今天学习如何使用selenium库来爬取百度文库里面的收费的word文档
from selenium import webdriver from selenium.webdriver.common.keys import Keys from pyquery import PyQuery as pq from selenium.webdriver.support.ui import WebDriverWait from selenium import webdriver import time options = webdriver.ChromeOptions() options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"') driver = webdriver.Chrome('D:/chromedriver.exe',options=options) url="https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html" driver.get(url) html=driver.page_source page=driver.find_elements_by_xpath("/html/body/div[2]/div[2]/div[6]/div[2]/div[2]/div[1]/div/div[1]")#使用page标记记录百度文库中向下翻页的位置 driver.execute_script('arguments[0].scrollIntoView();', page)
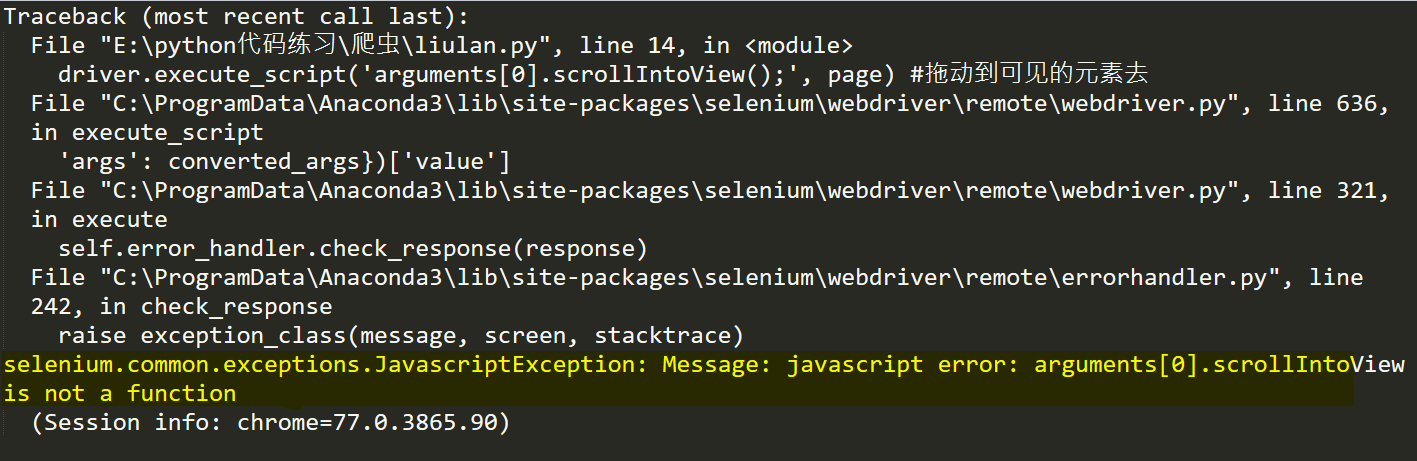
结果运行报错:
因为在百度文库页面底部需要点击“继续阅读”才可以加载到完整的页面,所以必须使用这两行代码
page=driver.find_elements_by_xpath("/html/body/div[2]/div[2]/div[6]/div[2]/div[2]/div[1]/div/div[1]")#使用page标记记录百度文库中向下翻页的位置 driver.execute_script('arguments[0].scrollIntoView();', page)
来将浏览器滚动到“继续阅读”这个位置,然后执行点击按钮。
但是却爆出了黄色部分的错误。找了好久,最后在stackoverflow上找到了答案,不得不说,stackoverflow还是强啊

这哥们说,
scrollIntoView()
这个函数是属于DOM API ,因此你应该使用一个web元素来调用它,而不是一个web元素列表来使用它。
这是我认识到,我可能定位的元素并不是一个,所以我又重新定位了一下元素,更改的代码如下:
from selenium import webdriver from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome('D:/chromedriver.exe') driver.get("https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html") page = driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/span/span[2]") driver.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去 driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
然后就可以自动的加载所有文档内容啦