by:by微笑99 有需要的朋友可以参考,共勉,不喜勿喷。
Struts1工作原理图:
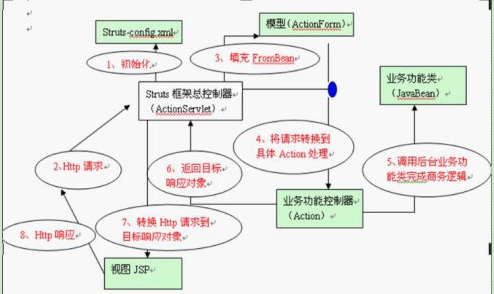
1、初始化:struts框架的总控制器ActionServlet是一个Servlet,它在web.xml中配置成自动启动的Servlet,在启动时总控制器会读取配置文件(struts-config.xml)的配置信息,为struts中不同的模块初始化相应的对象。(面向对象思想)
2、发送请求:用户提交表单或通过URL向WEB服务器提交请求,请求的数据用HTTP协议传给web服务器。
3、form填充:struts的总控制器ActionServlet在用户提交请求时将数据放到对应的form对象中的成员变量中。
4、派发请求:控制器根据配置信息对象ActionConfig将请求派发到具体的Action,对应的formBean一并传给这个Action中的excute()方法。
5、处理业务:Action一般只包含一个excute()方法,它负责执行相应的业务逻辑(调用其它的业务模块)完毕后返回一个ActionForward对象。服务器通过ActionForward对象进行转发工作。
6、返回响应:Action将业务处理的不同结果返回一个目标响应对象给总控制器。
7、查找响应:总控制器根据Action处理业务返回的目标响应对象,找到对应的资源对象,一般情况下为jsp页面。
8、响应用户:目标响应对象将结果传递给资源对象,将结果展现给用户。
ssh框架启动流程
系统从职责上分为四层:表示层、业务逻辑层、数据持久层和域模块层。其中使用Struts作为系统的整体基础架构,负责
MVC的分离,在Struts框架的模型部分,利用Hibernate框架对持久层提供支持,业务层用Spring支持。具体做法是:用面向对象的分析方法根据需求提出一些模型,将这些模型实现为基本的Java对象,然后编写基本的DAO接口,并给出Hibernate的DAO实现,采用 Hibernate架构实现的DAO类来实现Java类与数据库之间的转换和访问,最后由Spring完成业务逻辑。
系统的基本业务流程是:在表示层中,首先通过JSP页面实现交互界面,负责传送请求(Request)和接收响应(Response),然后Struts根据配置文件
(struts-config.xml)将ActionServlet接收到的Request委派给相应的Action处理。在业务层中,管理服务组件的 Spring IoC容器负责向Action提供业务模型(Model)组件和该组件的协作对象数据处理(DAO)组件完成业务逻辑,并提供事务处理、缓冲池等容器组件以提升系统性能和保证数据的完整性。而在持久层中,则依赖于Hibernate的对象化映射和数据库交互,处理DAO组件请求的数据,并返回处理结果。
采用上述开发模型,不仅实现了视图、控制器与模型的彻底分离,而且还实现了业务逻辑层与持久层的分离。这样无论前端如何变化,模型层只需很少的改动,并且数据库的变化也不会对前端有所影响,大大提高了系统的可复用性。而且由于不同层之间耦合度小,有利于团队成员并行工作,大大提高了开发效率。
Struts1与struts2有什么不同
1.Action类
Stuts1要求Action类继承一个抽象基类。Struts1的一个普通问题是使用抽象类编程而不是接口。Struts2 Action类可以实现一个Action接口,也可以实现其它接口,使可选和定制的服务成为可能。Struts2提供一个ActionSupport基类去实现常用的接口。Action 接口不是必须的,任何有execute标识的POJO对象都可以用作Struts2的Action对象。
2. 线程模式:Struts1n Action是单例模式并且必须是线程安全的,因为仅有Action的一个实例来处理所有的请求。单例策略限制了Struts1 Action能作的事,并且要在开发时特别小心。Action资源必须是线程安全的或同步的。 Struts 2 Action对象为每一个请求产生一个实例,因此没有线程安全问题。
3.
Servlet依赖:Struts1 Action依赖于Servletn API,因为当一个Action被调用时,HttpServletResquest和HttpServletResponse被传递给execute方法,即Action依赖了容器,测试变得非常麻烦。Struts2 Action不依赖于容器,允许Action脱离容器单独被测试。如果需要,Struts2Action仍然可以访问初始的request和response。但是,其它的元素减少或者消除了直接访问HttpServletRequset和HttpServletResponse的必要性。
4.捕获输入:Struts1使用ActionForm对象捕获输入。所有的ActionForm必须继承一个基类。因为其它JavaBean不能用作ActionForm,开发者经常创建多余的类捕获输入。动态Bean可以作为创建传统ActionForm的选择,但是,开发者可能是在重新描述已经存在的JavaBean,仍然会导致有冗余的javabean。Struts2直接使用Action属性作为输入属性,消除了对第二输入对象的需求。Action属性能够通过web页面上的taglibs访问。Struts2也支持ActionForm模式。(Struts2用普通的POJO来接收数据)
5.表达式语言:Struts1整合了JSTL,但对集合和索引属性的支持很弱。Struts2可以是使用JSTL,但是也支持一个更加强大和灵活的表达式语言 “Object Graph Notation Language”(OGNL).
