梯度消失和梯度爆炸的解决之道
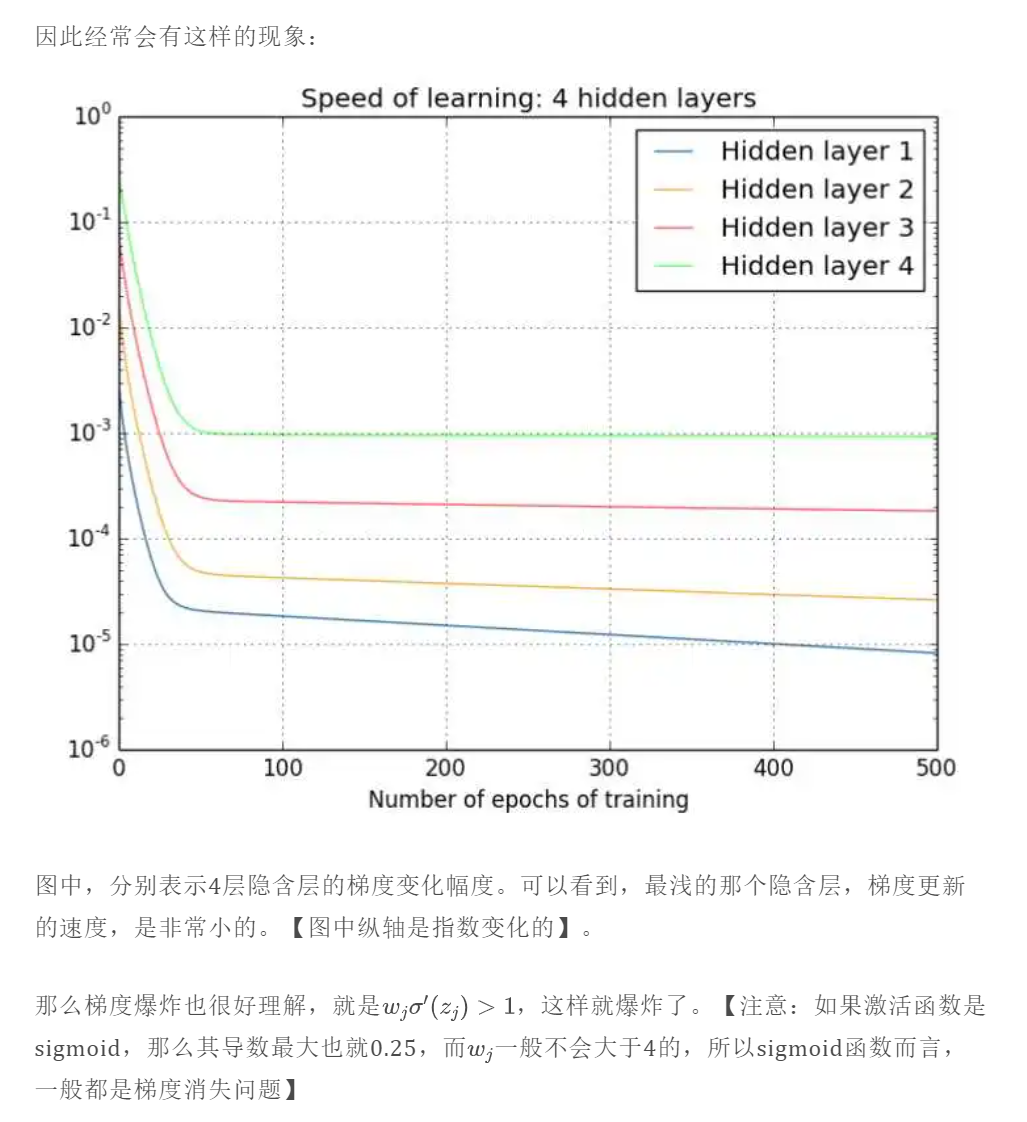
因为梯度不稳定,因此产生梯度消失和梯度爆炸的问题
出现原因
梯度消失和梯度爆炸是指前面几层的梯度,因为链式法则不断乘小于(大于)1的数,导致梯度非常小(大)的现象;
sigmoid导数最大0.25,一般都是梯度消失问题。
两者出现原因都是因为链式法则。当模型的层数过多的时候,计算梯度的时候就会出现非常多的乘积项。用下面这个例子来理解:

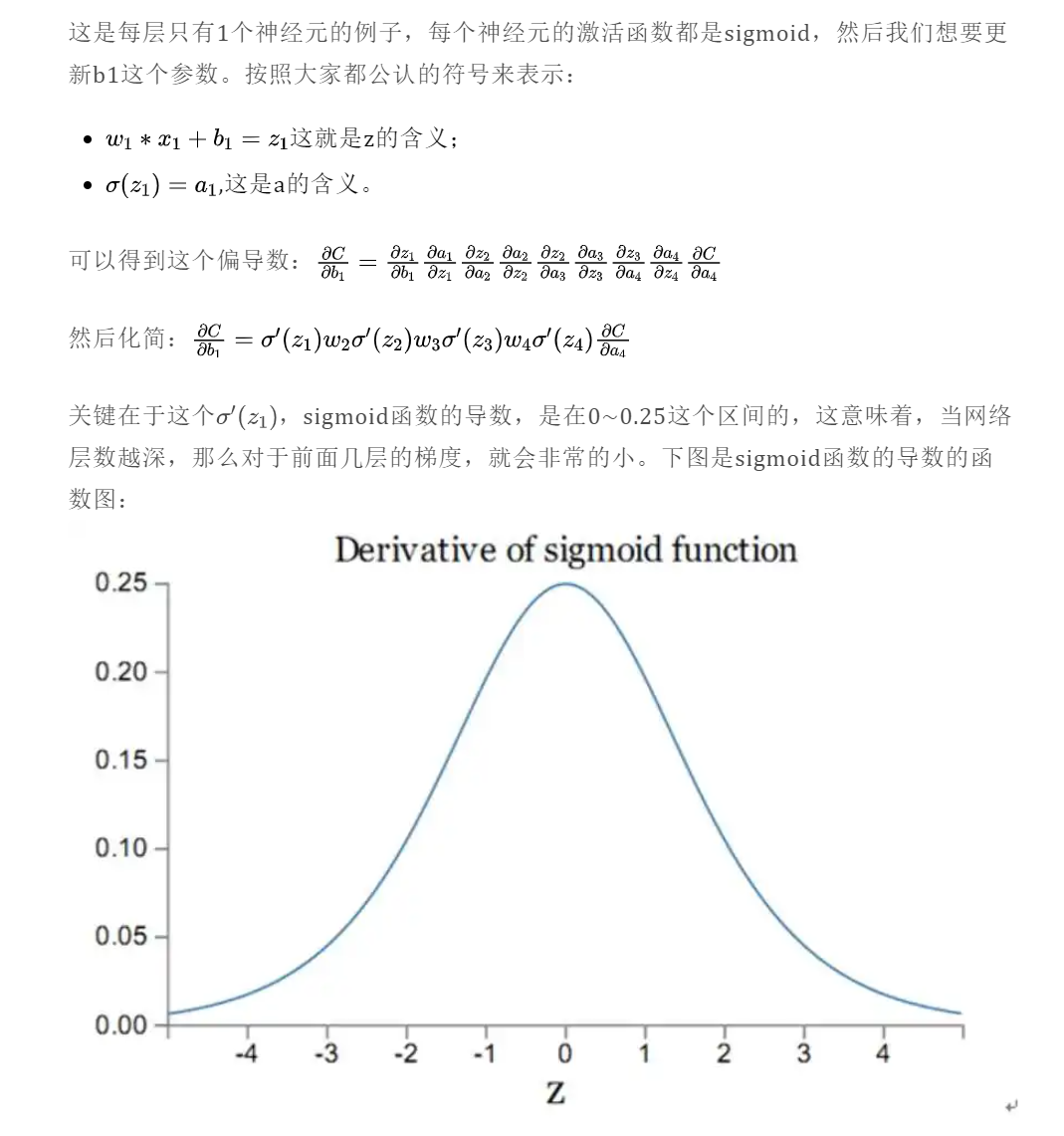
