论文名称:CornerNet-Lite: Efficient Keypoint Based Object Detection
论文链接:https://arxiv.org/abs/1904.08900
代码链接:https://github.com/princeton-vl/CornerNet-Lite
简介
该论文与Cornernet论文作者相同,都是由普林斯顿大学的几位学者提出。截止2019年4月份,CornerNet-Lite 应该是目标检测(Object Detection)中速度和精度trade-off的最佳算法。在精度上超越原来的Cornernet(速度是原来的6倍),在实时检测器领域无论是速度还是精度都超越yolov3(34.4% AP at 34ms for CornerNet-Squeeze compared to 33.0% AP at 39ms for YOLOv3 on COCO)。
CornerNet-Lite是CornerNet的两种有效变体的组合:CornerNet-Saccade和CornerNet-Squeeze,前者使用注意机制(attention)消除了对图像的所有像素进行处理的需要,将cornernet单阶段检测器变为两阶段检测器,attention maps作用类似与fasterrcnn中的rpn但又有所不同,将roi区域crop下来进行第二阶段的精细检测,该网络与cornernet相比达到精度提升;后者引入新的紧凑骨干架构的CornerNet-Squeeze,主干网络实为hourglass network、mobilenet、squeezenet结构的变体,在实时检测器领域达到速度和精度的双重提升。具体比较可看下图figure1:

CornerNet-Saccade
人类视觉中的 Saccades(扫视运动)是指用于固定不同图像区域的一系列快速眼动。在目标检测算法中,我们广义地使用该术语来表示在推理期间选择性地裁剪(crop)和处理图像区域(顺序地或并行地,像素或特征)。
R-CNN系列论文中的saccades机制为single-type and single-object,也就是产生proposal的时候为单类型(前景类)单目标(每个proposal中仅含一个物体或没有),AutoFocus论文中的saccades机制为multi-type and mixed(产生多种类型的crop区域)
CornerNet-Saccade中的 saccades是single type and multi-object,也就是通过attention map找到合适大小的前景区域,然后crop出来作为下一阶段的精检图片。CornerNet-Saccade 检测图像中可能的目标位置周围的小区域内的目标。它使用缩小后的完整图像来预测注意力图和粗边界框;两者都提出可能的对象位置,然后,CornerNet-Saccade通过检查以高分辨率为中心的区域来检测目标。它还可以通过控制每个图像处理的较大目标位置数来提高效率。具体流程如下图figure2所示,主要分为两个阶段估计目标位置和检测目标:

估计目标位置(Estimating Object Locations)
CornerNet-Saccade第一阶段通过downsized图片预测attention maps和coarse bounding box,以获得图片中物体的位置和粗略尺寸,这种降采样方式利于减少推理时间和便于上下文信息获取。
流程细节为首先将原始图片缩小到两种尺寸:长边为255或192像素,192填充0像素到255,然后并行处理。经过hourglass network(本文采用hourglass-54,由3个hourglass module组成),在hourglass-54的上采样层(具体在哪个hourglass module的上采样层论文中在3.5 Backbone Network部分有所提及,也就是最后一个module的三个上采样层,具体有待后期源码解析)预测3个attention maps(分别接一个3 × 3 Conv-ReLU module和一个1 × 1 Conv-Sigmoid module),分别用于小(小于32)中(32-96之间)大(大于96)物体预测,预测不同大小尺寸便于后面crop的时候控制尺寸(finer尺度预测小物体,coarser尺度预测大物体),训练时使用α = 2的focal loss,设置gt bbox的中点为positive,bbox其余为负样本,测试时大于阈值t=0.3的生成物体中心位置。
检测目标(Detecting Objects)
Crop区域的获取:
CornerNet-Saccade第二阶段为精检测第一阶段在原图(高分辨率下)crop区域的目标。
从Attention maps获取到的中心位置(粗略),可以根据物体尺寸选择放大倍数(小物体放大更多),ss>sm>sl,ss=4,sm=2,sl=1,在每个可能位置(x,y),放大downsized image si倍,i根据物体大小从{s,m,l}中选择,最后将此时的downsized image映射回原图,以(x,y)为中心点取255×255大小为crop区域。
从coarse bounding box获取的位置可以通过边界框尺寸决定放大尺寸,比如边界框的长边在放大后小物体应该达到24,中物体为64,大物体为192。
处理效率提升:1、利用gpu批量生成区域2、原图保存在gpu中,并在gpu中进行resize和crop
最终检测框生成以及冗余框消除:
最终的检测框通过CornerNet-Saccade第二阶段的角点检测机制生成,与cornernet中完全一致(不明确的小伙伴可以查看我另一篇cornernet算法笔记),最后也是通过预测crop区域的corner heatmaps, embeddings and offsets,merge后坐标映射回原图。
算法最后采用soft-nms消除冗余框,soft-nms无法消除crop区域中与边界接触的检测框,如下图figure3(这种检测框框出来的物体是不完整的,并与完整检测框iou较小,因此需要手工消除),可以在程序中直接删除该部分框。

其他:
精度和效率权衡:
根据分数排列第一阶段获取到的物体位置,取前Kmax个区域送入第二阶段精检测网络
抑制冗余目标位置:
当物体接近时,如下图figure4中的红点和蓝点所代表的人,会生成两个crop区域(红框和蓝框),作者通过类nms处理此类情况,首先通过分数排序位置,然后取分数最大值crop区域,消除与该区域iou较大的区域。

