keras
Keras 函数式 API
Keras 函数式 API 是定义复杂模型(如多输出模型、有向无环图,或具有共享层的模型)的方法。
keras有两种方式,一种是sequence方式,直接add层即可,另一种使API的形式,个人觉得各有优势,后者更好自定义,本文主要介绍后者
利用函数式 API,可以轻易地重用训练好的模型:可以将任何模型看作是一个层,然后通过传递一个张量来调用它。注意,在调用模型时,您不仅重用模型的结构,还重用了它的权重。
据说是菜鸡入门dl最好的包了
全连接神经网络
全连接网络
Sequential 模型可能是实现这种网络的一个更好选择,但这个例子能够帮助我们进行一些简单的理解。
网络层的实例是可调用的,它以张量为参数,并且返回一个张量
输入和输出均为张量,它们都可以用来定义一个模型(Model)
这样的模型同 Keras 的 Sequential 模型一样,都可以被训练
from keras.layers import Input, Dense
from keras.models import Model
# 这部分返回一个张量
inputs = Input(shape=(784,))
# 层的实例是可调用的,它以张量为参数,并且返回一个张量
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x)
# 这部分创建了一个包含输入层和三个全连接层的模型
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels) # 开始训练
所有的模型都可调用,就像网络层一样
利用函数式 API,可以轻易地重用训练好的模型:可以将任何模型看作是一个层,然后通过传递一个张量来调用它。注意,在调用模型时,您不仅重用模型的结构,还重用了它的权重。
x = Input(shape=(784,))
# 这是可行的,并且返回上面定义的 10-way softmax。
y = model(x)
这种方式能允许我们快速创建可以处理序列输入的模型。只需一行代码,你就将图像分类模型转换为视频分类模型。
from keras.layers import TimeDistributed
# 输入张量是 20 个时间步的序列,
# 每一个时间为一个 784 维的向量
input_sequences = Input(shape=(20, 784))
# 这部分将我们之前定义的模型应用于输入序列中的每个时间步。
# 之前定义的模型的输出是一个 10-way softmax,
# 因而下面的层的输出将是维度为 10 的 20 个向量的序列。
processed_sequences = TimeDistributed(model)(input_sequences)
多输入多输出模型
以下是函数式 API 的一个很好的例子:具有多个输入和输出的模型。函数式 API 使处理大量交织的数据流变得容易。
来考虑下面的模型。我们试图预测 Twitter 上的一条新闻标题有多少转发和点赞数。模型的主要输入将是新闻标题本身,即一系列词语,但是为了增添趣味,我们的模型还添加了其他的辅助输入来接收额外的数据,例如新闻标题的发布的时间等。 该模型也将通过两个损失函数进行监督学习。较早地在模型中使用主损失函数,是深度学习模型的一个良好正则方法。
这里我先从官网截图,后面再画
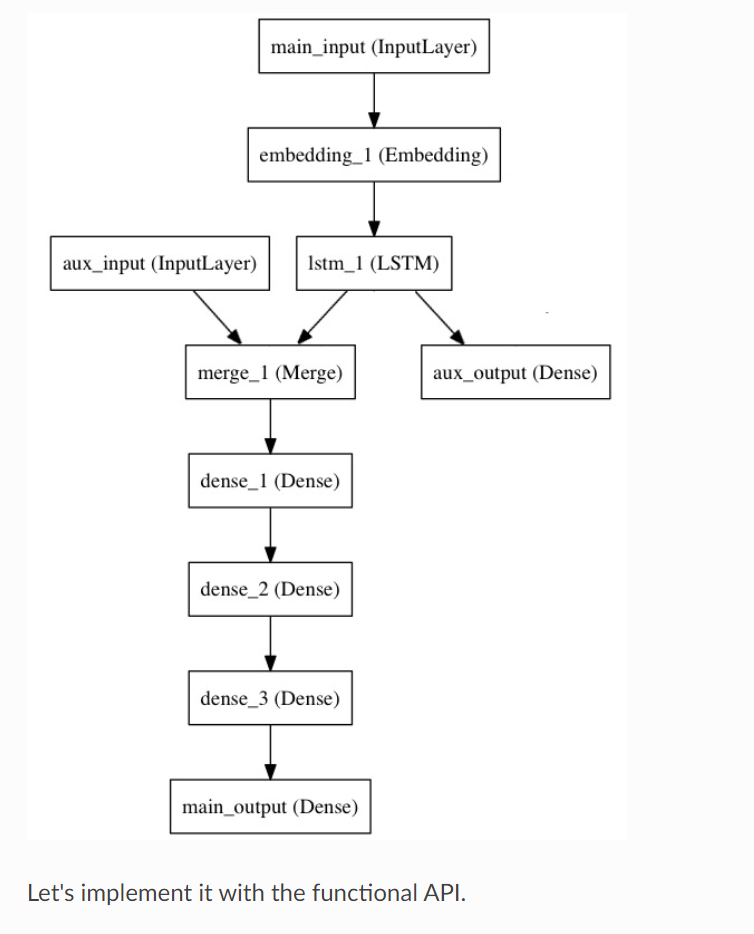
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model
# 标题输入:接收一个含有 100 个整数的序列,每个整数在 1 到 10000 之间。
# 注意我们可以通过传递一个 "name" 参数来命名任何层。
main_input = Input(shape=(100,), dtype='int32', name='main_input')
# Embedding 层将输入序列编码为一个稠密向量的序列,
# 每个向量维度为 512。
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# LSTM 层把向量序列转换成单个向量,
# 它包含整个序列的上下文信息
lstm_out = LSTM(32)(x)
在这里,我们插入辅助损失,使得即使在模型主损失很高的情况下,LSTM 层和 Embedding 层都能被平稳地训练。
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
此时,我们将辅助输入数据与 LSTM 层的输出连接起来,输入到模型中:
auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_input])
# 堆叠多个全连接网络层
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# 最后添加主要的逻辑回归层
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
然后定义一个具有两个输入和两个输出的模型:
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
现在编译模型,并给辅助损失分配一个 0.2 的权重。如果要为不同的输出指定不同的 loss_weights 或 loss,可以使用列表或字典。 在这里,我们给 loss 参数传递单个损失函数,这个损失将用于所有的输出。
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2])
我们可以通过传递输入数组和目标数组的列表来训练模型:
model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32)
由于输入和输出均被命名了(在定义时传递了一个 name 参数),我们也可以通过以下方式编译模型:
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2})
# 然后使用以下方式训练:
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': labels, 'aux_output': labels},
epochs=50, batch_size=32)
共享网络层
函数式 API 的另一个用途是使用共享网络层的模型。我们来看看共享层。
来考虑推特推文数据集。我们想要建立一个模型来分辨两条推文是否来自同一个人(例如,通过推文的相似性来对用户进行比较)。
实现这个目标的一种方法是建立一个模型,将两条推文编码成两个向量,连接向量,然后添加逻辑回归层;这将输出两条推文来自同一作者的概率。模型将接收一对对正负表示的推特数据。
由于这个问题是对称的,编码第一条推文的机制应该被完全重用来编码第二条推文(权重及其他全部)。这里我们使用一个共享的 LSTM 层来编码推文。
让我们使用函数式 API 来构建它。首先我们将一条推特转换为一个尺寸为 (280, 256) 的矩阵,即每条推特 280 字符,每个字符为 256 维的 one-hot 编码向量 (取 256 个常用字符)。
import keras
from keras.layers import Input, LSTM, Dense
from keras.models import Model
tweet_a = Input(shape=(280, 256))
tweet_b = Input(shape=(280, 256))
要在不同的输入上共享同一个层,只需实例化该层一次,然后根据需要传入你想要的输入即可:
# 这一层可以输入一个矩阵,并返回一个 64 维的向量
shared_lstm = LSTM(64)
# 当我们重用相同的图层实例多次,图层的权重也会被重用 (它其实就是同一层)
encoded_a = shared_lstm(tweet_a)
encoded_b = shared_lstm(tweet_b)
# 然后再连接两个向量:
merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1)
# 再在上面添加一个逻辑回归层
predictions = Dense(1, activation='sigmoid')(merged_vector)
# 定义一个连接推特输入和预测的可训练的模型
model = Model(inputs=[tweet_a, tweet_b], outputs=predictions)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit([data_a, data_b], labels, epochs=10)
层「节点」的概念
每当你在某个输入上调用一个层时,都将创建一个新的张量(层的输出),并且为该层添加一个「节点」,将输入张量连接到输出张量。当多次调用同一个图层时,该图层将拥有多个节点索引 (0, 1, 2...)。
在之前版本的 Keras 中,可以通过 layer.get_output() 来获得层实例的输出张量,或者通过 layer.output_shape 来获取其输出形状。现在你依然可以这么做(除了 get_output() 已经被 output 属性替代)。但是如果一个层与多个输入连接呢?