这里还可以说一句sigmoid是饱和函数,它是有届的
解决方法
更改激活函数
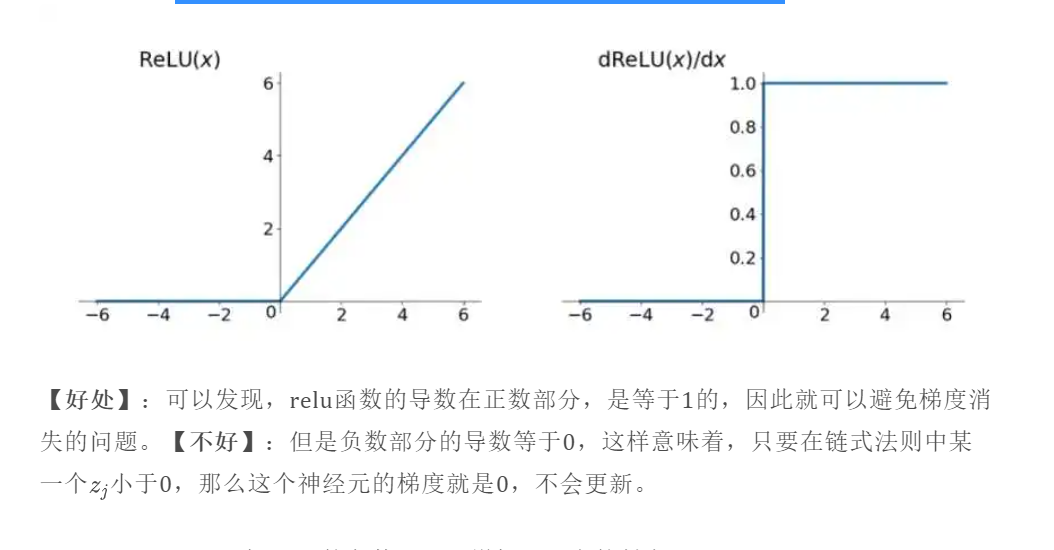
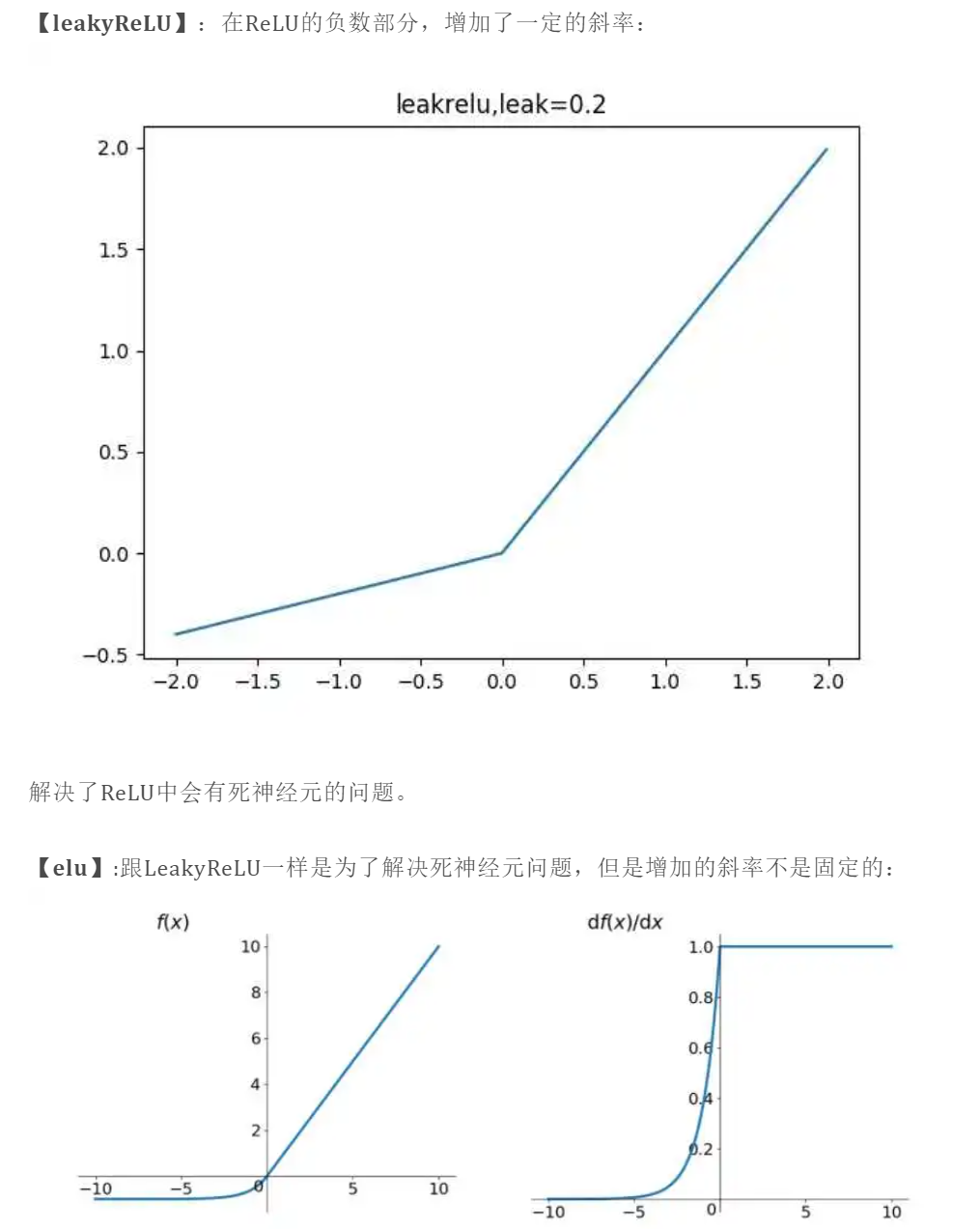
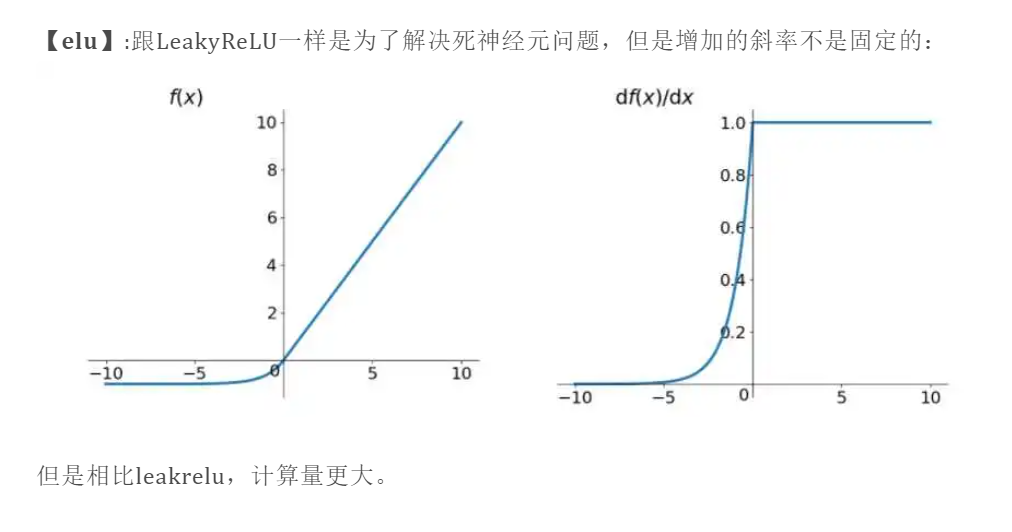
最常见的方案就是更改激活函数,现在神经网络中,除了最后二分类问题的最后一层会用sigmoid之外,每一层的激活函数一般都是用ReLU。
如果激活函数的导数是1,那么就没有梯度爆炸问题了。
增加batchnorm层
