对比学习/度量学习
对比学习和度量学习从定义上看没有本质的差别。
最近发现票圈被陈丹奇的simCSE刷屏了,让笔者也深刻的认识到,现如今文本表示领域研究已经是对比学习的天下了。笔者在本文中将从对比学习的定义,损失函数以及CV和NLP领域的相关文章逐步解析对比学习。

- 文本表示是什么?就是一个文本x用z进行表示,通过z能够反找到x。
对比学习的思想最早源于cv领域的研究。
对比学习是自监督学习的一种,也就是说,不依赖标注数据,要从无标注图像中自己学习知识。我们知道,自监督学习其实在图像领域里已经被探索了很久了。总体而言,图像领域里的自监督可以分为两种类型:生成式自监督学习,判别式自监督学习。VAE和GAN是生成式自监督学习的两类典型方法,即它要求模型重建图像或者图像的一部分,这类型的任务难度相对比较高,要求像素级的重构,中间的图像编码必须包含很多细节信息。对比学习则是典型的判别式自监督学习,相对生成式自监督学习,对比学习的任务难度要低一些。目前,对比学习貌似处于“无明确定义、有指导原则”的状态,它的指导原则是:“通过自动构造相似实例和不相似实例,要求习得一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远”。而如何构造相似实例,以及不相似实例,如何构造能够遵循上述指导原则的表示学习模型结构,以及如何防止模型坍塌(Model Collapse),这几个点是其中的关键。
目前出现的对比学习方法已有很多,如果从防止模型坍塌的不同方法角度,我们可大致把现有方法划分为:基于负例的对比学习方法、基于对比聚类的方法、基于不对称网络结构的方法,以及基于冗余消除损失函数的方法。张俊林
模型坍塌:全部都收敛到一个常数值,全都变成一个表示。
对比学习的定义
再给出明确定义之前,先举个有趣的例子:
我们大多数人能分辨出很多真假币,但如果要我们画一张百元大钞出来,我相信基本上画得一点都不像。这表明,对于真假币识别这个任务,可以设想我们有了一堆真假币供学习,我们能从中提取很丰富的特征,但是这些特征并不足以重构原图,它只能让我们分辨出这堆纸币的差异。也就是说,对于数据集和任务来说,合理的、充分的特征并不一定能完成图像重构。苏剑林
定义:对比学习是较为典型的无监督or自监督学习,其常见的主要思想是模型能够更加重新的学习到编码器的特征:尽可能的缩小相似样本的距离,拉大正负样本的距离,这里可以理解为让聚类的界限更加明显。即:
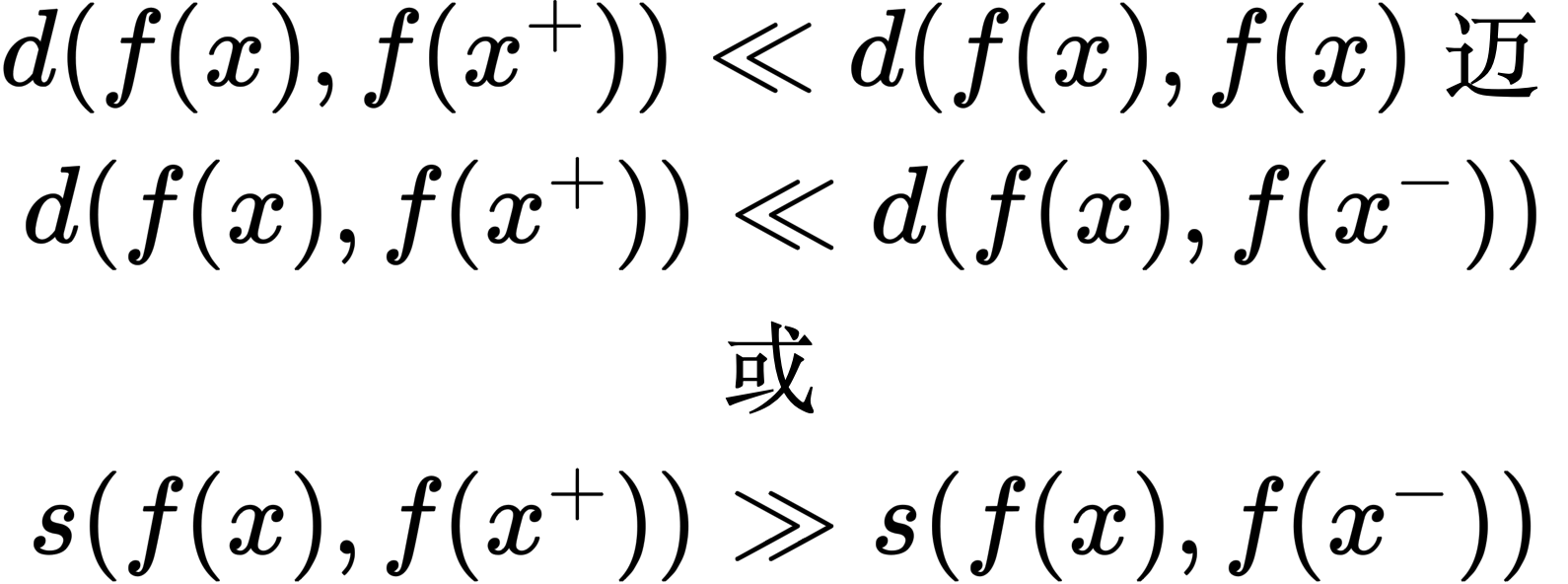
d表示欧式距离,s这里表示向量的内积,也就是余弦相似度。后文给出详细的解释。
给定一个锚点缩小与正样本间的距离,扩大与负样本间的距离,使正样本与锚点的距离远远小于负样本与锚点的距离,(或使正样本与锚点的相似度远远大于负样本与锚点的相似度),从而达到他们间原有空间分布的真实距离。

距离度量:欧几里得距离,余弦相似度,马氏距离,明氏距离等,自行选择
