K8S集群Master高可用实践
本文将在前文基础上介绍k8s集群的高可用实践,一般来讲,k8s集群高可用主要包含以下几个内容:
1、etcd集群高可用
2、集群dns服务高可用
3、kube-apiserver、kube-controller-manager、kube-scheduler等master组件的高可用其中etcd实现的办法较为容易,具体实现办法可参考前文:
https://blog.51cto.com/ylw6006/2095871集群dns服务高可用,可以通过配置dns的pod副本数为2,通过配置label实现2个副本运行在在不同的节点上实现高可用。
kube-apiserver服务的高可用,可行的方案较多,具体介绍可参考文档:
https://jishu.io/kubernetes/kubernetes-master-ha/kube-controller-manager、kube-scheduler等master组件的高可用相对容易实现,运行多份实例即可。
一、环境介绍
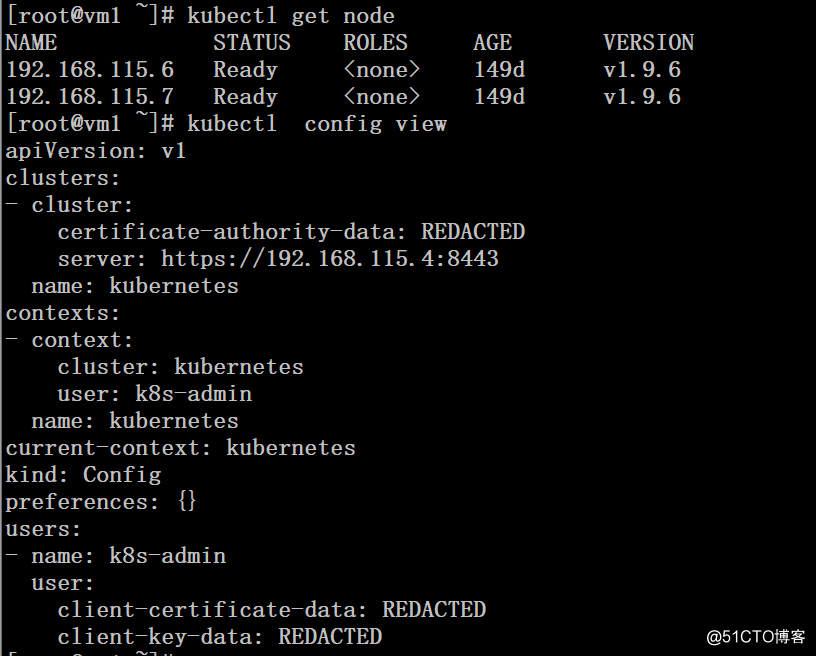
master节点1: 192.168.115.5/24 主机名:vm1
master节点2: 192.168.115.6/24 主机名:vm2
VIP地址: 192.168.115.4/24 (使用keepalived实现)
Node节点1: 192.168.115.6/24 主机名:vm2
Node节点2: 192.168.115.7/24 主机名:vm3操作系统版本:centos 7.2 64bit
K8s版本:1.9.6 二进制部署本文演示环境是在前文的基础上,已有k8s集群(1个master节点、2个node节点上),实现k8s集群master组件的高可用,关于k8s环境的部署请参考前文链接!
