概述
MapReduce是由JeffreyDean提出的一种处理大数据的编程模型,用户定义map和reduce函数,map函数处理原始数据生成一系列键值对中间数据,reduce函数并合相同key的键值对。
编程模型
整个计算过程输入的是键值对,输出的也是键值对。用户只需要提供两个函数分别是Map和Reduce。
比如要统计大数据文本中的词频,我们可以写出如下的Map和Reduce函数:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
map函数的参数key, value分别是文本名和文本内容,map函数提取文本的每个单词,每个单词生成一个<w, "1">的键值对。
reduce函数对这些键值对进行并和,产生最终的统计结果。
实现
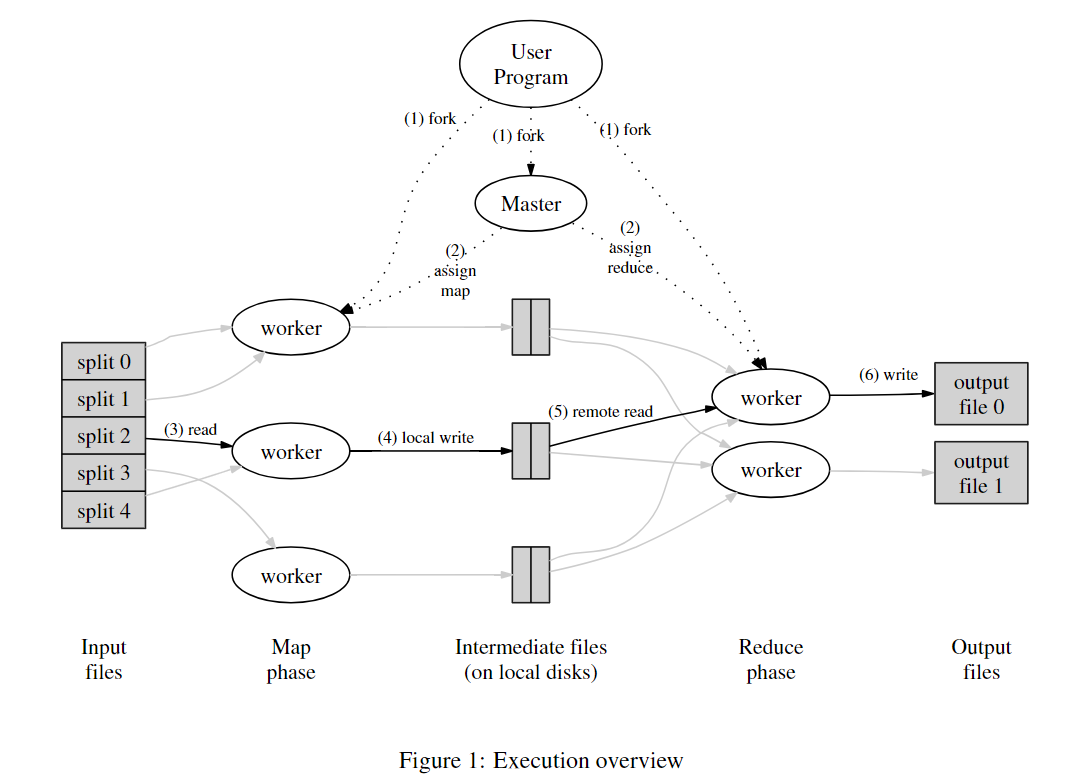
当用户程序调用MapReduce函数后,将会发生如下动作:
- 用户输入的文件将被分成M份
- 集群中有一个master,其它的都是worker,总共有M个map任务和R个reduce任务(M和R由用户指定)。master负责将map和reduce任务分配给空闲的worker。
- 负责map任务的worker执行用户定义的Map函数,将中间键值对保存到本地,并分成R份,并将位置发送给master。
- 负责reduce任务的worker从master得到中间数据的位置,读取数据到本地,调用reduce函数。
- 所有map和reduce调用结束后MapReduce调用结束,返回用户程序。最终的结果应该是R个redcue生成的文件。通常这些文件作为下一个MapReduece的输入继续处理。
容错
worker failure:
- master周期性的ping worker,如果worker没有相应则标记该worker为failed
- 如果一个map任务现在worker A执行,但是失败了,后来在worker B执行。那么后面的Reduce worker从worker B读取中间数据。
master failure:
master只有一个,失败几率很小。可以终止MapReduce。