这里讲的锚点:其实就是一个参照点。
对比学习的损失函数
互信息
在预测未来信息时,我们将目标x(预测)和上下文c(已知)编码成一个紧凑的分布式向量表示(通过非线性学习映射),其方式最大限度地保留了定义为的原始信号x和c的互信息。公式定义如下:
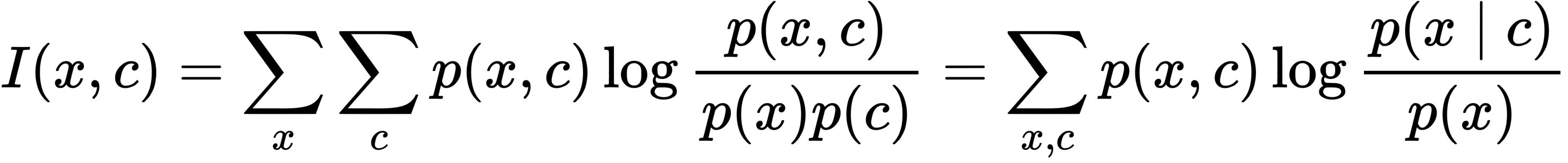
通过最大化编码之间互信息(它以输入信号之间的MI为界),提取输入中的隐变量。
互信息往往是算不出来的,但是我们这里将他进行估计,通过不同方法进行估计,从而衍生出自监督的两种方式:生成式和对比式。
互信息上界估计:减少互信息,即VAE的目标。
互信息下界估计:增加互信息,即对比学习(CL)的目标。后来也有CLUB上界估计和下界估计一起使用的对比学习。
互信息就是在知道c的条件下,x的信息减少量,在对比损失的场景下,我们希望互信息越大越好。详细可以参考【这篇知乎】
infoNCE loss
如果对最大化互信息的目标进行推导无监督特征提取,就会得到对比学习的loss(也称InfoNCE),其核心是通过计算样本表示间的距离,拉近正样本,拉远负样本。也就是说,当我们能够区分该样本的正负例时,得到的表示就够用了。
在对比学习的场景下,我们希望选定的锚点与其相似的样本的内积尽可能的小,与其相反的样本的内积越大越好(内积度量两个样本的相似性),
infoNCE是在Representation Learning with Contrastive Predictive Coding这篇文章提出的。定义的公式如下:
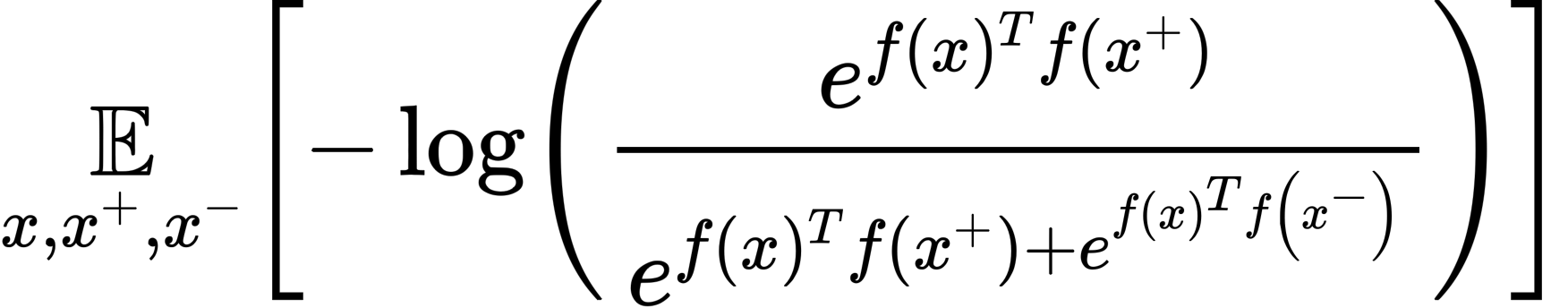
怎么理解这个损失函数?假设样本中只有一个正例,其余都是负例,此时这个公式不就是一个softmax~本质上变成了一个多分类的问题。依靠NCE来计算损失函数(和学习词嵌入方式类似),从而可以对整个模型进行端到端的训练。另外对于多模态的数据有可以学到高级信息。CPC这篇文章主要是在语音序列进行的实验,增加了噪声样本作为数据增强的正例。
详细内容可以直接看paper,这篇文章对笔者来说有点难搞,后面会再看看~

- 论文标题:Representation Learning with Contrastive Predictive Coding
- 论文链接:arxiv.org/abs/1807.0374
- 代码链接:github.com/davidtellez/
对比学习研究进展cv篇
MoCo
- 论文标题:Momentum Contrast for Unsupervised Visual Representation Learning
- 论文链接:arxiv.org/abs/1911.0572
- 代码链接:github.com/facebookrese
MoCo系列是何凯明大神提出的,受NLP任务的启发,MoCo将图片数据分别编码成查询向量和键向量,即,查询 q 与键队列k ,队列包含单个正样本和多个负样本。通过对比损失来学习特征表示。
