

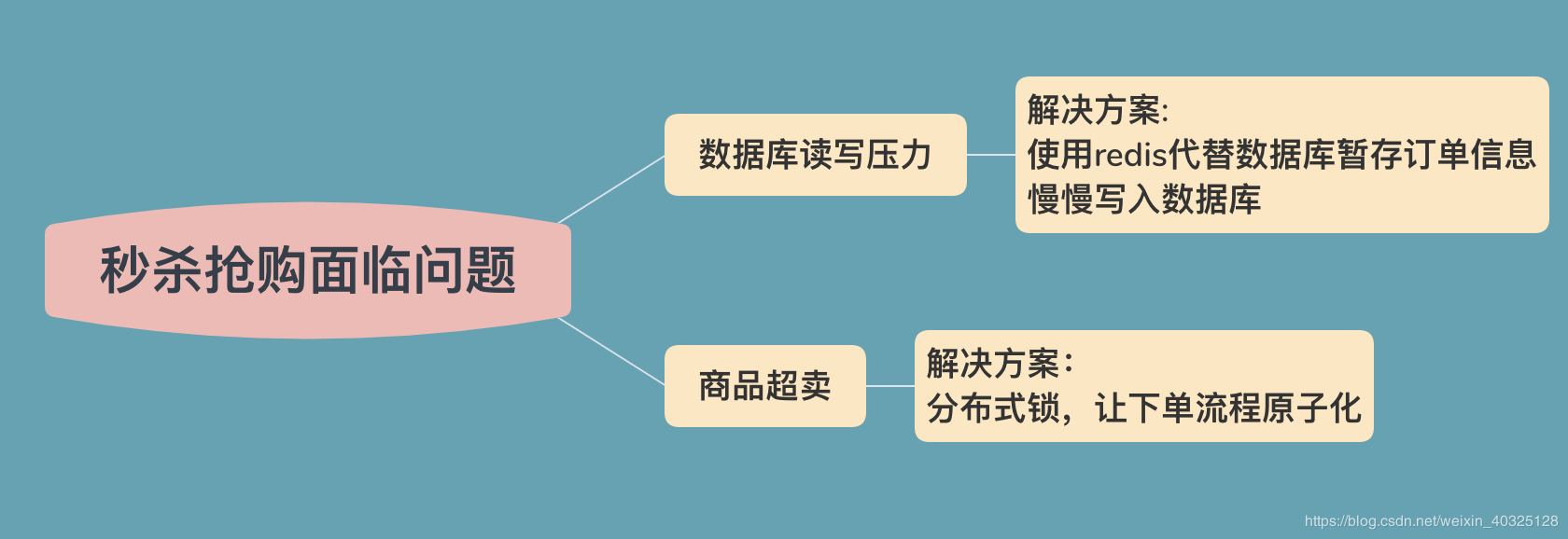
首先,想象一个场景,商品A预售量1000件,早上10点准时开抢,10W个人一起来抢,在正式开始之后,我们将面对两个问题
1 大批的数据库请求和大量的订单创建,数据库压力巨大,有可能宕机
2 商品可能出现超卖的情况
解决方案如下:
这里我们先看商品超卖的问题
最原始的下单流程无非就是: 判断商品库存是否足够 -> 足够则下单
这种处理方式在没什么并发的情况下不会出现问题,但是一旦并发量一大,这种流程就肯定会出现超卖
假设有A和B两个进程,A要买1个,B也要买1个,可是商品库存就剩下一个了,这两个进程同时进入库存判断,都通过了,然后进入:下单->减库存 最后结果就是商品库存变成了负数,这显然是不符合需求的
所以我们要做的就是,库存判断 ->下单 -> 减库存 让这整个流程原子化 ,要么都能执行,要么先等着,别上赶着。
我们利用redis的单线程,可以实现这一点,也就是俗称的分布式锁
网上关于分布式锁的做法良莠不齐,博主之前也陷入过误区,这里挨个给大家爬坑,抛砖引玉
为了让大家只关注这个锁的意义,这里关于商品过多的信息不作完整赘述,只做简单的举例
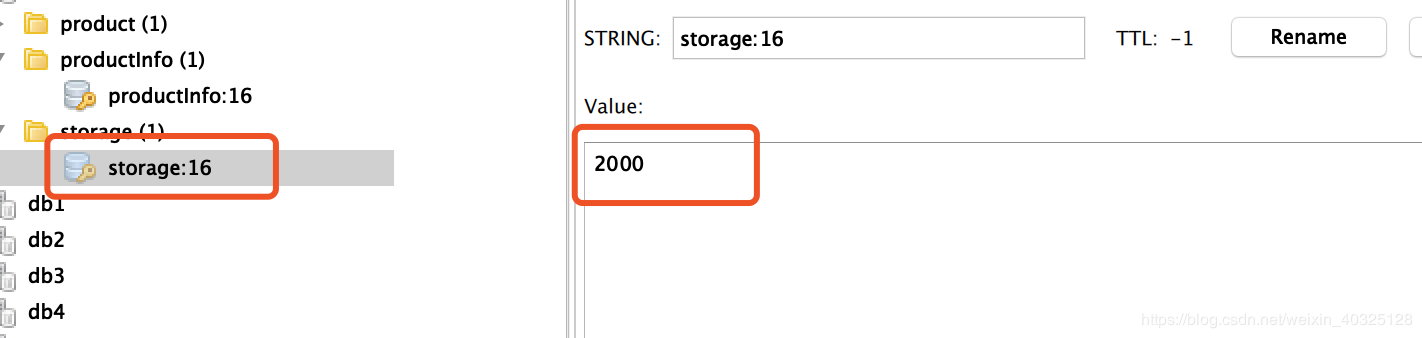
这里是redis中存放的商品信息:productInfo:16 指的是ID为16的商品信息(秒杀活动商品详情页打开非常频繁,建议缓存起来)
limitBuy 指的是这件商品的限购数量,一会用得上

storage:16 指的是ID为16的商品库存,也建议在添加抢购活动的时候就缓存到redis中
好,准备工作做好了,正式开始!
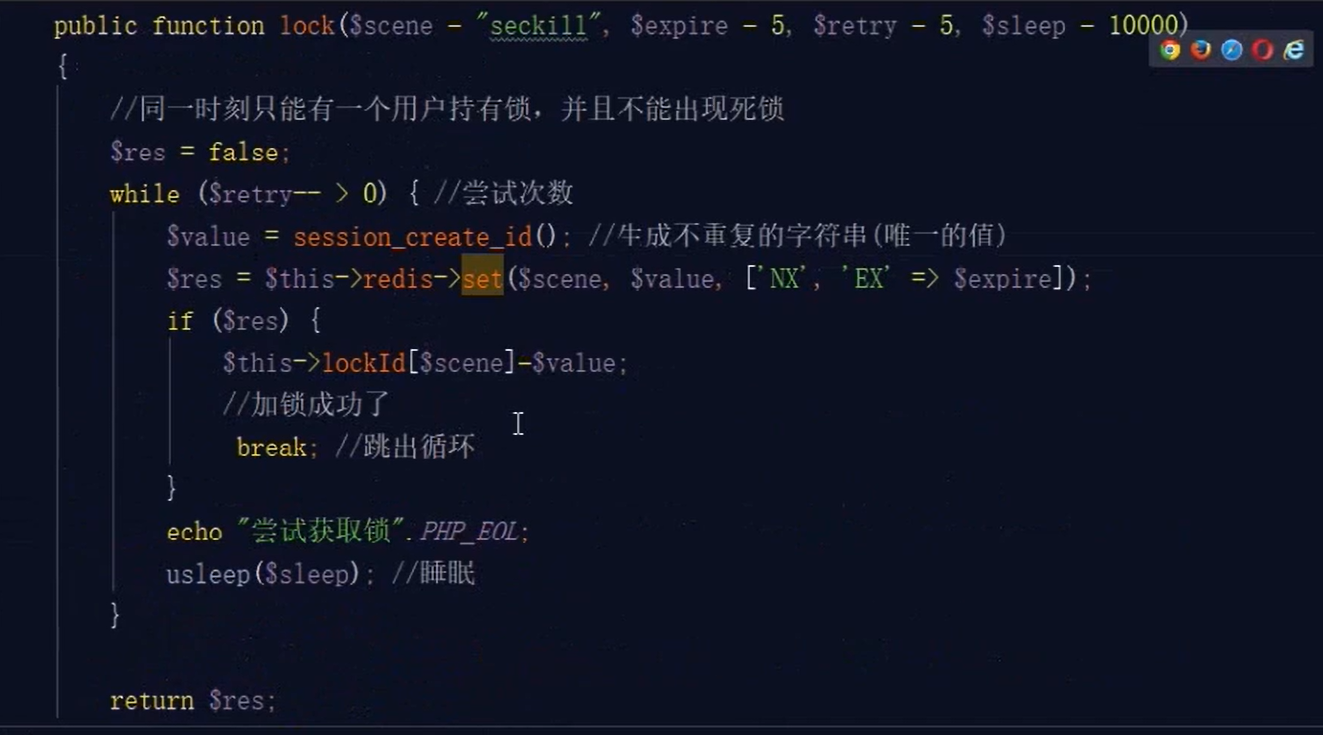
先上代码