只要一个层仅仅连接到一个输入,就不会有困惑,.output 会返回层的唯一输出:
a = Input(shape=(280, 256))
lstm = LSTM(32)
encoded_a = lstm(a)
assert lstm.output == encoded_a
但是如果该层有多个输入,那就会出现问题:
a = Input(shape=(280, 256))
b = Input(shape=(280, 256))
lstm = LSTM(32)
encoded_a = lstm(a)
encoded_b = lstm(b)
lstm.output
>> AttributeError: Layer lstm_1 has multiple inbound nodes,
hence the notion of "layer output" is ill-defined.
Use `get_output_at(node_index)` instead.
好吧,通过下面的方法可以解决:
assert lstm.get_output_at(0) == encoded_a
assert lstm.get_output_at(1) == encoded_b
够简单,对吧?
input_shape 和 output_shape 这两个属性也是如此:只要该层只有一个节点,或者只要所有节点具有相同的输入/输出尺寸,那么「层输出/输入尺寸」的概念就被很好地定义,并且将由 layer.output_shape / layer.input_shape 返回。但是比如说,如果将一个 Conv2D 层先应用于尺寸为 (32,32,3) 的输入,再应用于尺寸为 (64, 64, 3) 的输入,那么这个层就会有多个输入/输出尺寸,你将不得不通过指定它们所属节点的索引来获取它们:
a = Input(shape=(32, 32, 3))
b = Input(shape=(64, 64, 3))
conv = Conv2D(16, (3, 3), padding='same')
conved_a = conv(a)
# 到目前为止只有一个输入,以下可行:
assert conv.input_shape == (None, 32, 32, 3)
conved_b = conv(b)
# 现在 `.input_shape` 属性不可行,但是这样可以:
assert conv.get_input_shape_at(0) == (None, 32, 32, 3)
assert conv.get_input_shape_at(1) == (None, 64, 64, 3)
keras.layers.xxx
视觉问答模型
当被问及关于图片的自然语言问题时,该模型可以选择正确的单词作答。
它通过将问题和图像编码成向量,然后连接两者,在上面训练一个逻辑回归,来从词汇表中挑选一个可能的单词作答。
from keras.layers import Conv2D, MaxPooling2D, Flatten
from keras.layers import Input, LSTM, Embedding, Dense
from keras.models import Model, Sequential
# 首先,让我们用 Sequential 来定义一个视觉模型。
# 这个模型会把一张图像编码为向量。
vision_model = Sequential()
vision_model.add(Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=(224, 224, 3)))
vision_model.add(Conv2D(64, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
vision_model.add(Conv2D(128, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
vision_model.add(Conv2D(256, (3, 3), activation='relu'))
vision_model.add(Conv2D(256, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Flatten())
# 现在让我们用视觉模型来得到一个输出张量:
image_input = Input(shape=(224, 224, 3))
encoded_image = vision_model(image_input)
# 接下来,定义一个语言模型来将问题编码成一个向量。
# 每个问题最长 100 个词,词的索引从 1 到 9999.
question_input = Input(shape=(100,), dtype='int32')
embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=100)(question_input)
encoded_question = LSTM(256)(embedded_question)
# 连接问题向量和图像向量:
merged = keras.layers.concatenate([encoded_question, encoded_image])
# 然后在上面训练一个 1000 词的逻辑回归模型:
output = Dense(1000, activation='softmax')(merged)
# 最终模型:
vqa_model = Model(inputs=[image_input, question_input], outputs=output)
# 下一步就是在真实数据上训练模型。
# Create an input layer with 3 columns
这里的输入层是3列
input_tensor = Input((3,))
# Pass it to a Dense layer with 1 unit
output_tensor = Dense(1)(input_tensor)
# Create a model
model = Model(input_tensor, output_tensor)
# Compile the model
model.compile(optimizer='adam', loss='mean_absolute_error')
# Fit the model
# games_tourney_train[['home', 'seed_diff', 'pred']]==X
# games_tourney_train['score_diff']==y
model.fit(games_tourney_train[['home', 'seed_diff', 'pred']],
games_tourney_train['score_diff'],
epochs=1,
verbose=True)
# Evaluate the model on the games_tourney_test dataset
print(model.evaluate(games_tourney_test[['home', 'seed_diff', 'prediction']],
games_tourney_test['score_diff'], verbose=False))
model.evaluate与model.predict的区别
model.evaluate:输出预测值与真实值的loss
model.predict:输出预测值
layers
层的定义
Input&output
定义输入和输出层,并查看形状
keras.layers.input()
keras.layers.output()
layer.input_shape
layer.output_shape
查看结点信息
layer.get_input_at(node_index)
layer.get_output_at(node_index)
layer.get_input_shape_at(node_index)
layer.get_output_shape_at(node_index)
Dense层
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
常见问题
"sample", "batch", "epoch" 分别是什么?
