simsaim笔记
在对比学习中做了减法~完美的去掉了大batch size,负例,动量encoder这些操作。
增加了stop gradient有效的防止了模型坍塌(就是模型收敛到一个固定的常数)
大佬的思想就是这般简单易懂!
下面来好好唠唠~
论文地址:https://arxiv.org/pdf/2011.10566.pdf
In this paper,we report surprising empirical results that simple Siamese networks can learn meaningful representations even using none of the following:
(i) negative sample pairs, (ii) large batches, (iii) momentum encoders. Our experiments show that collapsing solutions do exist for the loss and structure, but a stop-gradient operation plays an essential role in preventing collapsing. We provide a hypothesis on the implication of stop-gradient, and further show proof-of-concept experiments verifying it. Our “SimSiam” method achieves competitive results on ImageNet and downstream tasks. We hope this simple baseline will motivate people to rethink the roles of Siamese architectures for unsupervised representation learning. Code will be made available.
摘要中直接说明,simsaim中直接弃用(i) negative sample pairs, (ii) large batches, (iii) momentum encoders. 这三个,使用stop-gradient 累计梯度来有效防止模型坍塌。simsaim是对saimcse的一个简单的改进。其实就是在saimcse基础上增加了stop-grad。有图有真相
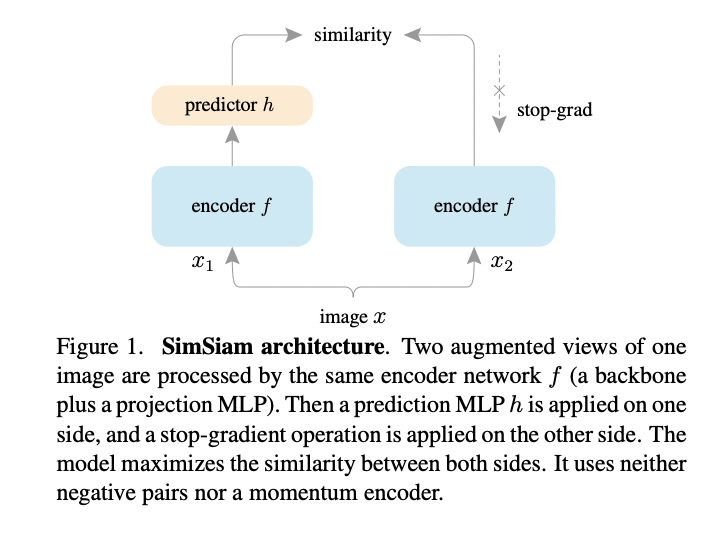
作者还做了一个有无stop-grad的对比实验
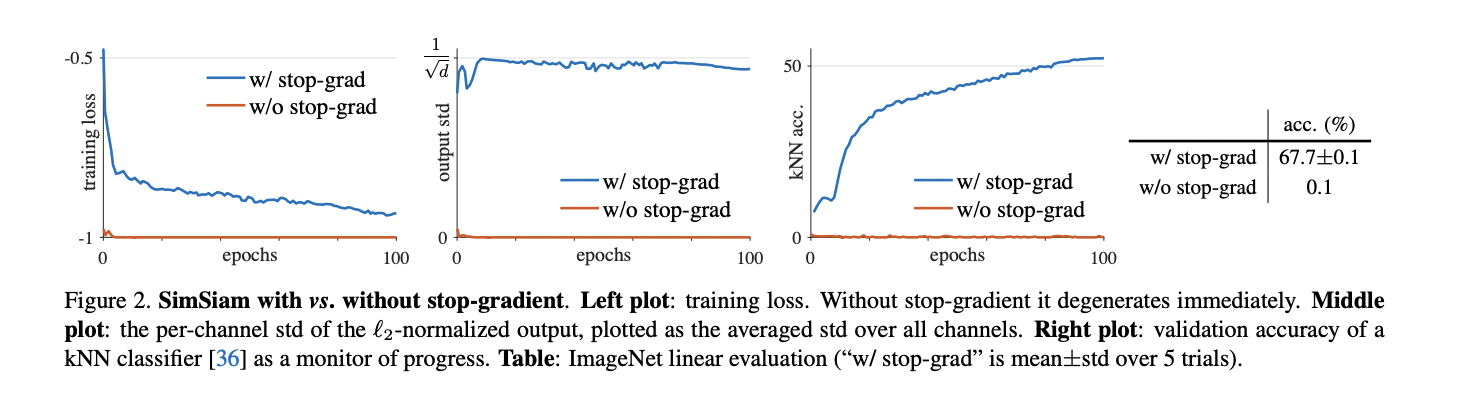
作图加上stop-grad的训练误差更小,右图中加入stop-grad的准确率更高,中间图中输出层的标注差更小,更稳定。
总体上来说,实验除去了很多冗余的部分。
作者还对如下部分进行了实验projector结构,batchsize,bn
projector结构
这个结构simclr中很早就提到过,就是一个mlp结构 dense-relu-dense
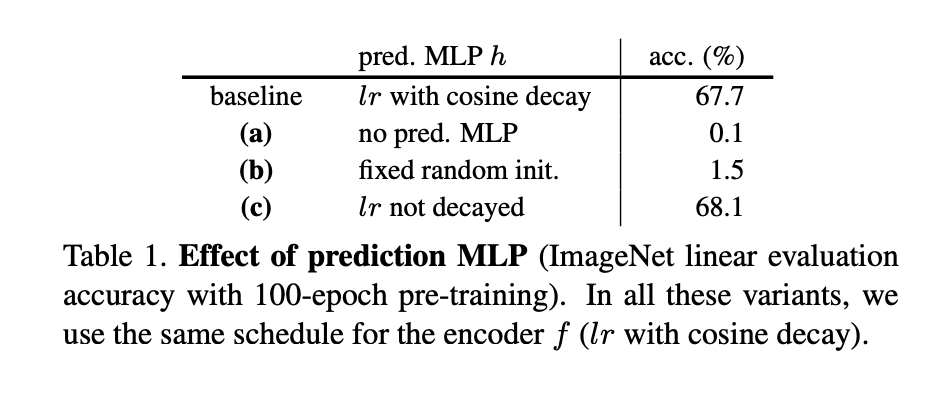
In Table 1 we study the predictor MLP's effect. The model does not work if removing (h) (Table 1a), i.e., (h) is the identity mapping. Actually, this observation can be expected if the symmetric loss (4) is used. Now the loss is (frac{1}{2} mathcal{D}left(z_{1} ight.), stopgrad (left.left(z_{2} ight) ight)+frac{1}{2} mathcal{D}left(z_{2} ight.), stopgrad (left.left(z_{1} ight) ight) .) Its gradient has the same direction as the gradient of (mathcal{D}left(z_{1}, z_{2} ight)), with the magnitude scaled by (1 / 2). In this case, using stop-gradient is equivalent to removing stop-gradient and scaling the loss by (1 / 2). Collapsing is observed (Table 1a).
table 1a中是不加stop-grad 梯度塌陷的表现
We note that this derivation on the gradient direction is valid only for the symmetrized loss. But we have observed that the asymmetric variant (3) also fails if removing (h), while it can work if (h) is kept (Sec. 4.6). These experiments suggest that (h) is helpful for our model.
如果去掉隐藏层,也会出现梯度塌陷。说明增加隐藏层是有效果的。
If (h) is fixed as random initialization, our model does not work either (Table 1b). However, this failure is not about collapsing. The training does not converge, and the loss remains high. The predictor (h) should be trained to adapt to the representations.
,
Table 1b中如果随机初始化(h),simsaim同样也是没有效果,出现梯度塌陷
We also find that (h) with a constant (l r) (without decay) can work well and produce even better results than the baseline (Table 1c). A possible explanation is that (h) should adapt to the latest representations, so it is not necessary to force it converge (by reducing (l r) ) before the representations are sufficiently trained. In many variants of our model, we have observed that (h) with a constant (l r) provides slightly better results. We use this form in the following subsections.
固定的lr学习率的效果是要好于学习率递减的效果的
batchsize
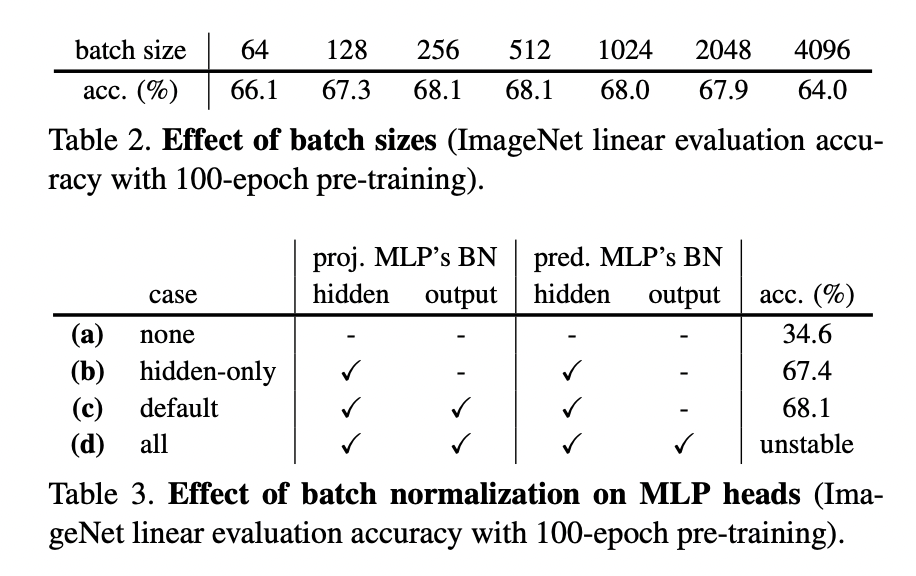
根据table2的实验,bs达到512效果最好,更大的bs反倒下降
bn
根据表table3 a hiden层不加入bn的效果只有34.6,增加projector,并且在hiden等加上bn的效果要好于output层加上bn,但是都加上bn变得不稳定了。
为什么hiden layer上加bn效果要好于output层上加bn?
容笔者思考下~