这个是非常给力的成功,在图像处理中必用的层了。BN层提出来的本质就是为了解决反向传播中的梯度问题。
在神经网络中,有这样的一个问题:Internal Covariate Shift。假设第一层的输入数据经过第一层的处理之后,得到第二层的输入数据。这时候,第二层的输入数据相对第一层的数据分布,就会发生改变,所以这一个batch,第二层的参数更新是为了拟合第二层的输入数据的那个分布。然而到了下一个batch,因为第一层的参数也改变了,所以第二层的输入数据的分布相比上一个batch,又不太一样了。然后第二层的参数更新方向也会发生改变。层数越多,这样的问题就越明显。
但是为了保证每一层的分布不变的话,那么如果把每一层输出的数据都归一化0均值,1方差不就好了?但是这样就会完全学习不到输入数据的特征了。不管什么数据都是服从标准正太分布,想想也会觉得有点奇怪。所以BN就是增加了两个自适应参数,可以通过训练学习的那种参数。这样把每一层的数据都归一化到均值,标准差的正态分布上。
【将输入分布变成正态分布,是一种去除数据绝对差异,扩大相对差异的一种行为,所以BN层用在分类上效果的好的。对于Image-to-Image这种任务,数据的绝对差异也是非常重要的,所以BN层可能起不到相应的效果。】
