原以为搭建一个本地编程测试hadoop程序的环境很简单,没想到还是做得焦头烂额,在此分享步骤和遇到的问题,希望大家顺利.
一.要实现连接hadoop集群并能够编码的目的需要做如下准备:
1.远程hadoop集群(我的master地址为192.168.85.2)
2.本地myeclipse及myeclipse连接hadoop的插件
3.本地hadoop(我用的是hadoop-2.7.2)
先下载插件hadoop-eclipse-plugin,我用的是hadoop-eclipse-plugin-2.6.0.jar,下载之后放在"MyEclipse Professional 2014dropins"目录下,重启myeclipse会在perspective和views发现一个map/reduce的选项


切换到hadoop试图,然后打开MapReduce Tools
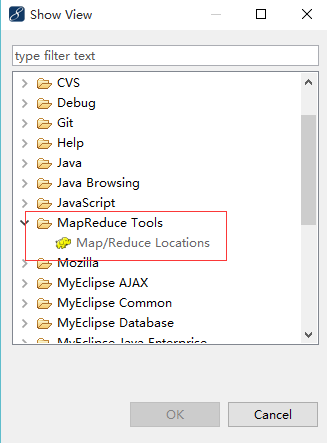
二.接下来新增hadoop服务,要开始配置连接,需要查看hadoop配置
1.hadoop/etc/hadoop/mapred-site.xml配置,查看mapred.job.tracker里面的ip和port,用以配置Map/Reduce Master
2.hadoop/etc/hadoop/core-site.xml配置,查看fs.default.name里面的ip和port,用以配置DFS Master
3.用户名直接写hadoop操作用户即可
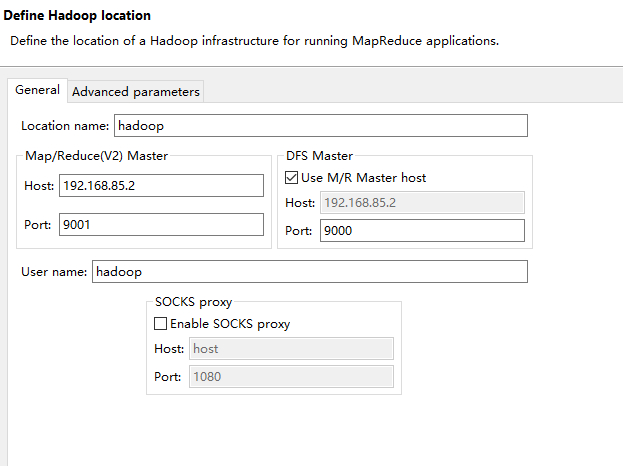
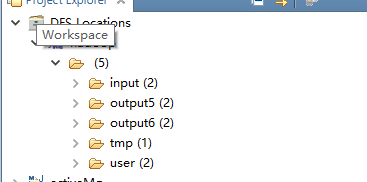
到此配置就完成了,顺利的话可以看到:
新建hadoop工程.
File】->【New】->【Project...】->【Map/Reduce】->【Map/Reduce Project】->【Project name: WordCount】->【Configure Hadoop install directory...】->【Hadoop installation directory: D: lsoftwarehadoophadoop-2.7.2】->【Apply】->【OK】->【Next】->【Allow output folders for source folders】->【Finish】
工程下建立三个类,分别是Mapper,Reduce,和main
TestMapper
package bb; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Mapper.Context; public class TestMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
TestReducer
package bb; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Reducer.Context; public class TestReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
WordCount
package bb; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TestMapper.class); job.setCombinerClass(TestReducer.class); job.setReducerClass(TestReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
我在hdfs的input里面新建了两个tex文件,这时候可以用来测试,也可以用其他的文件测试.所以我的参数如图:
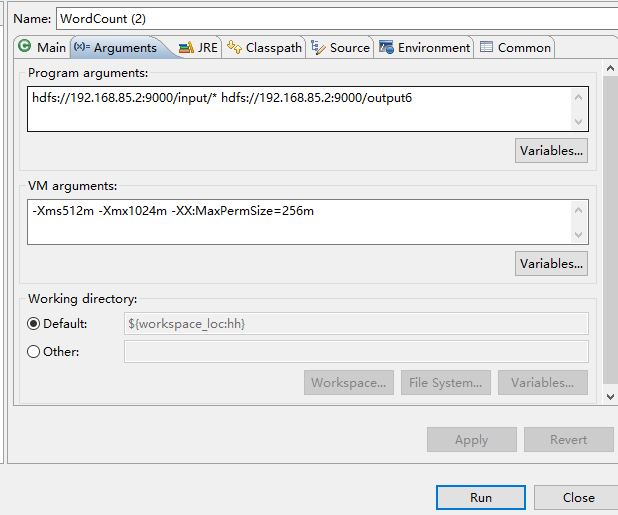
hdfs://192.168.85.2:9000/input/* hdfs://192.168.85.2:9000/output6
-Xms512m -Xmx1024m -XX:MaxPermSize=256m
稍作解释,参入的两个参数,一个是输入文件,一个是输出结果文件.指定正确目录即可. output6文件夹的名字是我随便写的.会自动创建
那么到了最后也是最关键的一步.我run as hadoop时遇到了
Server IPC version 9 cannot communicate with client version 4
报错.这是提示版本不对,我一看.远程hadoop版本与jar包版本不同导致的.远程是2.7.2的.所以我把hadoop相关jar包改为该版本即可(2.*版本的应该都可以,没有的话相近的也可以用)
然后错误换了一个
Exception in thread "main" ExitCodeException exitCode=-1073741515:
经过查阅资料发现这是因为window本地的hadoop没有winutils.exe导致的.原来本地hadoop的机理要去调用这个程序.我们先要去下载2.7的winutils.exe然后使得其运行没错才可以.
下载之后发现需要hadoop.dll文件.晕.再次下载并放在c:windowsSystem32目录下.
然而我的winutils.exe还是无法启动,这个虽然是我的电脑问题.但是想来有些人还是会遇到(简单说一下).
报错缺少msvcr120.dll.下载之后再去启动提示,"应用程序无法正常启动0xc000007b".
这是内存错误引起的.下载DirectX_Repair修复directx终于解决了问题,最后成功启动了hadoop程序.
有同学可能能够启动winutils.exe但还是不能正常跑应用程序,依然报错,可以尝试修改权限验证.
修改hadoop/etc/hadoop/hdfs-site.xml
添加内容
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
取消权限验证.