6. 绑定值到页面(view):Struts1使用标准JSP机制把对象绑定到页面中来访问,Struts1要传递值的时候必须往request里放、往session里放,然后再传递到jsp里面,铜鼓el表达式得到。Struts2使用“ValueStack”技术,使taglib能够访问值而不需要把你的页面和对象绑定起来。ValueStack策略允许通过一系列名称相同但类型不同的属性重用页面。值栈技术非常著名。不需要request、不需要session,直接从Action中取值。
7.类型转换: Struts1ActionForm属性通常都是String类型。Struts1使用Commons-Beanutils进行类型转换。每个类一个转换器,对每一个实例来说是不可配置的。Struts2 使用OGNL进行类型转换。提供基本和常用对象的转换器。
8.校验:Struts1支持在ActionForm的validate方法中手动校验,或者通过Commons Validator的扩展来校验。同一个类可以有不同的校验内容,但不能校验子对象。Struts2支持通过validate方法和Xwork校验框架来进行校验。Xwork校验框架使用为属性类类型定义的校验和内容校验,来支持chain校验子属性。
9.Action执行的控制:Struts1支持每一个模块有单独的RequestProcessors(生命周期),但是模块中的所有Action必须共享相同的生命周期。(服务器重启时,Action生命周期结束,即生命周期无法控制)。Struts2支持通过拦截器堆栈(Interceptorn Stacks)为每一个Action创建不同的生命周期。堆栈能够根据需要和不同的Action一起使用。(可以控制Action的生命周期)
简单的说:
struts1 和struts2的核心原理不同:
struts1.X是基于servlet的
struts2是xwork的变体:他的核心是filter
struts1是单力模式开发,
struts2是多力模式。
struts1的单力模式好处是节省内存,缺点是并发性查,非同步。
struts2好处是线程安全是同步的每次使用开辟新的内存空间,缺点是占用资源多。
Model1的原理:
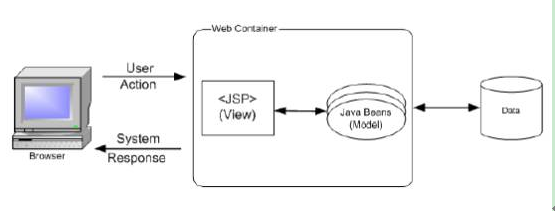
Struts1的工作原理:
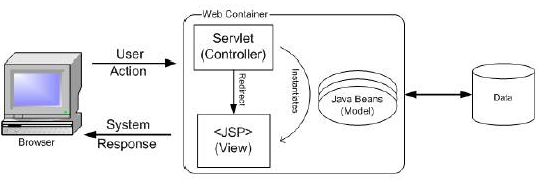
图2
它引入了"控制器"这个概念,控制器一般由servlet来担任,客户端的请求不再直接送给一个处理业务逻辑的JSP页面,而是送给这个控制器,再由控制器根据具体的请求调用不同的事务逻辑,并将处理结果返回到合适的页面。因此,这个servlet控制器为应用程序提供了一个进行前-后端处理的中枢。一方面为输入数据的验证、身份认证、日志及实现国际化编程提供了一个合适的切入点;另一方面也提供了将业务逻辑从JSP文件剥离的可能。业务逻辑从JSP页面分离后,JSP文件蜕变成一个单纯完成显示任务的东西,这就是常说的View。而独立出来的事务逻辑变成人们常说的Model,再加上控制器Control本身,就构成了MVC模式。实践证明,MVC模式为大型程序的开发及维护提供了巨大的便利。
其实,MVC开始并不是为Web应用程序提出的模式,传统的MVC要求M将其状态变化通报给V,但由于Web浏览器工作在典型的拉模式而非推模式,很难做到这一点。因此有些人又将用于Web应用的MVC称之为MVC2。正如上面所提到的MVC是一种模式,当然可以有各种不同的具体实现,包括您自己就可以实现一个体现MVC思想的程序框架,Struts就是一种具体实现MVC2的程序框架。它的大致结构如图三所示:
图三
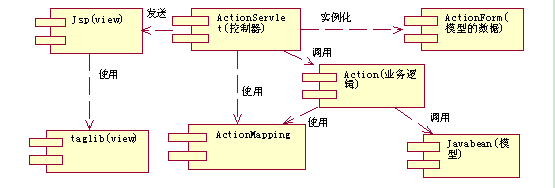
图三基本勾勒出了一个基于Struts的应用程序的结构,从左到右,分别是其表示层(view)、控制层(controller)、和模型层(Model)。其表示层使用Struts标签库构建。来自客户的所有需要通过框架的请求统一由叫ActionServlet的servlet接收(ActionServlet Struts已经为我们写好了,只要您应用没有什么特别的要求,它基本上都能满足您的要求),根据接收的请求参数和Struts配置(struts-config.xml)中ActionMapping,将请求送给合适的Action去处理,解决由谁做的问题,它们共同构成Struts的控制器。Action则是Struts应用中真正干活的组件,开发人员一般都要在这里耗费大量的时间,它解决的是做什么的问题,它通过调用需要的业务组件(模型)来完成应用的业务,业务组件解决的是如何做的问题,并将执行的结果返回一个代表所需的描绘响应的JSP(或Action)的ActionForward对象给ActionServlet以将响应呈现给客户。
过程如图四所示:
图四

这里要特别说明一下的是:就是Action这个类,上面已经说到了它是Struts中真正干活的地方,也是值得我们高度关注的地方。可是,关于它到底是属于控制层还是属于模型层,存在两种不同的意见,一种认为它属于模型层,如:《JSP Web编程指南》;另一些则认为它属于控制层如:《Programming
Jakarta Struts》、《Mastering Jakarta Struts》和《Struts Kick Start》等认为它是控制器的一部分,还有其他一些书如《Struts