为了正确地使用 Keras,以下是必须了解和理解的一些常见定义:
Sample: 样本,数据集中的一个元素,一条数据。
例1: 在卷积神经网络中,一张图像是一个样本。
例2: 在语音识别模型中,一段音频是一个样本。
Batch: 批,含有 N 个样本的集合。每一个 batch 的样本都是独立并行处理的。在训练时,一个 batch 的结果只会用来更新一次模型。
一个 batch 的样本通常比单个输入更接近于总体输入数据的分布,batch 越大就越近似。然而,每个 batch 将花费更长的时间来处理,并且仍然只更新模型一次。在推理(评估/预测)时,建议条件允许的情况下选择一个尽可能大的 batch,(因为较大的 batch 通常评估/预测的速度会更快)。
batch就是每次选取的样本个数
Epoch: 轮次,通常被定义为 「在整个数据集上的一轮迭代」,用于训练的不同的阶段,这有利于记录和定期评估。
当在 Keras 模型的 fit 方法中使用 validation_data 或 validation_split 时,评估将在每个 epoch 结束时运行。
在 Keras 中,可以添加专门的用于在 epoch 结束时运行的 callbacks 回调。例如学习率变化和模型检查点(保存)。
epoch就是迭代次数
如何保存 Keras 模型?
保存/加载整个模型(结构 + 权重 + 优化器状态)
不建议使用 pickle 或 cPickle 来保存 Keras 模型。
你可以使用 model.save(filepath) 将 Keras 模型保存到单个 HDF5 文件中,该文件将包含:
模型的结构,允许重新创建模型
模型的权重
训练配置项(损失函数,优化器)
优化器状态,允许准确地从你上次结束的地方继续训练。
你可以使用 keras.models.load_model(filepath) 重新实例化模型。load_model 还将负责使用保存的训练配置项来编译模型(除非模型从未编译过)。
例子:
from keras.models import load_model
model.save('my_model.h5') # 创建 HDF5 文件 'my_model.h5'
del model # 删除现有模型
# 返回一个编译好的模型
# 与之前那个相同
model = load_model('my_model.h5')
另请参阅如何安装 HDF5 或 h5py 以在 Keras 中保存我的模型?,查看有关如何安装 h5py 的说明。
只保存/加载模型的结构
如果您只需要保存模型的结构,而非其权重或训练配置项,则可以执行以下操作:
# 保存为 JSON
json_string = model.to_json()
# 保存为 YAML
yaml_string = model.to_yaml()
生成的 JSON/YAML 文件是人类可读的,如果需要还可以手动编辑。
你可以从这些数据建立一个新的模型:
# 从 JSON 重建模型:
from keras.models import model_from_json
model = model_from_json(json_string)
# 从 YAML 重建模型:
from keras.models import model_from_yaml
model = model_from_yaml(yaml_string)
只保存/加载模型的权重
如果您只需要 模型的权重,可以使用下面的代码以 HDF5 格式进行保存。
请注意,我们首先需要安装 HDF5 和 Python 库 h5py,它们不包含在 Keras 中。
model.save_weights('my_model_weights.h5')
假设你有用于实例化模型的代码,则可以将保存的权重加载到具有相同结构的模型中:
model.load_weights('my_model_weights.h5')
如果你需要将权重加载到不同的结构(有一些共同层)的模型中,例如微调或迁移学习,则可以按层的名字来加载权重:
model.load_weights('my_model_weights.h5', by_name=True)
例子:
"""
假设原始模型如下所示:
model = Sequential()
model.add(Dense(2, input_dim=3, name='dense_1'))
model.add(Dense(3, name='dense_2'))
...