骨干网络:
本文提出由3个hourglass module组成的Hourglass-54作为主干网络,相比cornernet的hourglass-104主干网络(2个hourglass module)更轻量。下采样步长为2,在每个下采样层,跳连接,上采样层都有一个残差模块,每个hourglass module在下采样部分缩小三倍尺寸同时增加通道数(384,384,512),module中部的512通道也含有一个残差模块。
训练细节:
在4块1080ti上使用batch size为48进行训练,超参与cornernet相同,loss function优化策略也是adam。
CornerNet-Squeeze
与专注于subset of the pixels以减少处理量的CornerNet-Saccade相比,而CornerNet-Squeeze 探索了一种减少每像素处理量的替代方法。在CornerNet中,大部分计算资源都花在了Hourglass-104上。Hourglass-104 由残差块构成,其由两个3×3卷积层和跳连接(skip connection)组成。尽管Hourglass-104实现了很强的性能,但在参数数量和推理时间方面却很耗时。为了降低Hourglass-104的复杂性,本文将来自SqueezeNet和MobileNets 的想法融入到轻量级hourglass架构中。
主要操作是:受SqueezeNet启发,CornerNet-Squeeze将 residual block 替换为SqueezeNet中的 Fire module,受MobileNet启发,CornerNet-Squeeze将第二层的3x3标准卷积替换为3x3深度可分离卷积(depth-wise separable convolution)
具体如下表table1所示:(由于时间关系,这里对Fire module和depth-wise separable convolution不做详述,可自行查找SqueezeNet和MobileNet相关论文,CornerNet-Squeeze网络架构细节以及参数计算量推算也不展开,博主可能将在后续的源码解析中进行分析)

训练细节:
超参设置与cornernet相同,由于参数量减少,可以增大训练batch size,batch size of 55 on four 1080Ti GPUs (13 images on the master GPU and 14 images per GPU for the rest of the GPUs).
实验
开源代码是基于PyToch1.0.0,在COCO数据集上进行测试。测试硬件环境为:1080ti GPU + Intel Core i7-7700k CPU。
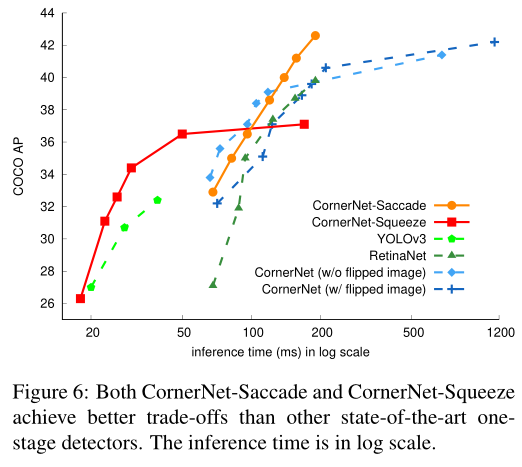
One-stage 算法性能比较如上图figure6,其中log scale博主认为是不同检测器的速度与精度权衡条件,比如CornerNet-Saccade可以为Kmax(crop区域数)

上表table2对比CornerNet和CornerNet-Saccade训练效率,可以看出在gpu的内存使用上节省了将近60%。

上表table3表明attention maps对于预测准确性的重要性,可以看出将attention maps用gt替代,ap值得到很大提升。
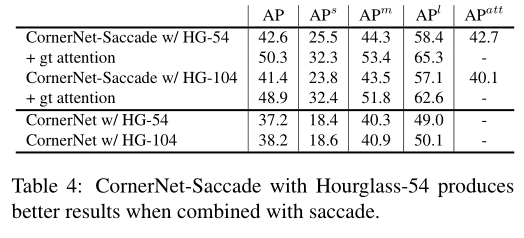
上表table4为表明主干网络hourglass-54相比hourglass-104的性能提升,以及它对于attention maps预测的意义。
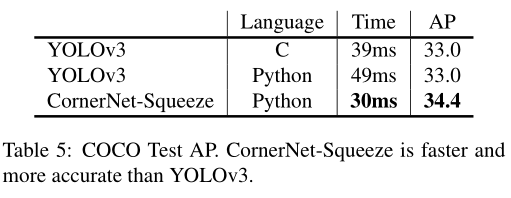
上表table5是CornerNet-Squeeze与yolov3对比,可以看出无论是python还是效率更高的C版本yolo都弱于CornerNet-Squeeze

上表table6为CornerNet-Squeeze的消融实验。

上表table7中证明无法将本论文中的两种网络机制联合,原因是CornerNet-Squeeze没有足够的能力提供对CornerNet-Saccade贡献巨大的attention maps的预测。

上表table8表明本文中的两种网络架构,CornerNet-Squeeze在精度和速度方面对标YOLOv3完胜,CornerNet-Saccade主要在精度方面对标CornerNet完胜(速度意义不大)。
总结
本论文主要提出两种CornerNet的改进方法,并在速度和精度方面取得较大意义,分别对标之前的CornerNet和YOLOv3(不熟悉CornerNet的同学无法理解本篇博文,建议查看博主另一篇CornerNet算法笔记),与此同时的另一篇基于CornerNet关键点的arXiv论文(2019.04)Centernet(https://arxiv.org/abs/1904.08189)提出Keypoint Triplets思想也对Cornernet进行优化,达到目前单阶段目标检测器最高精度(47.0%)。接下来我将对该论文进行总结。