in Action》也建议要避免将业务逻辑放在Action类中,也就是说,图3中Action后的括号中的内容应该从中移出,但实际中确有一些系统将比较简单的且不打算重用的业务逻辑放在Action中,所以在图中还是这样表示。显然,将业务对象从Action分离出来后有利于它的重用,同时也增强了应用程序的健壮性和设计的灵活性。因此,它实际上可以看作是Controller与Model的适配器,如果硬要把它归于那一部分,笔者更倾向于后一种看法,即它是Controller的一部分,换句话说,它不应该包含过多的业务逻辑,而应该只是简单地收集业务方法所需要的数据并传递给业务对象。实际上,它的主要职责是:
- 校验前提条件或者声明
- 调用需要的业务逻辑方法
- 检测或处理其他错误
- 路由控制到相关视图
上面这样简单的描述,初学者可能会感到有些难以接受,下面举个比较具体的例子来进一步帮助我们理解。如:假设,我们做的是个电子商务程序,现在程序要完成的操作任务是提交定单并返回定单号给客户,这就是关于做什么的问题,应该由Action类完成,但具体怎么获得数据库连接,插入定单数据到数据库表中,又怎么从数据库表中取得这个定单号(一般是自增数据列的数据),这一系列复杂的问题,这都是解决怎么做的问题,则应该由一个(假设名为orderBo)业务对象即Model来完成。orderBo可能用一个返回整型值的名为submitOrder的方法来做这件事,Action则是先校验定单数据是否正确,以免常说的垃圾进垃圾出;如果正确则简单地调用orderBo的submitOrder方法来得到定单号;它还要处理在调用过程中可能出现任何错误;最后根据不同的情况返回不同的结果给客户。
二、为什么要使用Struts框架
既然本文的开始就说了,自己可以建这种框架,为什么要使用Struts呢?我想下面列举的这些理由是显而易见的:首先,它是建立在MVC这种公认的好的模式上的,Struts在M、V和C上都有涉及,但它主要是提供一个好的控制器和一套定制的标签库上,也就是说它的着力点在C和V上,因此,它天生就有MVC所带来的一系列优点,如:结构层次分明,高可重用性,增加了程序的健壮性和可伸缩性,便于开发与设计分工,提供集中统一的权限控制、校验、国际化、日志等等;其次,它是个开源项目得到了包括它的发明者Craig R.McClanahan在内的一些程序大师和高手持续而细心的呵护,并且经受了实战的检验,使其功能越来越强大,体系也日臻完善;最后,是它对其他技术和框架显示出很好的融合性。如,现在,它已经与tiles融为一体,可以展望,它很快就会与JSF等融会在一起。当然,和其他任何技术一样,它也不是十全十美的,如:它对类和一些属性、参数的命名显得有些随意,给使用带来一些不便;还有如Action类execute方法的只能接收一个ActionForm参数等。但瑕不掩瑜,这些没有影响它被广泛使用
为什么使用Struts2 ?
新版本的Struts2.0是struts 的action架构和webwork的融合体.依照Struts2.0.1的发布公告,一些关键特性如下 :
l 设计简单: 使用抽象类而不是接口是Struts1的一个设计上的问题,这已经在Struts2中得到了解决.在Struts2中绝大多数类都是基于接口的,并且它的绝大多数核心接口都是独立于HTTP的.Struts2的Action类是独立于框架的,可视为单纯的POJO.框架的组件都设法保持松耦合
l 单纯的Action : Action都是单纯的POJO.任何含有execute()方法的java类都可以当作Action类来使用.甚至我们始终都不需要实现接口.反转控制会在开发Action类的时候得到介绍过,这能让Action中立于底层框架.
l 不再使用ActionForm : ActionForm特性不再在Structs2中出现.简单的JavaBean即可对Action直接传递参数.不再需要全部使用String类型的参数.
l 简单的测试 : Struts2的Action是独立于HTTP并且中立于框架的.这使得Struts2的程序可以很容易的在没有模拟对象的情况下测试.
l 巧妙的默认值 : 大多数配置元素都设有一个根据需要设定的默认值.甚至根据需要基于XML的默认配置文件都可以进行重写.
l 改良的结果集 : 不像Struts1中的ActionForward,Struts2的结果集灵活的提供了多种类型的输出,事实上这促进了响应的准备工作.
l 更好的标签特性 : Struts2可以添加样式表驱动标记,这使我们创建相同的页面仅用更少的代码.Struts2的标签更有效而且是面向结果的.Struts2的标签标记可以通过修改基础样式表来修改.个别的标签标记可以通过编辑FreeMarker的模板来修改.JSP和FreeMarker都完全得到了支持.
l 引入注释 : 在Struts2程序中,除了XML和Java properties 配置文件外,Java 5的注释也可以作为一种选择.注释使得XML的使用降至最低.
l 有状态的Checkbox : Struts2中的checkbox不需要对false值进行特殊处理.
l 快速开始 : 很多改变无需重启web容器即可实现.
l 自定义控制器 : Struts1可以自定义每一个模块的请求处理器,如果需要,Struts2可以自定义每一个Action的请求处理.
l 易与Spring整合 : Struts2的Action与Spring是友好的,只需添加Spring的bean
l 轻巧的插件 : Struts2可以通过添加一个Jar文件来进行扩展,不再需要手动配置!
l 支持AJAX : AJAX主题对提升程序交互有着重要的意义.Struts2框架提供了一套标签来AJAX化你的程序甚至DOJO.AJAX特性包括:
1. AJAX客户端验证.
2. 支持远程表单提交.(同样适用于submit标签)
3. 先进的div模板提供动态重载部份HTML
4. 先进的模板提供远程加载和计算Javascript的能力.