主线依旧是不变的:在训练过程中尽量提高每个查询向量与自己相对应的键向量的相似度,同时降低与其他图片的键向量的相似度。
MoCo使用两个神经网络对数据进行编码:encoder和momentum encoder。
- encoder负责编码当前实例的抽象表示。
- momentum encoder负责编码多个实例(包括当前实例)的抽象表示。
对于当前实例,最大化其encoder与momentum encoder中自身的编码结果,同时最小化与momentum encoder中其他实例的编码结果。 - Memory Bank
MoCo保留了Memory Bank,同时也对此进行了改进,因为其存在一个重要的问题“新旧候选样本编码不一致的问题”。
由于对比学习的特性,参与对比学习损失的实例数往往越多越好,但Memory Bank中存储的都是 encoder 编码的特征,容量很大,导致采样的特征具有不一致性(是由不同的encoder产生的)。所以,对所有参与过momentum encoder的实例建立动态字典(dynamic dictionary)作为Memory Bank,在之后训练过程中每一个batch会淘汰掉字典中最早被编码的数据。
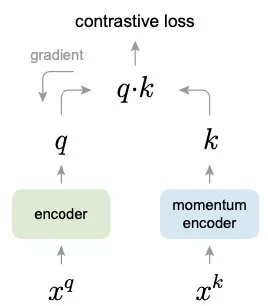
- Momentum 更新
在参数更新阶段,MOCO在设计的时候只会对encoder中的参数进行更新。大多数对比学习的idea都是只对encoder中的参数进行更新。
由于Memory Bank,导致引入大量实例的同时,会使反向传播十分困难,而momentum encoder参数更新就依赖于Momentum 更新法,使momentum encoder的参数逐步向encoder参数逼近:
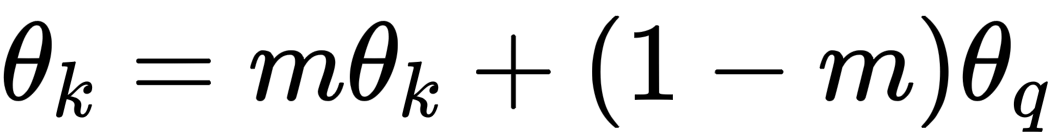
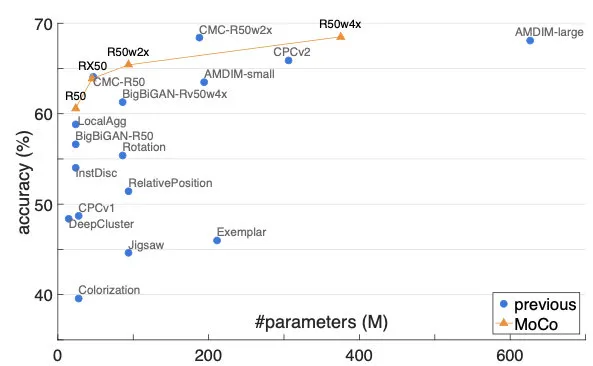
这样每次入队的新编码都是上一步更新后的编码器输出,以很低的速度慢慢迭代,与旧编码尽量保持一致。实验发现,theta=0.999时比theta=0.9好上很多。最终在ImageNet的实验效果也远超前人,成为当时的SOTA:
simCLR
- 论文标题:A Simple Framework for Contrastive Learning of Visual Representations
- 论文链接:arxiv.org/abs/2002.0570
- 代码链接:github.com/google-resea
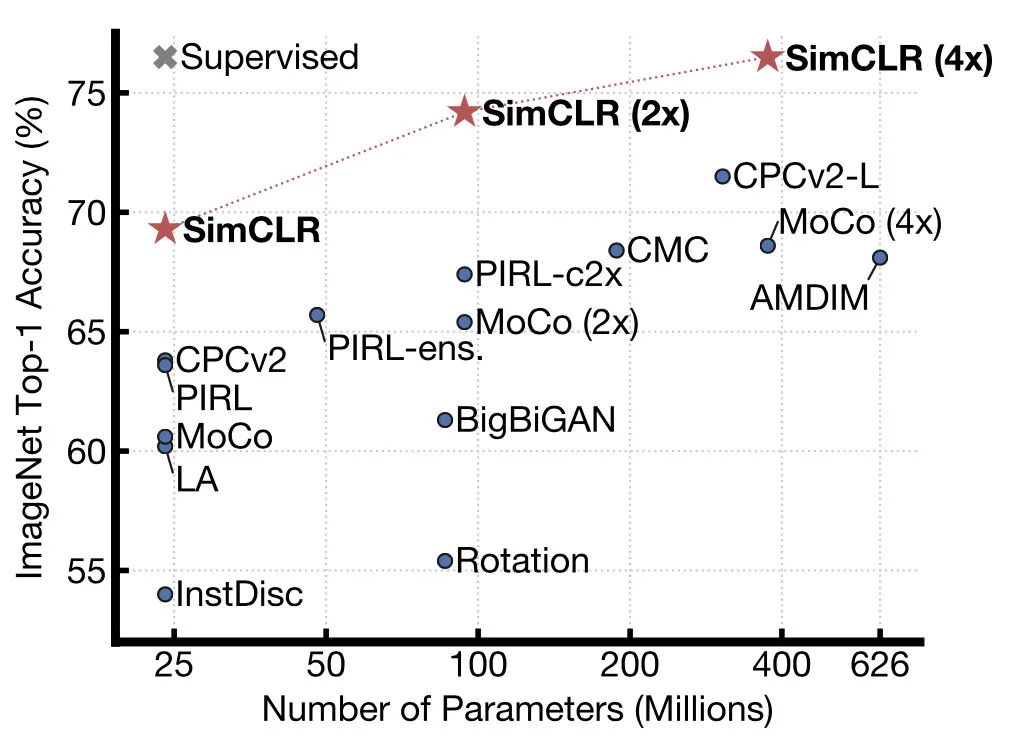
这篇是基于负例的对比学习,由hinton的学生提出,实验效果直接比moco高了7个点。SimCLR不采用memory bank,而是选用了更大的batchsize,以及构造更多的负例。