model.save_weights(fname)
"""
# 新模型
model = Sequential()
model.add(Dense(2, input_dim=3, name='dense_1')) # 将被加载
model.add(Dense(10, name='new_dense')) # 将不被加载
# 从第一个模型加载权重;只会影响第一层,dense_1
model.load_weights(fname, by_name=True)
处理已保存模型中的自定义层(或其他自定义对象)
如果要加载的模型包含自定义层或其他自定义类或函数,则可以通过 custom_objects 参数将它们传递给加载机制:
from keras.models import load_model
# 假设你的模型包含一个 AttentionLayer 类的实例
model = load_model('my_model.h5', custom_objects={'AttentionLayer': AttentionLayer})
或者,你可以使用 自定义对象作用域:
from keras.utils import CustomObjectScope
with CustomObjectScope({'AttentionLayer': AttentionLayer}):
model = load_model('my_model.h5')
自定义对象的处理与 load_model, model_from_json, model_from_yaml 的工作方式相同:
from keras.models import model_from_json
model = model_from_json(json_string, custom_objects={'AttentionLayer': AttentionLayer})
embedding层
Embedding
keras.layers.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
将正整数(索引值)转换为固定尺寸的稠密向量。 例如: [[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]]
该层只能用作模型中的第一层。
例子
model = Sequential()
model.add(Embedding(1000, 64, input_length=10))
# 模型将输入一个大小为 (batch, input_length) 的整数矩阵。
# 输入中最大的整数(即词索引)不应该大于 999 (词汇表大小)
# 现在 model.output_shape == (None, 10, 64),其中 None 是 batch 的维度。
input_array = np.random.randint(1000, size=(32, 10))
model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
assert output_array.shape == (32, 10, 64)
参数
input_dim: int > 0。词汇表大小, 即,最大整数 index + 1。
output_dim: int >= 0。词向量的维度。
embeddings_initializer: embeddings 矩阵的初始化方法 (详见 initializers)。
embeddings_regularizer: embeddings matrix 的正则化方法 (详见 regularizer)。
embeddings_constraint: embeddings matrix 的约束函数 (详见 constraints)。
mask_zero: 是否把 0 看作为一个应该被遮蔽的特殊的 "padding" 值。 这对于可变长的 循环神经网络层 十分有用。 如果设定为 True,那么接下来的所有层都必须支持 masking,否则就会抛出异常。 如果 mask_zero 为 True,作为结果,索引 0 就不能被用于词汇表中 (input_dim 应该与 vocabulary + 1 大小相同)。
input_length: 输入序列的长度,当它是固定的时。 如果你需要连接 Flatten 和 Dense 层,则这个参数是必须的 (没有它,dense 层的输出尺寸就无法计算)。
输入尺寸
尺寸为 (batch_size, sequence_length) 的 2D 张量。
输出尺寸
尺寸为 (batch_size, sequence_length, output_dim) 的 3D 张量。
加减乘除
Add
keras.layers.Add()
计算输入张量列表的和。
它接受一个张量的列表, 所有的张量必须有相同的输入尺寸, 然后返回一个张量(和输入张量尺寸相同)。
例子
import keras
input1 = keras.layers.Input(shape=(16,))
x1 = keras.layers.Dense(8, activation='relu')(input1)
input2 = keras.layers.Input(shape=(32,))
x2 = keras.layers.Dense(8, activation='relu')(input2)
# 相当于 added = keras.layers.add([x1, x2])
added = keras.layers.Add()([x1, x2])
out = keras.layers.Dense(4)(added)
model = keras.models.Model(inputs=[input1, input2], outputs=out)
Subtract
keras.layers.Subtract()
计算两个输入张量的差。
它接受一个长度为 2 的张量列表, 两个张量必须有相同的尺寸,然后返回一个值为 (inputs[0] - inputs[1]) 的张量, 输出张量和输入张量尺寸相同。
例子
import keras
input1 = keras.layers.Input(shape=(16,))
x1 = keras.layers.Dense(8, activation='relu')(input1)