5. AJAX-only选项卡面板的实现
6. 丰富的发布/订阅事件模型
7. 自动交互完善标签
一、 Struts概述
Struts是一个用来开发 Model 2应用程序的框架。这个框架可以提高开发工作的速度,因为它提供的下面这些功能解决了 Web应用程序开发过程中的一些常见问题:
- 对页面导航活动进行管理;
- 对来自用户的输入数据进行合法性验证;
- 统一的布局;
- 可扩展性;
- 国际化和本地化;
- 支持 Ajax技术。
因为 Struts是一个 Model 2框架,所以在使用 Struts时还应该遵守以下几条不成文的规定。
- 不要在 JSP页面里嵌入 Java代码,应该把所有的业务逻辑包含在一些被称为“动作类”( action class)的 Java类里。
- 在 JSP页面里使用 Expression Language( OGNL)去访问有关的模型对象。
- 尽量避免编写自定义标签(因为自定义标签的代码比较难以编写)。
二、升级到 Struts 2
你也许用过 Struts 1编程,这里提供了一个关于 Struts 2 新功能的简要介绍。
- 在 Struts 1里需要使用一个像 ActionServlet 类这样的东西作为 servlet控制器; Struct 2使用了一个过滤器来完成同样的任务。
- 在 Struts 2里没有任何动作表单。在 Struts 1里,每个 HTML表单都对应着一个 ActionForm 实例,你可以从动作类访问这个动作表单,并用它来填充数据传输对象。在 Struts 2 里, HTML表单将被直接映射为一个 POJO,而不再需要你创建一个数据传输对象,因为没有动作表单,维护工作变得简单容易了,你不再需要与那么多的类打交道。
- 问题来了:没有了动作表单,怎样才能在 Struts 2里通过编程对用户输入进行合法性验证呢?答案是把验证逻辑编写在动作类里。
- Struts 1通过几个标签库提供了一批定制标签供程序员在 JSP页面里使用,其中最重要的是 HTML标签库、 Bean标签库和 Logic标签库。 Servlet 2.4里的 JSTL和 EL( Expression Language ,表达式语言)经常被用来代替 Bean和 Logic标签库。 Struts 2为程序员准备了一个应有尽有的标签库,你不再需要 JSTL,但在某些场合你可能仍需要 EL。
- 在 Struts 1里,你还需要用到一些 Struts配置文件,其中最主要的是存放在各 Web应用程序里的 WEB-INF子目录里的 struts-config.xml(默认文件名)。在 Struts 2里,你仍需要用到多个配置文件,但必须把它们存放在 WEB-INF/classes子目录或它的某个下级子目录里。
- 要想使用 Struts 2 ,你的系统里必须有 Java 5 和 Servlet 2.4 (或更高版本)。之所以需要有 Java 5,是因为 Java 5里新增加的注解在 Struts 2里扮演着重要角色。我们撰写本书时, Java 6已经发布, Java 7也指日可待,你很可能已经在使用 Java 5或 Java 6了。
- 在 Struts 1 里,动作类必须扩展自 org.apache.struts.action.Action 类。在 Struts 2 里,任何一个 POJO 都可以是一个动作类。不过,我们将在本书第 3 章说明,在 Struts 2 里最好对 ActionSupport 类进行扩展。在此基础上,可用一个动作类来完成相关的动作。
- Struts 2在 JSP页面里使用 OGNL来显示各种对象模型,而不再是 JSP EL和 JSTL。
原本是 Struts 1组件之一的 Tiles现在已经发展为一个独立的 Apache
HTTP没有“类型”的概念,在 HTTP请求里发送的值都是字符串。在把表单字段映射到非 String 类型的动作属性时, Struts会自动对这些值进行必要的转换。这一章将解释 Struts如何完成这类转换,你还将学到如何为更加复杂的情
|
spring工作机制及为什么要用? 1.springmvc请所有的请求都提交给DispatcherServlet,它会委托应用系统的其他模块负责负责对请求进行真正的处理工作。 2.DispatcherServlet查询一个或多个HandlerMapping,找到处理请求的Controller. 3.DispatcherServlet请请求提交到目标Controller 4.Controller进行业务逻辑处理后,会返回一个ModelAndView 5.Dispathcher查询一个或多个ViewResolver视图解析器,找到ModelAndView对象指定的视图对象 6.视图对象负责渲染返回给客户端。 为什么用: AOP 让开发人员可以创建非行为性的关注点,称为横切关注点,并将它们插入到应用程序代码中。使用 AOP后,公共服务(比如日志、持久性、事务等)就可以分解成方面并应用到域对象上,同时不会增加域对象的对象模型的复杂性。 IOC 允许创建一个可以构造对象的应用环境,然后向这些对象传递它们的协作对象。正如单词 倒置 所表明的,IOC 就像反过来的JNDI。没有使用一堆抽象工厂、服务定位器、单元素(singleton)和直接构造(straightconstruction),每一个对象都是用其协作对象构造的。因此是由容器管理协作对象(collaborator)。 Spring即使一个AOP框架,也是一IOC容器。 Spring 最好的地方是它有助于您替换对象。有了Spring,只要用JavaBean属性和配置文件加入依赖性(协作对象)。然后可以很容易地在需要时替换具有类似接口的协作对象。 Spring 框架是一个分层架构,由 7 个定义良好的模块组成。Spring模块构建在核心容器之上,核心容器定义了创建、配置和管理bean 的方式,如图 1 所示。 组成 Spring 框架的每个模块(或组件)都可以单独存在,或者与其他一个或多个模块联合实现。每个模块的功能如下: 核心容器:核心容器提供 Spring框架的基本功能。核心容器的主要组件是BeanFactory,它是工厂模式的实现。BeanFactory使用控制反转(IOC)模式将应用程序的配置和依赖性规范与实际的应用程序代码分开。 Spring 上下文:Spring 上下文是一个配置文件,向 Spring框架提供上下文信息。Spring上下文包括企业服务,例如 JNDI、EJB、电子邮件、国际化、校验和调度功能。 Spring AOP:通过配置管理特性,Spring AOP 模块直接将面向方面的编程功能集成到了Spring框架中。所以,可以很容易地使 Spring 框架管理的任何对象支持 AOP。Spring AOP 模块为基于Spring的应用程序中的对象提供了事务管理服务。通过使用 Spring AOP,不用依赖EJB组件,就可以将声明性事务管理集成到应用程序中。 Spring DAO:JDBCDAO抽象层提供了有意义的异常层次结构,可用该结构来管理异常处理和不同数据库供应商抛出的错误消息。异常层次结构简化了错误处理,并且极大地降低了需要编写的异常代码数量(例如打开和关闭连接)。SpringDAO的面向 JDBC 的异常遵从通用的 DAO 异常层次结构。 Spring ORM:Spring 框架插入了若干个 ORM 框架,从而提供了 ORM的对象关系工具,其中包括JDO、Hibernate 和 iBatis SQL Map。所有这些都遵从 Spring 的通用事务和DAO异常层次结构。 Spring Web 模块:Web 上下文模块建立在应用程序上下文模块之上,为基于Web的应用程序提供了上下文。所以,Spring 框架支持与 Jakarta Struts的集成。