SimCLR如何构造正例和负例呢?

如何构造对比学习的正负例。对于某张图片图片,我们从可能的增强操作集合图片中,随机抽取两种:图片t1及图片t2(笔者这里不会用这个编辑器打希腊字母),分别作用在原始图像上,形成两张经过增强的新图像图片,两者互为正例。训练时,Batch内任意其它图像,都可做为图片或图片的负例。
idea非常的简单:通过数据增强的样本作为相似样本,任意的其他样本作为负例,这里也是后面simCSE主要思想,只不过在文本领域,有独特的数据增强方法。
这样,对比学习希望习得某个表示模型,它能够将图片映射到某个投影空间,并在这个空间内拉近正例的距离,推远负例距离。也就是说,迫使表示模型能够忽略表面因素,学习图像的内在一致结构信息,即学会某些类型的不变性,比如遮挡不变性、旋转不变性、颜色不变性等。SimCLR证明了,如果能够同时融合多种图像增强操作,增加对比学习模型任务难度,对于对比学习效果有明显提升作用。
有了正例和负例,接下来需要做的是:构造一个表示学习系统,通过它将训练数据投影到某个表示空间内,并采取一定的方法,使得正例距离能够比较近,负例距离比较远。在这个对比学习的指导原则下,我们来看SimCLR是如何构造表示学习系统的。AINLP
SimCLR模型的整体结构。它由对称的上下两个分枝(Branch)构成,是一种典型的双塔模型。不过图像领域不这么叫,一般叫Branch。随机从无标训练数据中取n个构成一个batch,对于每个batch里的任意图像,根据数据增强的方法构造正例,形成两个图像增强视图:aug1和aug2。aug1 和aug2各自包含n个增强数据,并分别经过上下两个分枝,对增强图像做非线性变换,这两个分枝就是SimCLR设计出的表示学习所需的投影函数,负责将图像数据投影到某个表示空间。
因为上下分枝是对称的,所以这里仅用aug1所经过的上分枝来介绍投影过程。aug1首先经过特征编码器encoder(cv这里一般采用ResNet做为模型结构),经CNN转换成对应的特征表示图片。紧随其后,是另外一个非线性变换结构Projector(由[FC-BN-RELU-FC]两层MLP构成,这里以图片函数代表),进一步将特征表示图片映射成另外一个空间里的向量图片。这样,增强图像经过图片两次非线性变换,就将增强图像投影到了表示空间,下分枝的aug2过程类似。总之simCLR中得出的结论是batchsize越大越好,而且负例越多越好。具体的原理部分笔者不再赘述。详看paper。
SimCLR的batch-size也达到了8192,用了128块TPU,又是算力党的一大胜利。

MoCov2
SimCLR推出后一个月,何凯明团队对MoCo进行了一些小改动:
改进了数据增强方法
训练时在encoder的表示上增加了相同的非线性层
为了对比,学习率采用SimCLR的cosine衰减
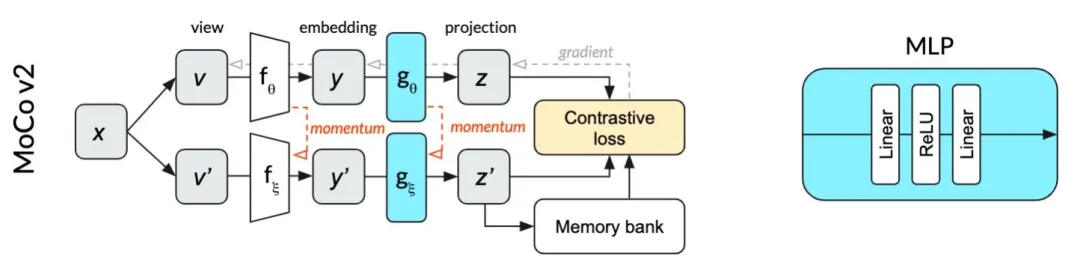
而改进后的效果也超过了simCLR.