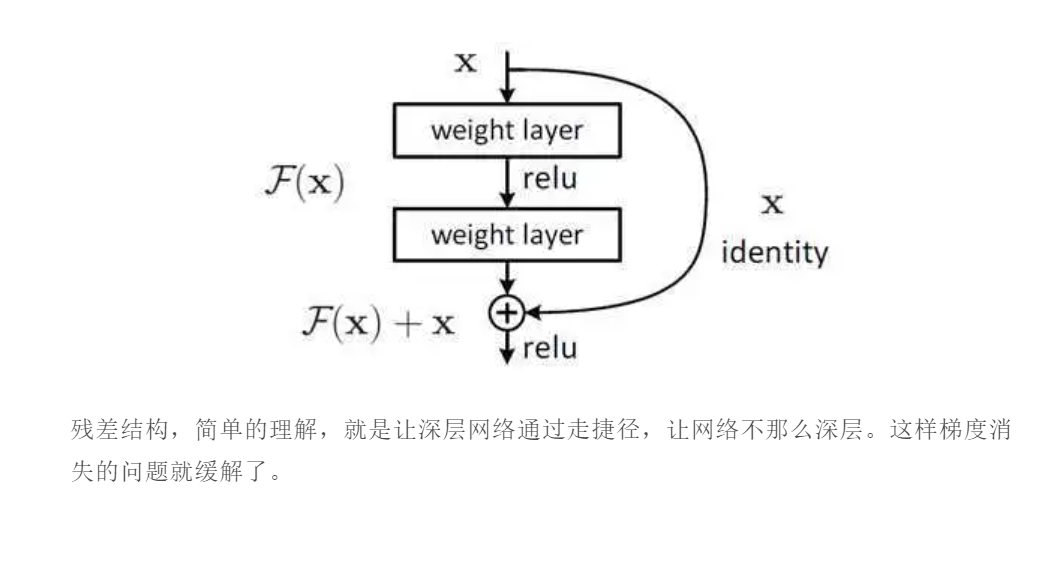
增加残差结构
L2正则化
之前提到的梯度爆炸问题,一般都是因为(w_j)过大造成的,那么用L2正则化就可以解决问题。
另外一种解决梯度爆炸的手段是采用权重正则化(weithts regularization),正则化主要是通过对网络权重做正则来限制过拟合。如果发生梯度爆炸,那么权值就会变的非常大,反过来,通过正则化项来限制权重的大小,也可以在一定程度上防止梯度爆炸的发生。比较常见的是 L1 正则和 L2 正则,在各个深度框架中都有相应的API可以使用正则化。
换网络结构
比如换成lstm