1、配置Etcd集群和TLS认证 ——> https://blog.51cto.com/ylw6006/2095871
2、Flannel网络组件部署 ——> https://blog.51cto.com/ylw6006/2097303
3、升级Docker服务 ——> https://blog.51cto.com/ylw6006/2103064
4、K8S二进制部署Master节点 ——> https://blog.51cto.com/ylw6006/2104031
5、K8S二进制部署Node节点 ——> https://blog.51cto.com/ylw6006/2104692
二、证书更新
在vm1节点上完成证书的更新,重点是要把master相关ip全部全部加入到列表里面
# mkdir api-ha && cd api-ha
# cat k8s-csr.json
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"192.168.115.4",
"192.168.115.5",
"192.168.115.6",
"10.254.0.1",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "FuZhou",
"L": "FuZhou",
"O": "k8s",
"OU": "System"
}
]
}
# cfssl gencert -ca=/etc/ssl/etcd/ca.pem
-ca-key=/etc/ssl/etcd/ca-key.pem
-config=/etc/ssl/etcd/ca-config.json
-profile=kubernetes k8s-csr.json | cfssljson -bare kubernetes
# mv *.pem /etc/kubernetes/ssl/三、配置master组件
1、复制vm1的kube-apiserver、kube-controller-manager、kube-scheduler文件到vm2节点上
# cd /usr/local/sbin
# scp -rp kube-apiserver kube-controller-manager kube-scheduler vm2:/usr/local/sbin/2、复制vm1的证书文件到vm2节点上
# cd /etc/kubernetes/ssl
# scp -rp ./* vm2:/etc/kubernetes/ssl3、配置服务并启动服务
# cat /usr/lib/systemd/system/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
ExecStart=/usr/local/sbin/kube-apiserver
--admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota
--advertise-address=0.0.0.0
--bind-address=0.0.0.0
--insecure-bind-address=127.0.0.1
--authorization-mode=RBAC
--runtime-config=rbac.authorization.k8s.io/v1alpha1
--kubelet-https=true
--enable-bootstrap-token-auth=true
--token-auth-file=/etc/kubernetes/token.csv
--service-cluster-ip-range=10.254.0.0/16
--service-node-port-range=1024-65535
--tls-cert-file=/etc/kubernetes/ssl/kubernetes.pem
--tls-private-key-file=/etc/kubernetes/ssl/kubernetes-key.pem
--client-ca-file=/etc/ssl/etcd/ca.pem
--service-account-key-file=/etc/ssl/etcd/ca-key.pem
--etcd-cafile=/etc/ssl/etcd/ca.pem
--etcd-certfile=/etc/ssl/etcd/server.pem
--etcd-keyfile=/etc/ssl/etcd/server-key.pem
--etcd-servers=https://192.168.115.5:2379,https://192.168.115.6:2379,https://192.168.115.7:2379
--enable-swagger-ui=true
--allow-privileged=true
--apiserver-count=3
--audit-log-maxage=30
--audit-log-maxbackup=3
--audit-log-maxsize=100
--audit-log-path=/var/lib/audit.log
--event-ttl=1h
--v=2
Restart=on-failure
RestartSec=5
Type=notify
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target# cat /usr/lib/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/usr/local/sbin/kube-scheduler
--address=127.0.0.1
--master=http://127.0.0.1:8080
--leader-elect=true
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target# cat /usr/lib/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/usr/local/sbin/kube-controller-manager
--address=127.0.0.1
--master=http://127.0.0.1:8080
--allocate-node-cidrs=true
--service-cluster-ip-range=10.254.0.0/16
--cluster-cidr=172.30.0.0/16
--cluster-name=kubernetes
--cluster-signing-cert-file=/etc/ssl/etcd/ca.pem
--cluster-signing-key-file=/etc/ssl/etcd/ca-key.pem
--service-account-private-key-file=/etc/ssl/etcd/ca-key.pem
--root-ca-file=/etc/ssl/etcd/ca.pem
--leader-elect=true
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target# systemctl enable kube-apiserver
# systemctl enable kube-controller-manager
# systemctl enable kube-scheduler
# systemctl start kube-apiserver
# systemctl start kube-controller-manager
# systemctl start kube-scheduler注意:
vm1上的api-server配置文件需要将--advertise-address、--bind-address两个参数修改为全网监听
四、安装和配置keepalived
# yum -y install keepalived
# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
ylw@fjhb.cn
}
notification_email_from admin@fjhb.cn
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_MASTER
}
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 3
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 60
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass k8s.59iedu.com
}
virtual_ipaddress {
192.168.115.4/24
}
track_script {
check_apiserver
}
}# cat /usr/lib/systemd/system/keepalived.service
[Unit]
Description=LVS and VRRP High Availability Monitor
After=syslog.target network-online.target kube-apiserver.service
Require=kube-apiserver.service
[Service]
Type=forking
PIDFile=/var/run/keepalived.pid
KillMode=process
EnvironmentFile=-/etc/sysconfig/keepalived
ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target注意:
vm2节点上需要修改state为BACKUP, priority为99 (priority值必须小于master节点配置值)
# cat /etc/keepalived/check_apiserver.sh
#!/bin/bash
flag=$(systemctl status kube-apiserver &> /dev/null;echo $?)