Web模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。 Spring MVC 框架:MVC 框架是一个全功能的构建 Web 应用程序的 MVC实现。通过策略接口,MVC框架变成为高度可配置的,MVC 容纳了大量视图技术,其中包括JSP、Velocity、Tiles、iText 和 POI。 Spring 框架的功能可以用在任何 J2EE服务器中,大多数功能也适用于不受管理的环境。Spring的核心要点是:支持不绑定到特定 J2EE服务的可重用业务和数据访问对象。毫无疑问,这样的对象可以在不同 J2EE 环境 (Web或EJB)、独立应用程序、测试环境之间重用。 共2页: 1 [2] 内容导航 第 1 页:Hibernate工作原理及用的理由(1) 第 2 页:Hibernate工作原理及用的理由(2) IOC 和 AOP 控制反转模式(也称作依赖性介入)的基本概念是:不创建对象,但是描述创建它们的方式。在代码中不直接与对象和服务连接,但在配置文件中描述哪一个组件需要哪一项服务。容器(在Spring框架中是 IOC 容器) 负责将这些联系在一起。 在典型的 IOC 场景中,容器创建了所有对象,并设置必要的属性将它们连接在一起,决定什么时间调用方法。下表列出了IOC的一个实现模式。 Spring 框架的 IOC 容器采用类型 2 和类型3 实现。 面向方面的编程 面向方面的编程 ,即AOP,是一种编程技术,它允许程序员对横切关注点或横切典型的职责分界线的行为(例如日志和事务管理)进行模块化。AOP的核心构造是方面,它将那些影响多个类的行为封装到可重用的模块中。 AOP 和IOC是补充性的技术,它们都运用模块化方式解决企业应用程序开发中的复杂问题。在典型的面向对象开发方式中,可能要将日志记录语句放在所有方法和Java类中才能实现日志功能。在 AOP方式中,可以反过来将日志服务模块化,并以声明的方式将它们应用到需要日志的组件上。当然,优势就是Java类不需要知道日志服务的存在,也不需要考虑相关的代码。所以,用 Spring AOP 编写的应用程序代码是松散耦合的。 AOP 的功能完全集成到了 Spring 事务管理、日志和其他各种特性的上下文中。 IOC 容器 Spring 设计的核心是 org.springframework.beans 包,它的设计目标是与JavaBean组件一起使用。这个包通常不是由用户直接使用,而是由服务器将其用作其他多数功能的底层中介。下一个最高级抽象是BeanFactory接口,它是工厂设计模式的实现,允许通过名称创建和检索对象。BeanFactory也可以管理对象之间的关系。 BeanFactory 支持两个对象模型。 单态模型提供了具有特定名称的对象的共享实例,可以在查询时对其进行检索。Singleton是默认的也是最常用的对象模型。对于无状态服务对象很理想。 原型 模型确保每次检索都会创建单独的对象。在每个用户都需要自己的对象时,原型模型最适合。 bean 工厂的概念是 Spring 作为 IOC容器的基础。IOC将处理事情的责任从应用程序代码转移到框架。正如我将在下一个示例中演示的那样,Spring 框架使用JavaBean属性和配置数据来指出必须设置的依赖关系。 BeanFactory 接口 因为org.springframework.beans.factory.BeanFactory是一个简单接口,所以可以针对各种底层存储方法实现。最常用的BeanFactory 定义是 XmlBeanFactory,它根据XML 文件中的定义装入 bean,如清单 1 所示。 清单 1. XmlBeanFactory BeanFactory factory = newXMLBeanFactory(newFileInputSteam("mybean.xml")); 在 XML 文件中定义的 Bean 是被消极加载的,这意味在需要 bean 之前,bean本身不会被初始化。要从BeanFactory 检索 bean,只需调用 getBean() 方法,传入将要检索的 bean的名称即可,如清单 2所示。 清单 2. getBean() MyBean mybean = (MyBean) factory.getBean("mybean"); 每个 bean 的定义都可以是 POJO (用类名和 JavaBean 初始化属性定义)或FactoryBean。FactoryBean 接口为使用 Spring 框架构建的应用程序添加了一个间接的级别。 IOC 示例 理解控制反转最简单的方式就是看它的实际应用。在对由三部分组成的 Spring 系列 的第1部分进行总结时,我使用了一个示例,演示了如何通过 Spring IOC 容器注入应用程序的依赖关系(而不是将它们构建进来)。 我用开启在线信用帐户的用例作为起点。对于该实现,开启信用帐户要求用户与以下服务进行交互: 信用级别评定服务,查询用户的信用历史信息。 远程信息链接服务,插入客户信息,将客户信息与信用卡和银行信息连接起来,以进行自动借记(如果需要的话)。 电子邮件服务,向用户发送有关信用卡状态的电子邮件。 三个接口 对于这个示例,我假设服务已经存在,理想的情况是用松散耦合的方式把它们集成在一起。以下清单显示了三个服务的应用程序接口。 清单 3. CreditRatingInterface public interface CreditRatingInterface publicbooleangetUserCreditHistoryInformation(ICustomer iCustomer); 清单 3 所示的信用级别评定接口提供了信用历史信息。它需要一个包含客户信息的 Customer对象。该接口的实现是由CreditRating 类提供的。 清单 4. CreditLinkingInterface public interface CreditLinkingInterface public String getUrl(); public void setUrl(String url);publicvoid linkCreditBankAccount() throws Exception ; 信用链接接口将信用历史信息与银行信息(如果需要的话)连接在一起,并插入用户的信用卡信息。信用链接接口是一个远程服务,它的查询是通过getUrl()方法进行的。URL 由 Spring 框架的 bean 配置机制设置,我稍后会讨论它。该接口的实现是由CreditLinking类提供的。 清单 5. EmailInterface public interface EmailInterface public void sendEmail(ICustomer iCustomer); publicStringgetFromEmail(); public void setFromEmail(String fromEmail) ;publicString getPassword(); public void setPassword(Stringpassword) ;public String getSmtpHost() ; public voidsetSmtpHost(StringsmtpHost); public String getUserId() ; publicvoid setUserId(StringuserId); |
原理:
1. 读取并解析配置文件
2. 读取并解析映射信息,创建SessionFactory
3. 打开Sesssion
4. 创建事务Transation
5. 持久化操作
6. 提交事务
7. 关闭Session
8. 关闭SesstionFactory
为什么要用:
1. 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
2. Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
3. hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
4. hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
2. Hibernate是如何延迟加载?
1. Hibernate2延迟加载实现:a)实体对象 b)集合(Collection)
2. Hibernate3 提供了属性的延迟加载功能
当Hibernate在查询数据的时候,数据并没有存在于内存中,当程序真正对数据的操作时,对象才存在与内存中,就实现了延迟加载,他节省了服务器的内存开销,从而提高了服务器的性能。
3. Hibernate中怎样实现类之间的关系?(如:一对多、多对多的关系)
类与类之间的关系主要体现在表与表之间的关系进行操作,它们都是对对象进行操作,我们程序中把所有的表与类都映射在一起,它们通过配置文件中的many-to-one、one-to-many、many-to-many配置
4. 说下Hibernate的缓存机制
1. 内部缓存存在Hibernate中又叫一级缓存,属于应用事务级缓存
2. 二级缓存:
a) 应用级缓存
b) 分布式缓存
条件:数据不会被第三方修改、数据大小在可接受范围、数据更新频率低、同一数据被系统频繁使用、非关键数据
c) 第三方缓存的实现
5. Hibernate的查询方式
Sql、Criteria,object comptosition
Hql:
1、 属性查询
2、 参数查询、命名参数查询
3、 关联查询
4、 分页查询
5、 统计函数
6. 如何优化Hibernate?
1. 使用双向一对多关联,不使用单向一对多
2. 灵活使用单向一对多关联
3. 不用一对一,用多对一取代
4. 配置对象缓存,不使用集合缓存
5. 一对多集合使用Bag,多对多集合使用Set
6. 继承类使用显式多态
7. 表字段要少,表关联不要怕多,有二级缓存撑腰
7. Struts工作机制?为什么要使用Struts?
工作机制:
Struts的工作流程:
在web应用启动时就会加载初始化ActionServlet,ActionServlet从
struts-config.xml文件中读取配置信息,把它们存放到各种配置对象
当ActionServlet接收到一个客户请求时,将执行如下流程.
-(1)检索和用户请求匹配的ActionMapping实例,如果不存在,就返回请求路径无效信息;
-(2)如果ActionForm实例不存在,就创建一个ActionForm对象,把客户提交的表单数据保存到ActionForm
对象中;
-(3)根据配置信息决定是否需要表单验证.如果需要验证,就调用ActionForm的validate()方法;
-(4)如果ActionForm的validate()方法返回null或返回一个不包含ActionMessage的ActuibErrors对象,
就表示表单验证成功;
-(5)ActionServlet根据ActionMapping所包含的映射信息决定将请求转发给哪个Action,如果相应的
Action实例不存在,就先创建这个实例,然后调用Action的execute()方法;
-(6)Action的execute()方法返回一个ActionForward对象,ActionServlet在把客户请求转发给
ActionForward对象指向的JSP组件;
-(7)ActionForward对象指向JSP组件生成动态网页,返回给客户;
为什么要用:
JSP、Servlet、JavaBean技术的出现给我们构建强大的企业应用系统提供了可能。但用这些技术构建的系统非常的繁乱,所以在此之上,我们需要一个规则、一个把这些技术组织起来的规则,这就是框架,Struts便应运而生。
基于Struts开发的应用由3类组件构成:控制器组件、模型组件、视图组件
8. Struts的validate框架是如何验证的?
在struts配置文件中配置具体的错误提示,再在FormBean中的validate()方法具体调用。
9. 说下Struts的设计模式
MVC模式: web应用程序启动时就会加载并初始化ActionServler。用户提交表单时,一个配置好的ActionForm对象被创建,并被填入表单相应的数据,ActionServler根据Struts-config.xml文件配置好的设置决定是否需要表单验证,如果需要就调用ActionForm的Validate()验证后选择将请求发送到哪个Action,如果Action不存在,ActionServlet会先创建这个对象,然后调用Action的execute()方法。Execute()从ActionForm对象中获取数据,完成业务逻辑,返回一个ActionForward对象,ActionServlet再把客户请求转发给ActionForward对象指定的jsp组件,ActionForward对象指定的jsp生成动态的网页,返回给客户。
单例模式
Factory(工厂模式):
定义一个基类===》实现基类方法(子类通过不同的方法)===》定义一个工厂类(生成子类实例)
===》开发人员调用基类方法
Proxy(代理模式)
10.
spring工作机制及为什么要用?
