参数,并且在反向传播中,更新的都是比较稀疏的值。
解决方案
所以,综合上述两点,Albert采用了一种因式分解的方法来降低参数量,通过把E和H分开设定,这样就把原来的VxH大矩阵变成两个小矩阵,参数量将从O(VxH)变成O(VxE+ExH),当H>>E的时候,参数削减更加明显。例如:V=30000,E=128,H=768,则原参数量V*H=30000*768=23,040,000,削减后V*E+E*H=30000*128+128*768=3,938,304,参数变成了原来的1/6。
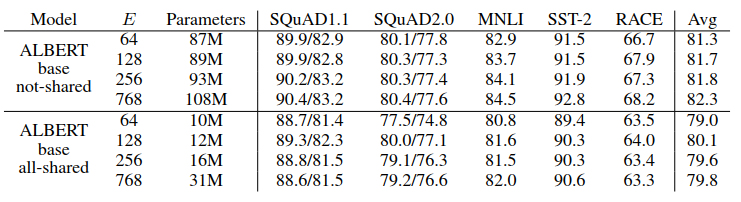
从上述ALBERT-base(参数配置参考最上面的配置)实验数据可以看出,在跨层参数没有共享的一组,E越大,表现效果越好,但是并没有区别特别大;在下面参数共享的一组,E=128一组似乎表现的是最好。综上所述,后面的实验都采用E=128的配置。
2、Cross-layer parameter sharing(跨层参数共享)
Transformer中可以共享全连接层,也可以共享Attention层参数,但是albert选择共享了所有层,也就是12个encoder都用一样的参数,再次大幅减少参数量。论文中作者对比了输出向量在L2距离和相似度的计算,发现Bert的结果更加震荡,而Albert的结果比较稳定,可见参数共享有稳定网络参数的作用(参数变化大,必然引起最终输出结果变化大)。
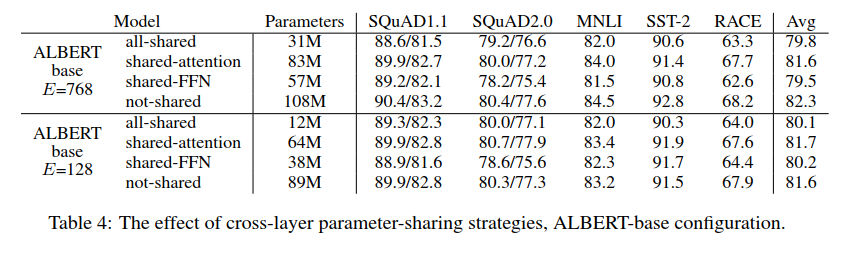
实验采取E=128和E=768两种情况分别进行对比分析,从实验数据可以看出:
- 参数共享后都会降低模型的表现,但是E=128的时候,对模型的损害相对较小一些。
- 两组数据都出现FFN层参数共享后,模型效果出现了较大波动;而attention层的参数共享后,模型表现却变化不大。
- 如果将L层分层N组,每组大小为M,仅仅组内进行参数共享,实验结果显示M越小,模型表现越好,但是参数也越多。极端情况每一个encoder就是一个小组,就相当于不进行参数共享了。
3、Inter-sentence coherence loss(句间连贯性损失)
Bert使用的NSP损失,预测两个片段在原文中是否连续出现的二分类损失,但是最近的研究都表示NSP的作用不可靠,究其原因主要因为该任务缺乏难度。因为NSP其实就是同一主题的预测,相比连贯性预测更容易,而且可能与MLM任何存在学习重叠情况。
Albert提出一种的句间连贯性预测任务,称之为sentence-order prediction(SOP),正负样本表示如下:
正样本:与bert一样,两个连贯的语句
负样本:在原文中也是两个连贯的语句,但是顺序交换一下。
SOP因为正负样本都是在同一个文档中选的,只关注句子的顺序而不考虑主题方面的影响,所以这将迫使模型在话语层面学习更细粒度的区分。并且通过实验发现,SOP能解决NSP的问题,但是只学习NSP的模型却不能解决SOP的任务
三、去掉dropout实验
实验发现在largest模型上训练1M步后,模型仍然没有过拟合,前面也提到过参数修剪可以有效防止过拟合,所以实验决定对比去掉dropout:
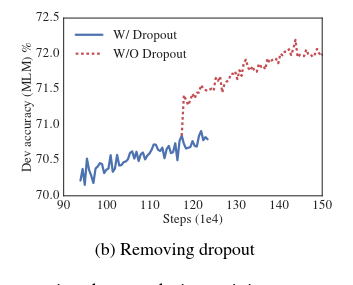

可以看出,去掉dropout后能够提升MLM的精度,同时在其它任务上也基本都有所提升;当然这可能是源于ALBERT的特殊架构,在其它transfomer架构上需要进一步实验论证。
四、总结
最后我们最终对比一下ALBERT和BERT的实现效果:
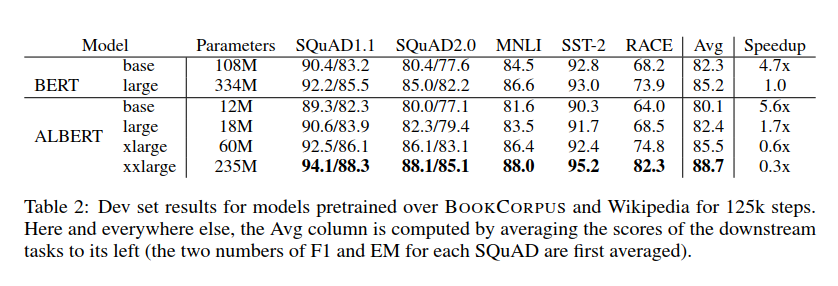
- 精度方面,ALBERT-xxlarge模型参数量仅仅是BERT-large模型的70%,但是下游各个任务上却都有较明显的效果提升
- 速度方面,这里以BERT-large模型作为baseline,因为ALBERT因为更少的通信和更少的计算,与相应的BERT模型相比,ALBERT模型具有更高的数据吞吐量。所以从实验数据可以看到,ALBERT-base和ALBERT-large分别是BERT-large训练速度的5.6倍和1.7倍,但是精度却仅有略微的降低。
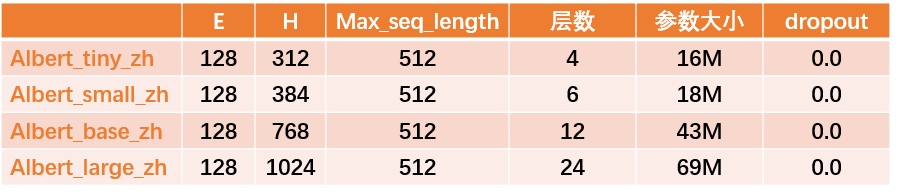
五、ALBERT_ZH
中文预训练ALBERT模型ALBERT_ZH上不是谷歌出的,而是由徐亮基于ALBERT开发,是一个更加精简的版本。相比ALBERT,ALBERT_ZH参数少了90%,但精度并没有损失。同时支持TensorFlow、PyTorch和Keras。虽然体积小,但却是建立在海量中文语料基础上,30G中文语料,超过100亿汉字,包括多个百科、新闻、互动社区。
预训练序列长度sequence_length设置为512,批次batch_size为4096,训练产生了3.5亿个训练数据(instance);每一个模型默认会训练125k步,ALBERT_xxlarge将训练更久。作为比较,roBERTa_zh预训练产生了2.5亿个训练数据、序列长度为256。由于ALBERT_zh预训练生成的训练数据更多、使用的序列长度更长。