if [[ $flag != 0 ]];then
echo "kube-apiserver is down,close the keepalived"
systemctl stop keepalived
fi
# chmod +x /etc/keepalived/check_apiserver.sh
# systemctl daemon-reload
# systemctl enable keepalived
# systemctl start keepalived五、修改客户端配置
1、Kubelet.kubeconfig 、bootstrap.kubeconfig、kube-proxy.kubeconfig 配置
# grep 'server' /etc/kubernetes/kubelet.kubeconfig
server: https://192.168.115.4:6443
# grep 'server' /etc/kubernetes/bootstrap.kubeconfig
server: https://192.168.115.4:6443
# grep 'server' /etc/kubernetes/kube-proxy.kubeconfig
server: https://192.168.115.4:64432、confing配置
# grep 'server' /root/.kube/config
server: https://192.168.115.4:64433、重启客户端服务
# systemctl restart kubelet
# systemctl restart kube-proxy六、测试
1、关闭服务前的集群状态,VIP在vm1节点上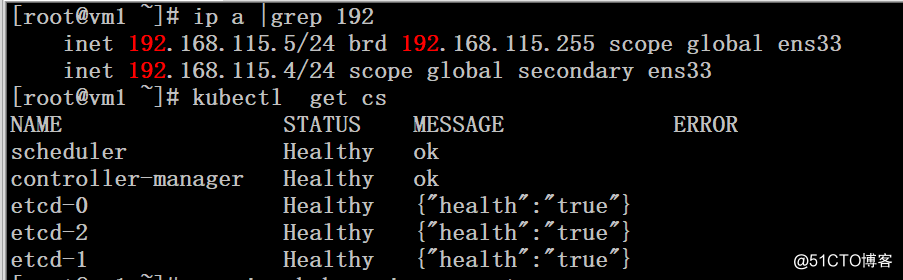
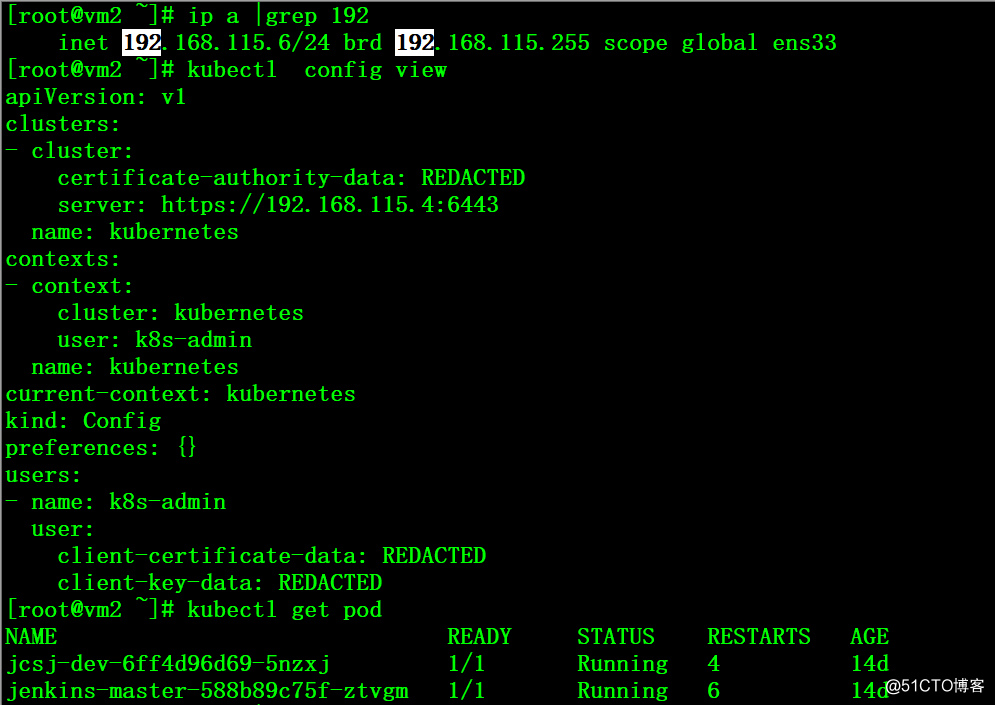
2、在vm1上将kube-apiserver服务停止,可以看到VIP消息,但任何可以连接master获取pod信息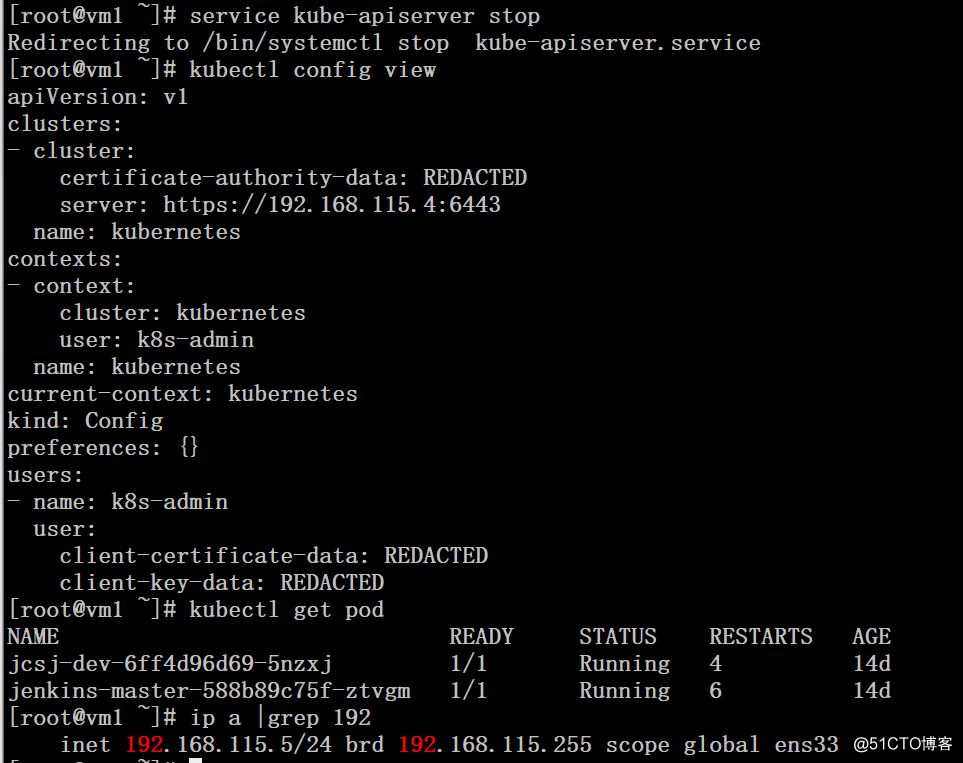
日志显示vip被自动移除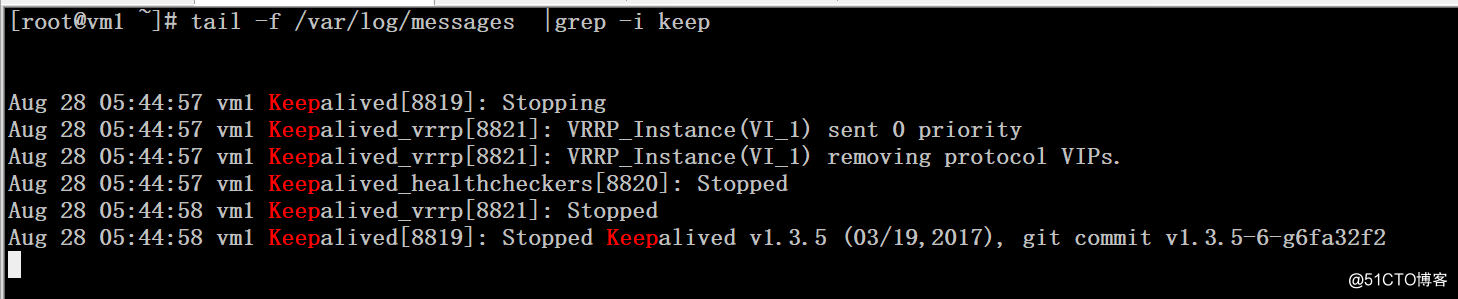
3、在vm2上能看到自动注册上了VIP,且kubectl客户端连接正常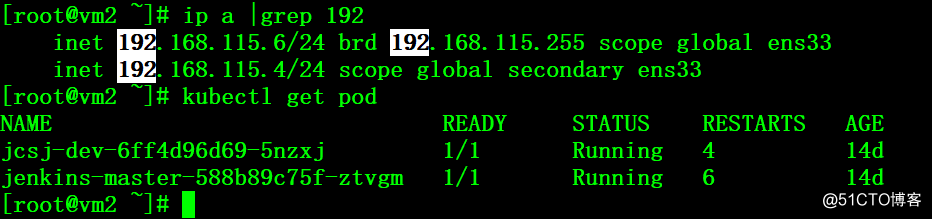
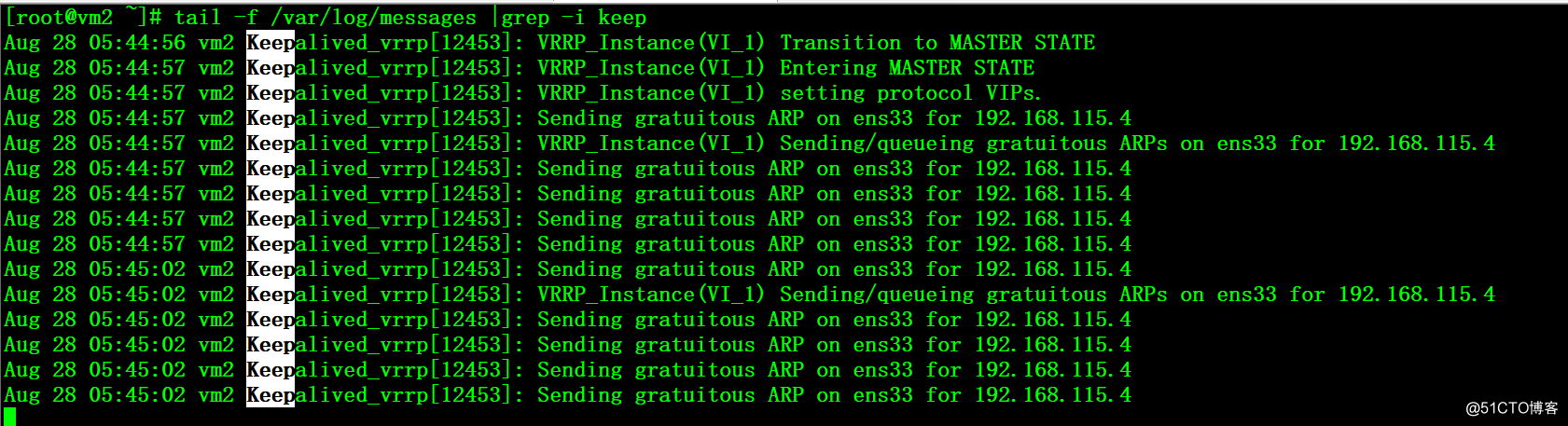
4、在vm1上将kube-apiserver、keepalived服务启动,由于配置的是主从模式,所以会抢占VIP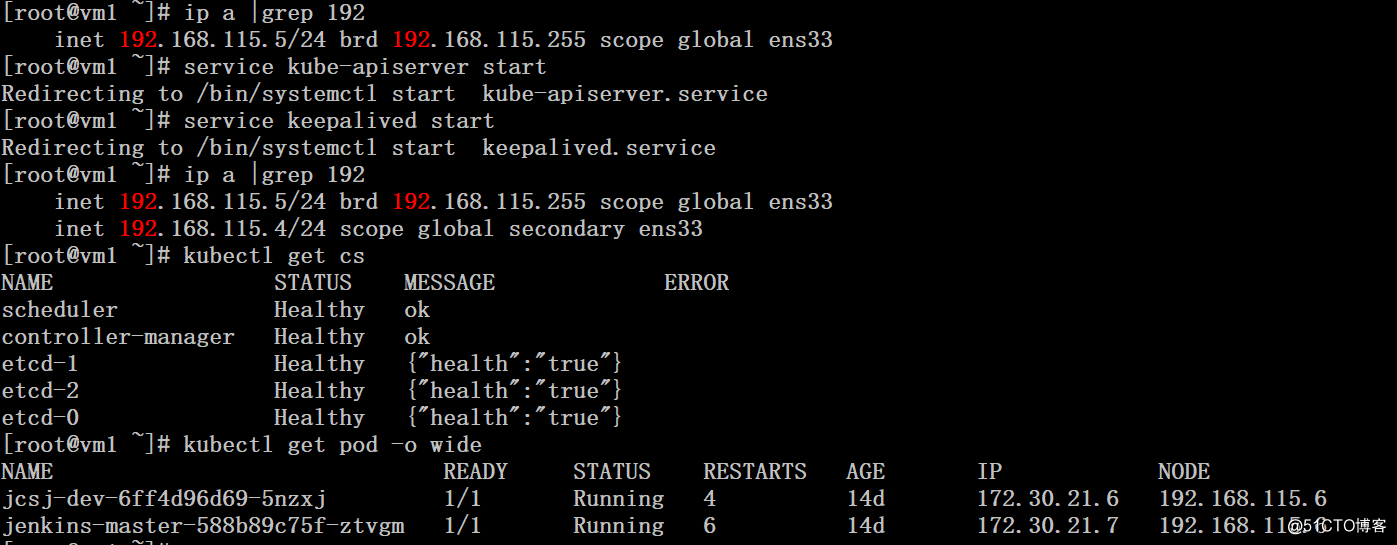