1.spring mvc请所有的请求都提交给DispatcherServlet,它会委托应用系统的其他模块负责负责对请求进行真正的处理工作。
2.DispatcherServlet查询一个或多个HandlerMapping,找到处理请求的Controller.
3.DispatcherServlet请请求提交到目标Controller
4.Controller进行业务逻辑处理后,会返回一个ModelAndView
5.Dispathcher查询一个或多个ViewResolver视图解析器,找到ModelAndView对象指定的视图对象
6.视图对象负责渲染返回给客户端。
为什么用:
{AOP 让开发人员可以创建非行为性的关注点,称为横切关注点,并将它们插入到应用程序代码中。使用 AOP 后,公共服务 (比 如日志、持久性、事务等)就可以分解成方面并应用到域对象上,同时不会增加域对象的对象模型的复杂性。
IOC 允许创建一个可以构造对象的应用环境,然后向这些对象传递它们的协作对象。正如单词 倒置 所表明的,IOC
就像反 过来的 JNDI。没有使用一堆抽象工厂、服务定位器、单元素(singleton)和直接构造(straight construction),每一个对象都是用
其协作对象构造的。因此是由容器管理协作对象(collaborator)。
Spring即使一个AOP框架,也是一IOC容器。 Spring 最好的地方是它有助于您替换对象。有了 Spring,只要用 JavaBean 属性和配置文件加入依赖性(协作对象)。然后可以很容易地在需要时替换具有类似接口的协作对象。}
Spring的工作原理
一、 IoC(Inversion of control): 控制反转
1、IoC:
概念:控制权由对象本身转向容器;由容器根据配置文件去创建实例并创建各个实例之间的依赖关系
核心:bean工厂;在Spring中,bean工厂创建的各个实例称作bean
二、AOP(Aspect-Oriented Programming): 面向方面编程
1、 代理的两种方式:
静态代理:
针对每个具体类分别编写代理类;l
针对一个接口编写一个代理类;l
动态代理:
针对一个方面编写一个InvocationHandler,然后借用JDK反射包中的Proxy类为各种接口动态生成相应的代理类
2、 AOP的主要原理:动态代理
Spring工作原理
Spring 已经用过一段时间了,感觉Spring是个很不错的框架。内部最核心的就是IOC了,
动态注入,让一个对象的创建不用new了,可以自动的生产,这其实就是利用java里的反射
反射其实就是在运行时动态的去创建、调用对象,Spring就是在运行时,跟xml Spring的配置
文件来动态的创建对象,和调用对象里的方法的 。
Spring还有一个核心就是AOP这个就是面向切面编程,可以为某一类对象 进行监督和控制(也就是
在调用这类对象的具体方法的前后去调用你指定的 模块)从而达到对一个模块扩充的功能。这些都是通过
配置类达到的。
Spring目的:就是让对象与对象(模块与模块)之间的关系没有通过代码来关联,都是通过配置类说明
管理的(Spring根据这些配置 内部通过反射去动态的组装对象)
要记住:Spring是一个容器,凡是在容器里的对象才会有Spring所提供的这些服务和功能。
Spring里用的最经典的一个设计模式就是:模板方法模式。(这里我都不介绍了,是一个很常用的设计模式)
Spring里的配置是很多的,很难都记住,但是Spring里的精华也无非就是以上的两点,把以上两点跟理解了
也就基本上掌握了Spring.
原理:
1. 读取并解析配置文件
2. 读取并解析映射信息,创建SessionFactory
3. 打开Sesssion
4. 创建事务Transation
5. 持久化操作
6. 提交事务
7. 关闭Session
8. 关闭SesstionFactory
为什么要用:
1. 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
2. Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
3. hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
4. hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
2. Hibernate是如何延迟加载?
1. Hibernate2延迟加载实现:a)实体对象 b)集合(Collection)
2. Hibernate3 提供了属性的延迟加载功能
当Hibernate在查询数据的时候,数据并没有存在于内存中,当程序真正对数据的操作时,对象才存在与内存中,就实现了延迟加载,他节省了服务器的内存开销,从而提高了服务器的性能。
3. Hibernate中怎样实现类之间的关系?(如:一对多、多对多的关系)
类与类之间的关系主要体现在表与表之间的关系进行操作,它们都是对对象进行操作,我们程序中把所有的表与类都映射在一起,它们通过配置文件中的many-to-one、one-to-many、many-to-many配置
4. 说下Hibernate的缓存机制
1. 内部缓存存在Hibernate中又叫一级缓存,属于应用事务级缓存
2. 二级缓存:
a) 应用级缓存
b) 分布式缓存
条件:数据不会被第三方修改、数据大小在可接受范围、数据更新频率低、同一数据被系统频繁使用、非关键数据
c) 第三方缓存的实现
5. Hibernate的查询方式
Sql、Criteria,object comptosition
Hql:
1、 属性查询
2、 参数查询、命名参数查询
3、 关联查询
4、 分页查询
5、 统计函数
6. 如何优化Hibernate?
1. 使用双向一对多关联,不使用单向一对多
2. 灵活使用单向一对多关联
3. 不用一对一,用多对一取代
4. 配置对象缓存,不使用集合缓存
5. 一对多集合使用Bag,多对多集合使用Set
6. 继承类使用显式多态
7. 表字段要少,表关联不要怕多,有二级缓存撑腰
7. Struts工作机制?为什么要使用Struts?
工作机制:
Struts的工作流程:
在web应用启动时就会加载初始化ActionServlet,ActionServlet从
struts-config.xml文件中读取配置信息,把它们存放到各种配置对象
当ActionServlet接收到一个客户请求时,将执行如下流程.