input2 = keras.layers.Input(shape=(32,))
x2 = keras.layers.Dense(8, activation='relu')(input2)
# 相当于 subtracted = keras.layers.subtract([x1, x2])
subtracted = keras.layers.Subtract()([x1, x2])
out = keras.layers.Dense(4)(subtracted)
model = keras.models.Model(inputs=[input1, input2], outputs=out)
Multiply
keras.layers.Multiply()
计算输入张量列表的(逐元素间的)乘积。
它接受一个张量的列表, 所有的张量必须有相同的输入尺寸, 然后返回一个张量(和输入张量尺寸相同)。
Average
keras.layers.Average()
计算输入张量列表的平均值。
它接受一个张量的列表, 所有的张量必须有相同的输入尺寸, 然后返回一个张量(和输入张量尺寸相同)。
Maximum
keras.layers.Maximum()
计算输入张量列表的(逐元素间的)最大值。
它接受一个张量的列表, 所有的张量必须有相同的输入尺寸, 然后返回一个张量(和输入张量尺寸相同)。
Concatenate
keras.layers.Concatenate(axis=-1)
连接一个输入张量的列表。
它接受一个张量的列表, 除了连接轴之外,其他的尺寸都必须相同, 然后返回一个由所有输入张量连接起来的输出张量。
参数
axis: 连接的轴。
**kwargs: 层关键字参数。
[source]
Dot
keras.layers.Dot(axes, normalize=False)
计算两个张量之间样本的点积。
例如,如果作用于输入尺寸为 (batch_size, n) 的两个张量 a 和 b, 那么输出结果就会是尺寸为 (batch_size, 1) 的一个张量。 在这个张量中,每一个条目 i 是 a[i] 和 b[i] 之间的点积。
参数
axes: 整数或者整数元组, 一个或者几个进行点积的轴。
normalize: 是否在点积之前对即将进行点积的轴进行 L2 标准化。 如果设置成 True,那么输出两个样本之间的余弦相似值。
**kwargs: 层关键字参数。
add
keras.layers.add(inputs)
Add 层的函数式接口。
参数
inputs: 一个输入张量的列表(列表大小至少为 2)。
**kwargs: 层关键字参数。
返回
一个张量,所有输入张量的和。
例子
import keras
input1 = keras.layers.Input(shape=(16,))
x1 = keras.layers.Dense(8, activation='relu')(input1)
input2 = keras.layers.Input(shape=(32,))
x2 = keras.layers.Dense(8, activation='relu')(input2)
added = keras.layers.add([x1, x2])
out = keras.layers.Dense(4)(added)
model = keras.models.Model(inputs=[input1, input2], outputs=out)
subtract
keras.layers.subtract(inputs)
Subtract 层的函数式接口。
参数
inputs: 一个列表的输入张量(列表大小准确为 2)。
**kwargs: 层的关键字参数。
返回
一个张量,两个输入张量的差。
例子
import keras
input1 = keras.layers.Input(shape=(16,))
x1 = keras.layers.Dense(8, activation='relu')(input1)
input2 = keras.layers.Input(shape=(32,))
x2 = keras.layers.Dense(8, activation='relu')(input2)
subtracted = keras.layers.subtract([x1, x2])
out = keras.layers.Dense(4)(subtracted)
model = keras.models.Model(inputs=[input1, input2], outputs=out)
multiply
keras.layers.multiply(inputs)
Multiply 层的函数式接口。
参数
inputs: 一个列表的输入张量(列表大小至少为 2)。
**kwargs: 层的关键字参数。
返回
一个张量,所有输入张量的逐元素乘积。
average
keras.layers.average(inputs)
Average 层的函数式接口。
参数
inputs: 一个列表的输入张量(列表大小至少为 2)。
**kwargs: 层的关键字参数。
返回
一个张量,所有输入张量的平均值。
maximum
keras.layers.maximum(inputs)
Maximum 层的函数式接口。
参数
inputs: 一个列表的输入张量(列表大小至少为 2)。
**kwargs: 层的关键字参数。
返回
一个张量,所有张量的逐元素的最大值。
concatenate
keras.layers.concatenate(inputs, axis=-1)
Concatenate 层的函数式接口。
参数
inputs: 一个列表的输入张量(列表大小至少为 2)。
axis: 串联的轴。
**kwargs: 层的关键字参数。
返回
一个张量,所有输入张量通过 axis 轴串联起来的输出张量。
dot
keras.layers.dot(inputs, axes, normalize=False)
Dot 层的函数式接口。
参数
inputs: 一个列表的输入张量(列表大小至少为 2)。
axes: 整数或者整数元组, 一个或者几个进行点积的轴。
normalize: 是否在点积之前对即将进行点积的轴进行 L2 标准化。 如果设置成 True,那么输出两个样本之间的余弦相似值。
**kwargs: 层的关键字参数。
返回
一个张量,所有输入张量样本之间的点积。