5、在vm2上可以看到VIP的释放,keepalived重新进入backup状态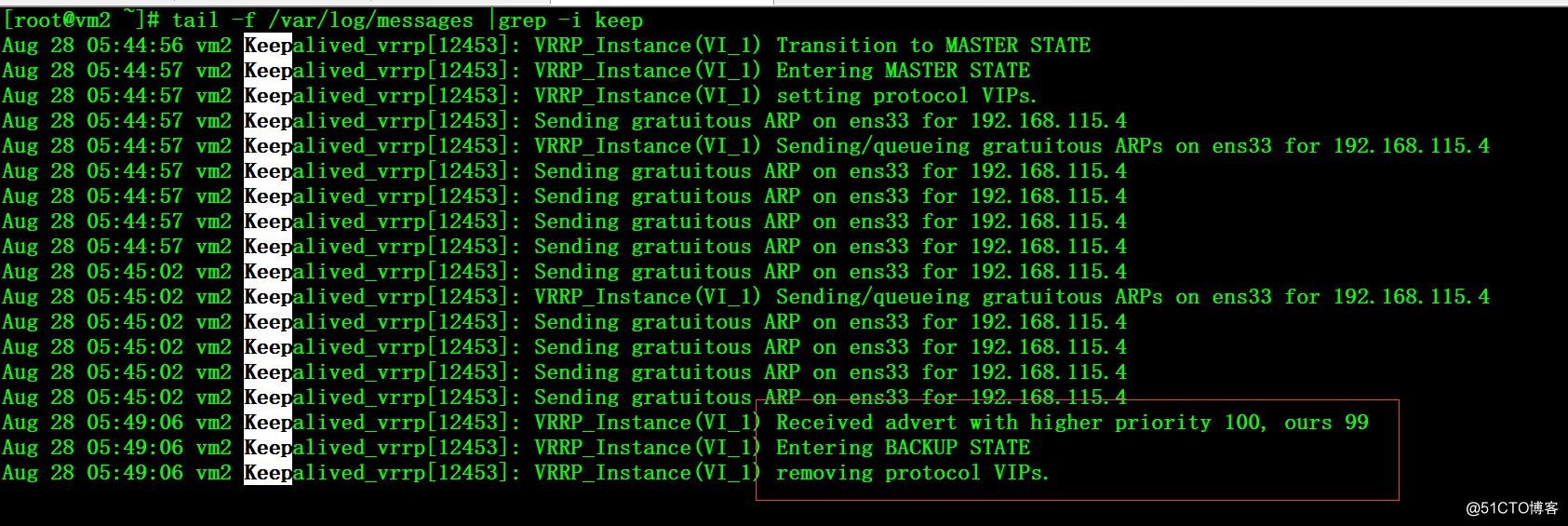
6、在整个过程中可以用其他的客户端来连接master VIP来测试服务器的连续性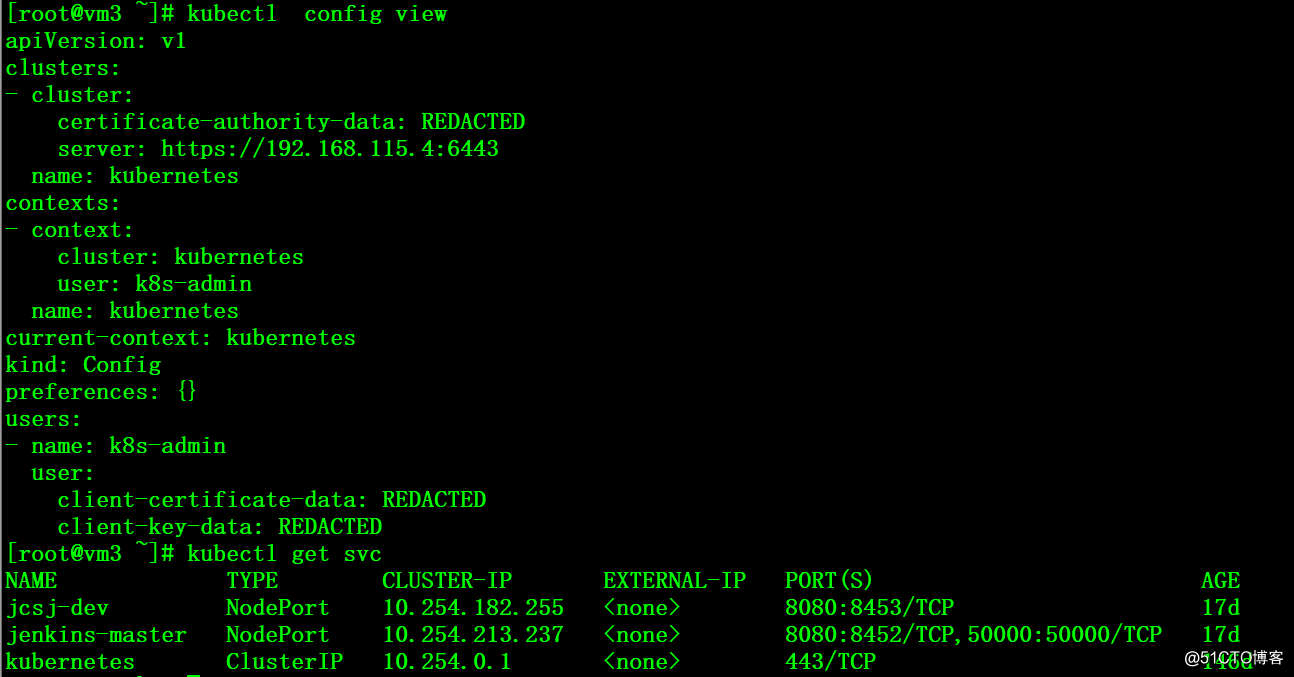
七、使用haproxy改进
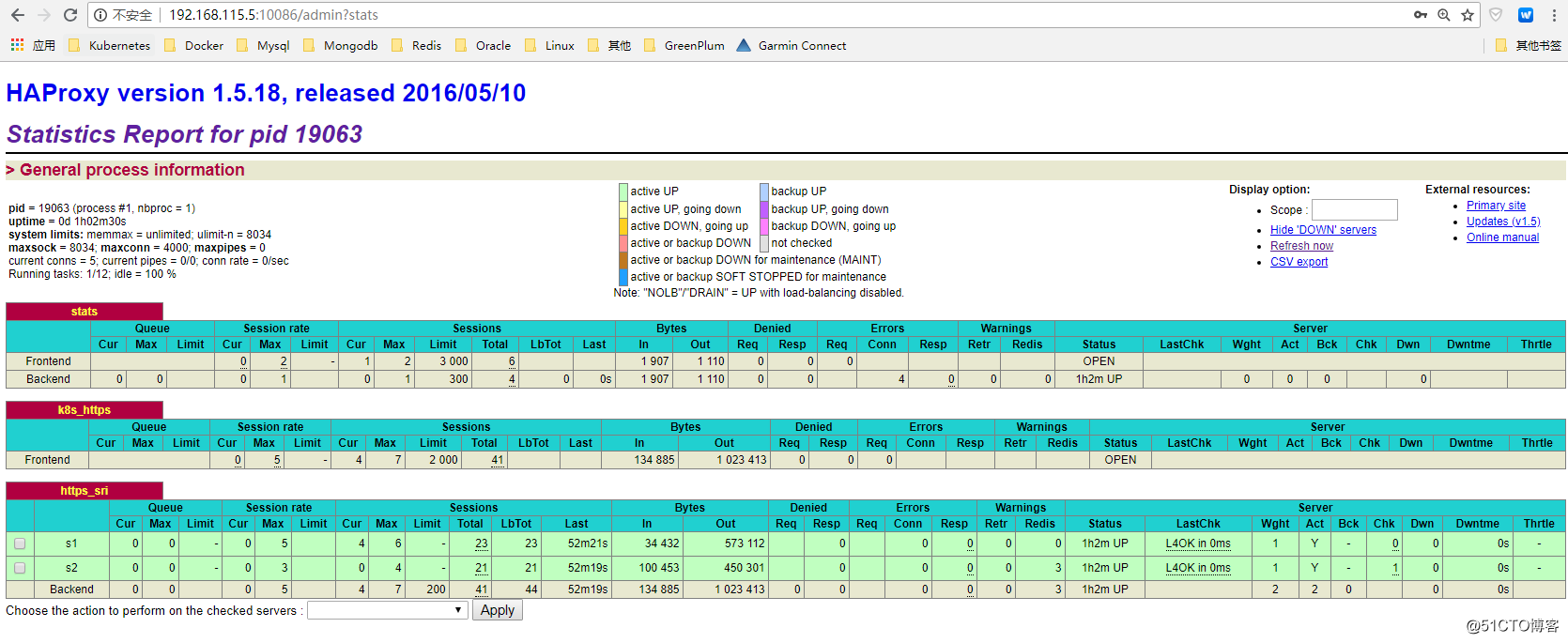
只用keepalived实现master ha,当api-server的访问量大的时候,会有性能瓶颈问题,通过配置haproxy,可以同时实现master的ha和流量的负载均衡。
1、安装和配置haproxy,两台master做同样的配置
# yum -y install haproxy
# cat /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode tcp
log global
option tcplog
option dontlognull
option redispatch
retries 3
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