-(1)检索和用户请求匹配的ActionMapping实例,如果不存在,就返回请求路径无效信息;
-(2)如果ActionForm实例不存在,就创建一个ActionForm对象,把客户提交的表单数据保存到ActionForm
对象中;
-(3)根据配置信息决定是否需要表单验证.如果需要验证,就调用ActionForm的validate()方法;
-(4)如果ActionForm的validate()方法返回null或返回一个不包含ActionMessage的ActuibErrors对象,
就表示表单验证成功;
-(5)ActionServlet根据ActionMapping所包含的映射信息决定将请求转发给哪个Action,如果相应的
Action实例不存在,就先创建这个实例,然后调用Action的execute()方法;
-(6)Action的execute()方法返回一个ActionForward对象,ActionServlet在把客户请求转发给
ActionForward对象指向的JSP组件;
-(7)ActionForward对象指向JSP组件生成动态网页,返回给客户;
为什么要用:
JSP、Servlet、JavaBean技术的出现给我们构建强大的企业应用系统提供了可能。但用这些技术构建的系统非常的繁乱,所以在此之上,我们需要一个规则、一个把这些技术组织起来的规则,这就是框架,Struts便应运而生。
基于Struts开发的应用由3类组件构成:控制器组件、模型组件、视图组件
8. Struts的validate框架是如何验证的?
在struts配置文件中配置具体的错误提示,再在FormBean中的validate()方法具体调用。
9. 说下Struts的设计模式
MVC模式: web应用程序启动时就会加载并初始化ActionServler。用户提交表单时,一个配置好的ActionForm对象被创建,并被填入表单相应的数据,ActionServler根据Struts-config.xml文件配置好的设置决定是否需要表单验证,如果需要就调用ActionForm的Validate()验证后选择将请求发送到哪个Action,如果Action不存在,ActionServlet会先创建这个对象,然后调用Action的execute()方法。Execute()从ActionForm对象中获取数据,完成业务逻辑,返回一个ActionForward对象,ActionServlet再把客户请求转发给ActionForward对象指定的jsp组件,ActionForward对象指定的jsp生成动态的网页,返回给客户。
单例模式
Factory(工厂模式):
定义一个基类===》实现基类方法(子类通过不同的方法)===》定义一个工厂类(生成子类实例)
===》开发人员调用基类方法
Proxy(代理模式)
10.
spring工作机制及为什么要用?
1.spring mvc请所有的请求都提交给DispatcherServlet,它会委托应用系统的其他模块负责负责对请求进行真正的处理工作。
2.DispatcherServlet查询一个或多个HandlerMapping,找到处理请求的Controller.
3.DispatcherServlet请请求提交到目标Controller
4.Controller进行业务逻辑处理后,会返回一个ModelAndView
5.Dispathcher查询一个或多个ViewResolver视图解析器,找到ModelAndView对象指定的视图对象
6.视图对象负责渲染返回给客户端。
为什么用:
{AOP 让开发人员可以创建非行为性的关注点,称为横切关注点,并将它们插入到应用程序代码中。使用 AOP 后,公共服务 (比 如日志、持久性、事务等)就可以分解成方面并应用到域对象上,同时不会增加域对象的对象模型的复杂性。
IOC 允许创建一个可以构造对象的应用环境,然后向这些对象传递它们的协作对象。正如单词 倒置 所表明的,IOC
就像反 过来的 JNDI。没有使用一堆抽象工厂、服务定位器、单元素(singleton)和直接构造(straight construction),每一个对象都是用
其协作对象构造的。因此是由容器管理协作对象(collaborator)。
Spring即使一个AOP框架,也是一IOC容器。 Spring 最好的地方是它有助于您替换对象。有了 Spring,只要用 JavaBean 属性和配置文件加入依赖性(协作对象)。然后可以很容易地在需要时替换具有类似接口的协作对象。}
Spring的工作原理
一、 IoC(Inversion of control): 控制反转
1、IoC:
概念:控制权由对象本身转向容器;由容器根据配置文件去创建实例并创建各个实例之间的依赖关系
核心:bean工厂;在Spring中,bean工厂创建的各个实例称作bean
二、AOP(Aspect-Oriented Programming): 面向方面编程
1、 代理的两种方式:
静态代理:
针对每个具体类分别编写代理类;l
针对一个接口编写一个代理类;l
动态代理:
针对一个方面编写一个InvocationHandler,然后借用JDK反射包中的Proxy类为各种接口动态生成相应的代理类
2、 AOP的主要原理:动态代理
Spring工作原理
Spring 已经用过一段时间了,感觉Spring是个很不错的框架。内部最核心的就是IOC了,
动态注入,让一个对象的创建不用new了,可以自动的生产,这其实就是利用java里的反射
反射其实就是在运行时动态的去创建、调用对象,Spring就是在运行时,跟xml Spring的配置
文件来动态的创建对象,和调用对象里的方法的 。
Spring还有一个核心就是AOP这个就是面向切面编程,可以为某一类对象 进行监督和控制(也就是
在调用这类对象的具体方法的前后去调用你指定的 模块)从而达到对一个模块扩充的功能。这些都是通过
配置类达到的。
Spring目的:就是让对象与对象(模块与模块)之间的关系没有通过代码来关联,都是通过配置类说明
管理的(Spring根据这些配置 内部通过反射去动态的组装对象)
要记住:Spring是一个容器,凡是在容器里的对象才会有Spring所提供的这些服务和功能。
Spring里用的最经典的一个设计模式就是:模板方法模式。(这里我都不介绍了,是一个很常用的设计模式)
Spring里的配置是很多的,很难都记住,但是Spring里的精华也无非就是以上的两点,把以上两点跟理解了
也就基本上掌握了Spring.