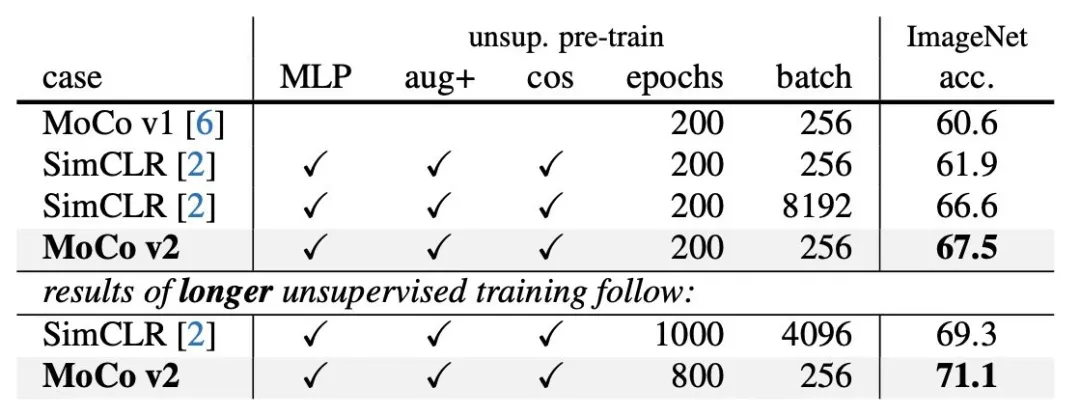
是不是有种神仙打架的赶脚~有内味了
后续simCLR v2,v3,Moco v3陆续推出,笔者还没来得及看,将在下一篇ttc中呈现(可以知音楼催更~push笔者)
对比学习研究进展NLP篇
simCSE
论文题目:https://github.com/princeton-nlp/SimCSE
论文地址:https://arxiv.org/pdf/2104.08821.pdf
论文代码:SimCSE: Simple Contrastive Learning of Sentence Embeddings
同样也是基于负例的对比学习~simCLR在cv上的骚操作在NLP上发挥的淋漓尽至。

句子向量表示也是nlp领域的一个大热门,从前段时间的BERT-Flow, BERT-whitening到最近的这个SimCSE。让笔者终于认识到句向量的重要性。
BERT-Flow以及BERT-whitenning其实像是后处理,将bert的输出进行一定的处理来解决各向异性的问题。
SIMCSE的这个工作则是采用了自监督来提升模型的句子表示能力,说到自监督最关键的问题应该就是如何构建正负例了。simcse的正负例有两种构建方式,对于无监督来说,作者使用了Droupout来构建正例(其实就是一种数据增强的方法),将一个样本经过encoder两次,就得到了一个正例对,负例则是同一个batch里的其它句子。而对于有监督则采用了SNLI数据集天然的结构,对立类别的是负例,另外两个类别的就是正例。没错就是如此简单的方法催生了新的SOTA,而且提升还非常的明显,下面就详细的讲一下细节。
SimCSE模型主要分为两大块,一个是无监督的部分,一个是有监督的部分。整体结构如下图所示:
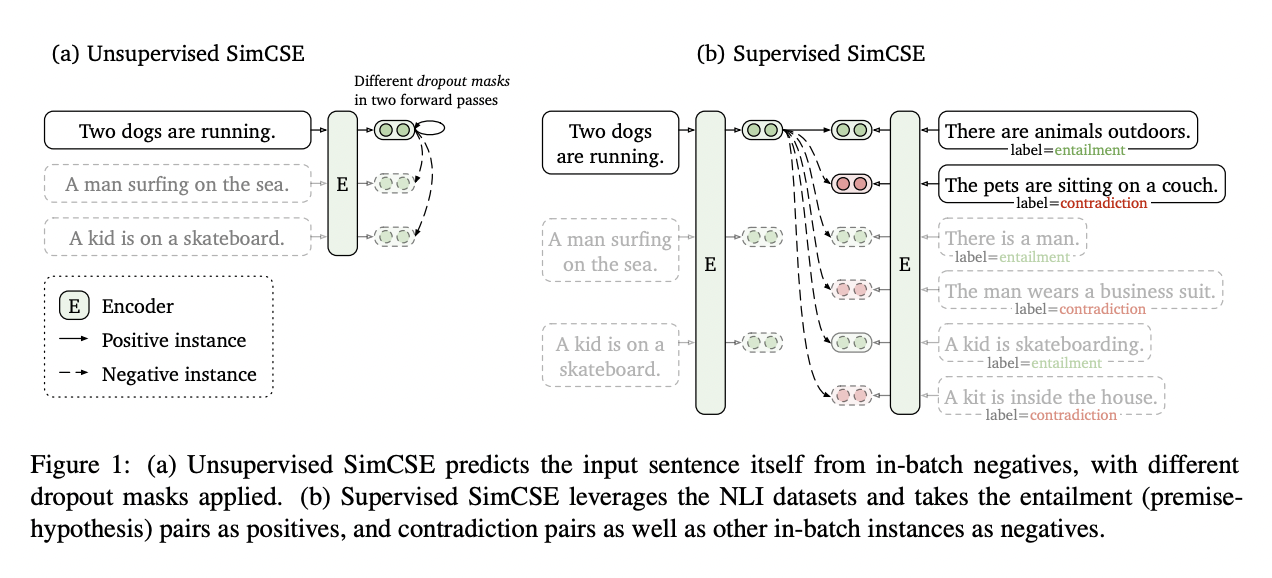
无监督部分
对于无监督的部分,最核心的创新点就是使用droupout来对文本增加噪音,从而构造一个正样本对,而负样本对则是在batch中选取的其它句子。和simCLR的idea是何其相似。其实对于图像任务来说,做数据增强其实非常简单,有各种的手段。但是对于NLP任务来说,传统的方法有词替,裁剪以及回译,但是作者发现这些方法都没有简单的dropout效果好。结果如下:
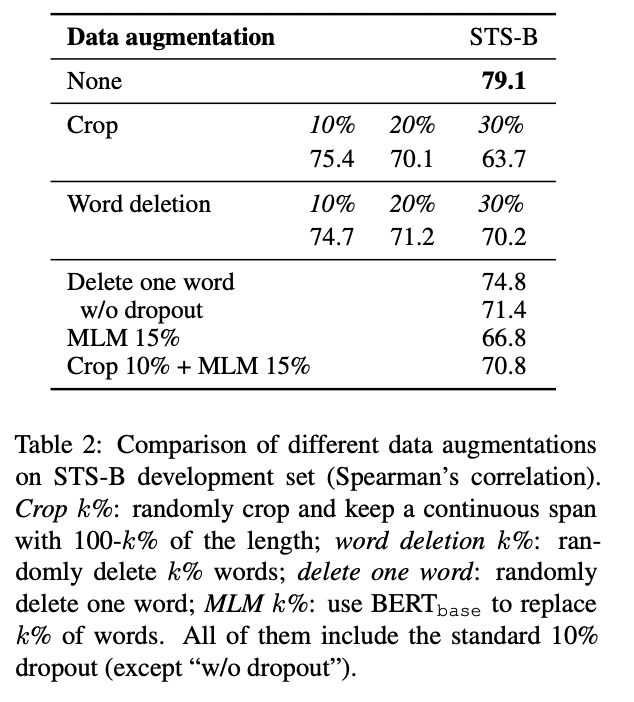
此外这篇文章提出了uniform和align两个值是用来衡量向量表示的质量。当然了这并不是这篇论文最早提出的,最早提出这两个概念的可以追溯到这篇文章:Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere感兴趣的可以读读。

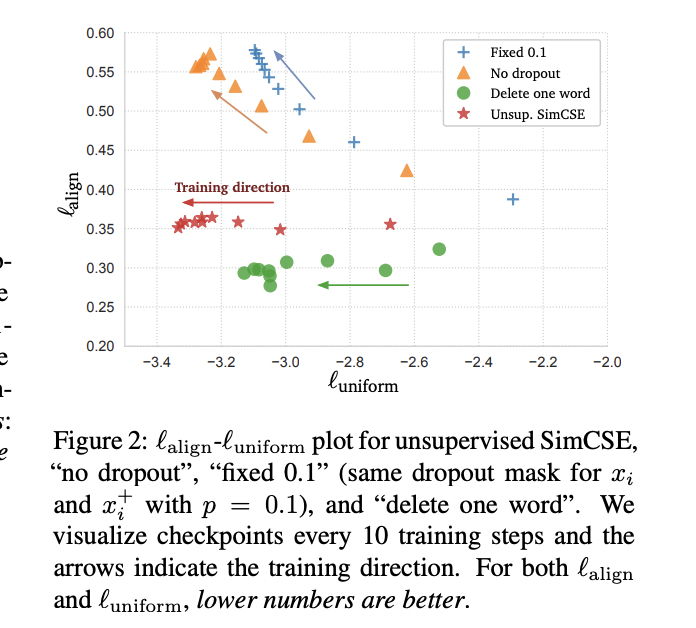
alignment计算了句子对距离的期望,而uniformity则用来衡量向量的分布是否一致。从上图的对比可以看出SimCSE在保证align稳定的同时,能更多的提高uniform。
有监督部分
另外一部分就是有监督的模型了,这一部分的句子对直接采用了NLI数据集的数据,因为其中有天然的正负例句子对。作者也做了试验选取了效果最好的数据集,结果如下:
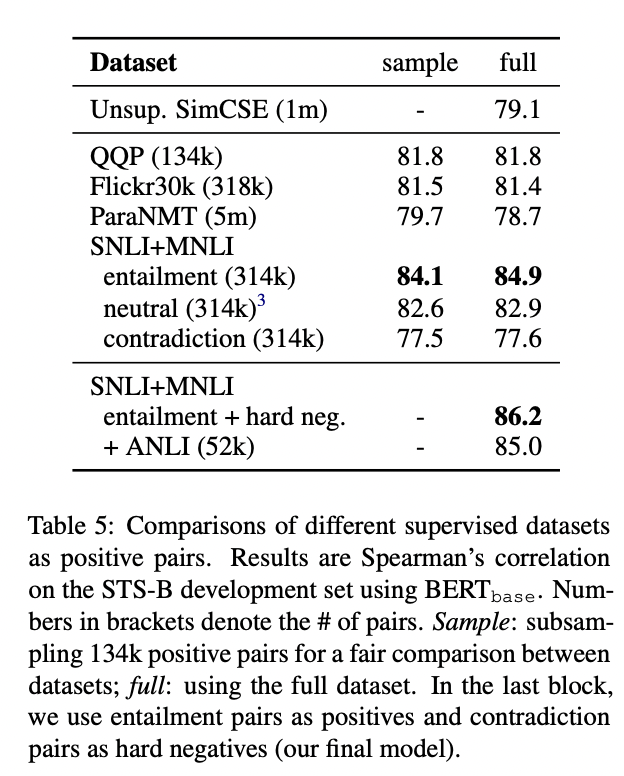
从结果可以看出来效果最好的是使用SNLI+MNLI数据集训练的,而且结果要比无监督的高出不少。其中的hard neg是使用NLI数据集中的contradiction作为负例,所以整体的优化公式也是infoNCE,公式如下:
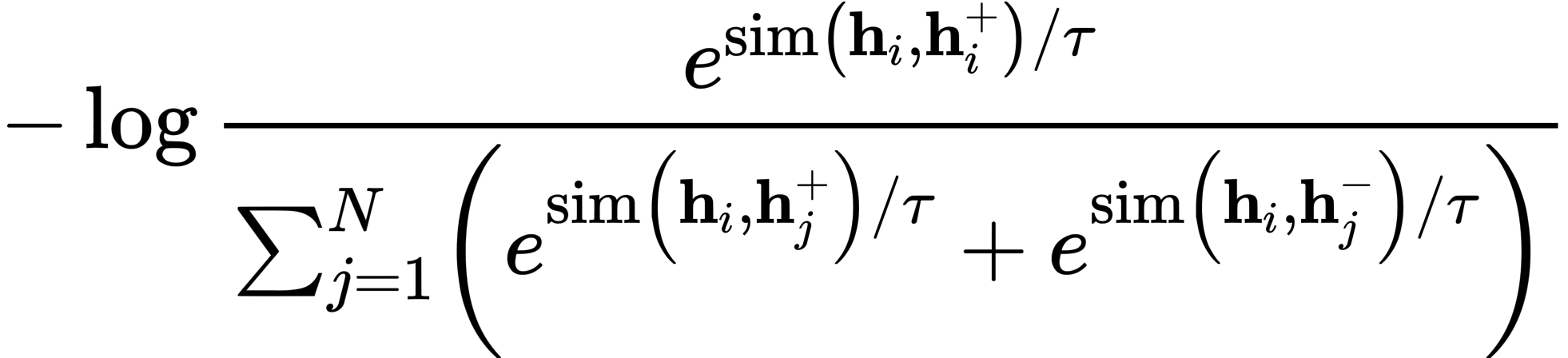
所以纵观这篇文章的创新性其实并不强,但是效果绝绝子~~
Anisotropy
在这里作者还对最近提出的文本表示各向异性的现象做出了说明,总体来说就是由于各向异性的存在导致了文本表示能力大打折扣。前面提到的flow和whitening都是采用后处理的方式将数据分布变成各向同性的。而本文则是使用了对比学习来保证正例间的相似以及负例间的疏远,从而解决了文本表示退化的问题。文中有详细的公式推导以及证明,感兴趣的大家可以自己去看。
实验效果
在文本相似度上的实验基本上全部sota
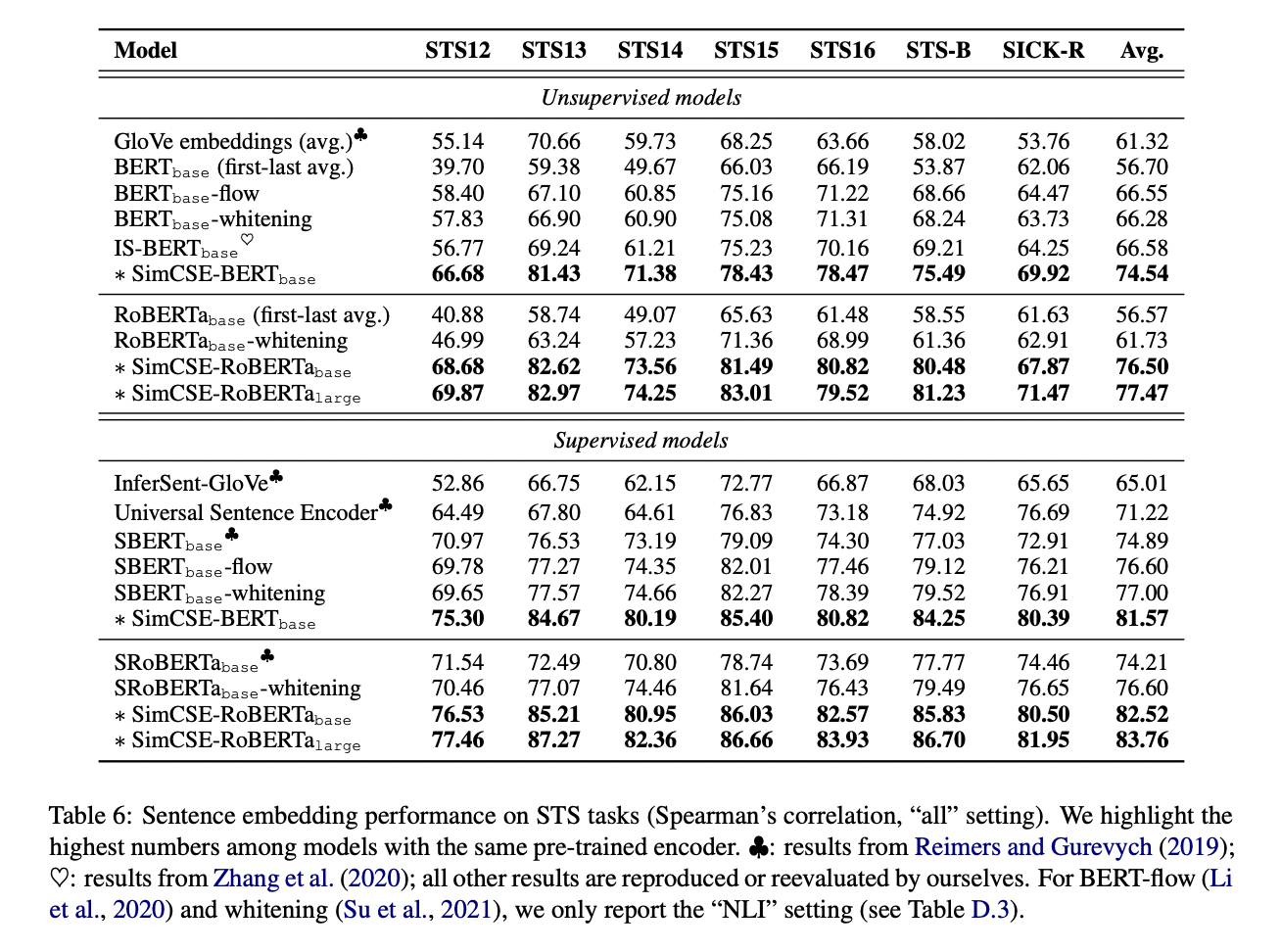
同样作者也做了下游任务的finetune,此处略,感兴趣请自行去看paper
模型测试
笔者这里直接调预训练模型做了一个小小的测试,感觉效果很不错的样子
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer.from_pretrained("princeton-nlp/sup-simcse-bert-base-uncased")
model = AutoModel.from_pretrained("princeton-nlp/sup-simcse-bert-base-uncased")
# Tokenize input texts
texts = [
"马云说本周六要来京和高文欣会面",
"马云计划周六在北京会见高文欣",
"马云周六没空"
]
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
# Get the embeddings
with torch.no_grad():
embeddings = model(**inputs, output_hidden_states=True, return_dict=True).pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine(embeddings[0], embeddings[1])
cosine_sim_0_2 = 1 - cosine(embeddings[0], embeddings[2])
print("Cosine similarity between "%s" and "%s" is: %.3f" % (texts[0], texts[1], cosine_sim_0_1))
print("Cosine similarity between "%s" and "%s" is: %.3f" % (texts[0], texts[2], cosine_sim_0_2))
效果

对于对比学习领域,笔者的学习不算全面,也请各位卷友批评指正~
注:表情包图来源于网络
其他图来源于对应的paper
参考文献
1.https://mp.weixin.qq.com/s/aficf_CWWEWv2D3pCV2R_g
2.https://mp.weixin.qq.com/s/0JXDKJ1veNbNdbrxjibxhQ
3.https://mp.weixin.qq.com/s/f9yRra5RS1QZ4KXOt74PRg
4.https://mp.weixin.qq.com/s/1SAITLGlyVJJigFDzG4eqQ
5.https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html
6.https://mp.weixin.qq.com/s/6qqFAQBaOFuXtaeRSmQgsQ