maxconn 3000
listen stats
mode http
bind :10086
stats enable
stats uri /admin?stats
stats auth admin:admin
stats admin if TRUE
frontend k8s_https *:8443
mode tcp
maxconn 2000
default_backend https_sri
backend https_sri
balance roundrobin
server s1 192.168.115.5:6443 check inter 10000 fall 2 rise 2 weight 1
server s2 192.168.115.6:6443 check inter 10000 fall 2 rise 2 weight 12、修改kube-apiserver配置,ip地址根据实际情况修改
# grep 'address' /usr/lib/systemd/system/kube-apiserver.service
--advertise-address=192.168.115.5
--bind-address=192.168.115.5
--insecure-bind-address=127.0.0.1 3、修改keepalived启动脚本和配置文件,vrrp脚本的ip地址根据实际情况修改
# cat /usr/lib/systemd/system/keepalived.service
[Unit]
Description=LVS and VRRP High Availability Monitor
After=syslog.target network-online.target
Require=haproxy.service
########以下输出省略########## cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
ylw@fjhb.cn
}
notification_email_from admin@fjhb.cn
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_MASTER
}
vrrp_script check_apiserver {
script "curl -o /dev/null -s -w %{http_code} -k https://192.168.115.5:6443"
interval 3
timeout 3
fall 2
rise 2
}
########以下输出省略#########4、修改kubelet和kubectl客户端配置文件,指向haproxy的端口8443
# grep '192' /etc/kubernetes/bootstrap.kubeconfig
server: https://192.168.115.4:8443
# grep '192' /etc/kubernetes/kubelet.kubeconfig
server: https://192.168.115.4:8443
# grep '192' /etc/kubernetes/kube-proxy.kubeconfig
server: https://192.168.115.4:8443
# grep '192' /root/.kube/config
server: https://192.168.115.4:84435、重启服务验证
master
# systemctl daemon-reload
# systemctl enable haproxy
# systemctl start haproxy
# systemctl restart keepalived
# systemctl restart kube-apiserver kubelet
# systemctl restart kubelet
# systemctl restart kube-proxy