Problem Description
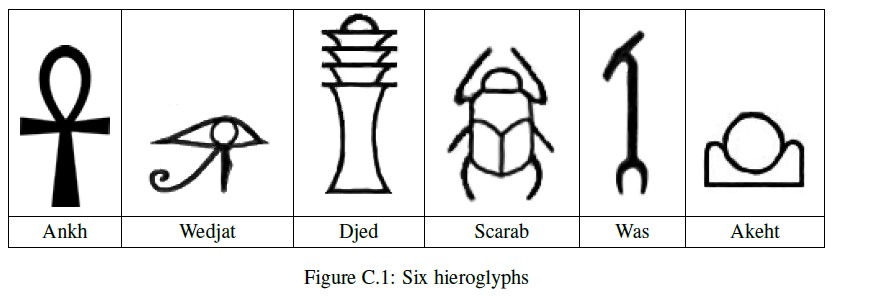
In order to understand early civilizations, archaeologists often study texts written in ancient languages. One such language, used in Egypt more than 3000 years ago, is based on characters called hieroglyphs. Figure C.1 shows six
hieroglyphs and their names. In this problem, you will write a program to recognize these six characters.
Input
The input consists of several test cases, each of which describes an image containing one or more hieroglyphs chosen from among those shown in Figure C.1. The image is given in the form of a series of horizontal scan lines consisting
of black pixels (represented by 1) and white pixels (represented by 0). In the input data, each scan line is encoded in hexadecimal notation. For example, the sequence of eight pixels 10011100 (one black pixel, followed by two white pixels, and so on) would
be represented in hexadecimal notation as 9c. Only digits and lowercase letters a through f are used in the hexadecimal encoding. The first line of each test case contains two integers, H and W: H (0 < H <= 200) is the number of scan lines in the image. W
(0 < W <= 50) is the number of hexadecimal characters in each line. The next H lines contain the hexadecimal characters of the image, working from top to bottom. Input images conform to the following rules:
The last test case is followed by a line containing two zeros.
1Two figures are topologically equivalent if each can be transformed into the other by stretching without tearing.
- The image contains only hieroglyphs shown in Figure C.1.
- Each image contains at least one valid hieroglyph.
- Each black pixel in the image is part of a valid hieroglyph.
- Each hieroglyph consists of a connected set of black pixels and each black pixel has at least one other black pixel on its top, bottom, left, or right side.
- The hieroglyphs do not touch and no hieroglyph is inside another hieroglyph.
- Two black pixels that touch diagonally will always have a common touching black pixel.
- The hieroglyphs may be distorted but each has a shape that is topologically equivalent to one of the symbols in Figure C.11.
The last test case is followed by a line containing two zeros.
1Two figures are topologically equivalent if each can be transformed into the other by stretching without tearing.
Output
For each test case, display its case number followed by a string containing one character for each hieroglyph recognized in the image, using the following code:
Ankh: A
Wedjat: J
Djed: D
Scarab: S
Was: W
Akhet: K
In each output string, print the codes in alphabetic order. Follow the format of the sample output.
The sample input contains descriptions of test cases shown in Figures C.2 and C.3. Due to space constraints not all of the sample input can be shown on this page.

Ankh: A
Wedjat: J
Djed: D
Scarab: S
Was: W
Akhet: K
In each output string, print the codes in alphabetic order. Follow the format of the sample output.
The sample input contains descriptions of test cases shown in Figures C.2 and C.3. Due to space constraints not all of the sample input can be shown on this page.
Sample Input
100 25 0000000000000000000000000 0000000000000000000000000 ...(50 lines omitted)... 00001fe0000000000007c0000 00003fe0000000000007c0000 ...(44 lines omitted)... 0000000000000000000000000 0000000000000000000000000 150 38 00000000000000000000000000000000000000 00000000000000000000000000000000000000 ...(75 lines omitted)... 0000000003fffffffffffffffff00000000000 0000000003fffffffffffffffff00000000000 ...(69 lines omitted)... 00000000000000000000000000000000000000 00000000000000000000000000000000000000 0 0
Sample Output
Case 1: AKW Case 2: AAAAA
Source
思路:依据圈的数量来识别。
#include <cstdio>
#include <algorithm>
using namespace std;
char ts[201],mes[6]={'W','A','K','J','S','D'},ans[10];
bool vis[205][205];
int n,m,mp[205][205],nxt[4][2]={{1,0},{0,1},{-1,0},{0,-1}},num;
void dfs(int x,int y)
{
int i;
for(i=0;i<4;i++)
{
x+=nxt[i][0];
y+=nxt[i][1];
if(x>=0 && x<n && y>=0 && y<m && !vis[x][y] && !mp[x][y])
{
vis[x][y]=1;
dfs(x,y);
}
x-=nxt[i][0];
y-=nxt[i][1];
}
}
void dfs3(int x,int y)
{
int i;
for(i=0;i<4;i++)
{
x+=nxt[i][0];
y+=nxt[i][1];
if(x>=0 && x<n && y>=0 && y<m && !vis[x][y] && !mp[x][y])
{
vis[x][y]=1;
dfs3(x,y);
}
x-=nxt[i][0];
y-=nxt[i][1];
}
}
void dfs2(int x,int y)
{
int i;
for(i=0;i<4;i++)
{
x+=nxt[i][0];
y+=nxt[i][1];
if(x>=0 && x<n && y>=0 && y<m && !vis[x][y])
{
if(mp[x][y])
{
vis[x][y]=1;
dfs2(x,y);
}
else
{
vis[x][y]=1;
num++;
dfs3(x,y);
}
}
x-=nxt[i][0];
y-=nxt[i][1];
}
}
int main()
{
int i,j,t,casenum=1,cnt;
while(~scanf("%d%d",&n,&m) && n)
{
n++;
m*=4;
m++;
for(i=0;i<=n;i++) for(j=0;j<=m;j++) vis[i][j]=0;
for(i=1;i<n;i++)
{
gets(ts);
if(!ts[0])
{
i--;
continue;
}
for(j=0;ts[j];j++)
{
if(ts[j]>='a' && ts[j]<='f')
{
t=ts[j]-'a'+10;
mp[i][j*4+1]=t/8;
mp[i][j*4+2]=t%8/4;
mp[i][j*4+3]=t%4/2;
mp[i][j*4+4]=t%2/1;
}
else
{
t=ts[j]-'0';
mp[i][j*4+1]=t/8;
mp[i][j*4+2]=t%8/4;
mp[i][j*4+3]=t%4/2;
mp[i][j*4+4]=t%2/1;
}
}
}
for(i=0;i<=m;i++) mp[n][i]=0;
for(i=0;i<=n;i++) mp[i][m]=0;
n++;
m++;
vis[0][0]=1;
dfs(0,0);
cnt=0;
for(i=0;i<n;i++)
{
for(j=0;j<m;j++)
{
if(mp[i][j] && !vis[i][j])
{
num=0;
vis[i][j]=1;
dfs2(i,j);
ans[cnt++]=mes[num];
}
}
}
sort(ans,ans+cnt);
ans[cnt]=0;
printf("Case %d: ",casenum++);
puts(ans);
}
}
版权声明:本文博客原创文章,博客,未经同意,不得转载。