$redis = new RedisService(); //购买数量不得大于限购数量 $productInfo = $redis->hashGet("productInfo:".$productId); if($productInfo['limitBuy'] < $num) { echo json_encode(["code"=>30017,"msg"=>'每人限购'.$productInfo['limitBuy']."件"]);die(); } //加分布式锁,原子化下单流程 $storageLockKey = "storage:".$productId; $expireTime = $redis ->lock($storageLockKey,5,200); //判断商品库存 $storageKey = $this->getStorageKey($productId); $storage = $redis->get($storageKey); if($storage <= 0 || $storage < $num) { $redis->unlock($storageLockKey,$expireTime); echo json_encode(["code"=>30018,"msg"=>'库存不足']);die(); } //欲购买数量+已购买数量 不得超过限购数量 $limitBuyKey = "product:limitBuy:".$productId; if($redis->getZsetScore($limitBuyKey,"user_".$userId)+$num > $productInfo['limitBuy']) { $redis->unlock($storageLockKey,$expireTime); echo json_encode(["code"=>30019,"msg"=>'每人限购'.$productInfo['limitBuy']."件"]);die(); } $orderInfo = array( 'buyer_id' => $userId,#用户ID 'product_id' => $productId,#产品ID 'num' => $num, #购买数量 'price'=>$productInfo['price'], 'pay_type'=>1 //在线支付 ); //订单放进队列 $orderKey = "orderList"; $orderRe = $redis->push($orderKey,serialize($orderInfo)); //下单成功 if($orderRe) { //获取原有集合元素个数 $count = $redis->countZset($limitBuyKey); //记录购买人和购买数量 $redis->alterZsetScore($limitBuyKey,"user_".$userId,$num); //如果是第一次插入元素,设置过期时间+3天,防止内存堆积 if(!$count) { $recordExpire = strtotime($productInfo['endTime']) - strtotime($productInfo['beginTime']) +3*24*3600; $redis->expire($limitBuyKey,$recordExpire); } //商品减少库存 $redis->alterNumber($storageKey,-$num); $redis->unlock($storageLockKey,$expireTime); echo json_encode(["code"=>200,"msg"=>'下单成功']);die(); }
可以看到,我们的下单流程是 加分布式锁 -> 判断库存 -> 限购 -> 订单信息放入Redis列表
我们重点来看这个分布式锁如何实现

这里的锁保存的值是一个过期时间的时间戳(毫秒级)

有人说为什么要记录个时间戳呢?为什么不直接利用redis的自动过期时间呢?
有两个原因:
1 redis的set设置健值 和 设置过期时间 是分开的,假设设置了健值,在设置过期时间之前,程序出错了,这个锁就没有过期时间了,就会一直存在redis中,形成死锁
2 把值设为过期时间,可以通过getset方法在设置新过期时间的时候,取得旧的过期时间,判断是否已经被别的进程抢先获得锁
看这段代码:
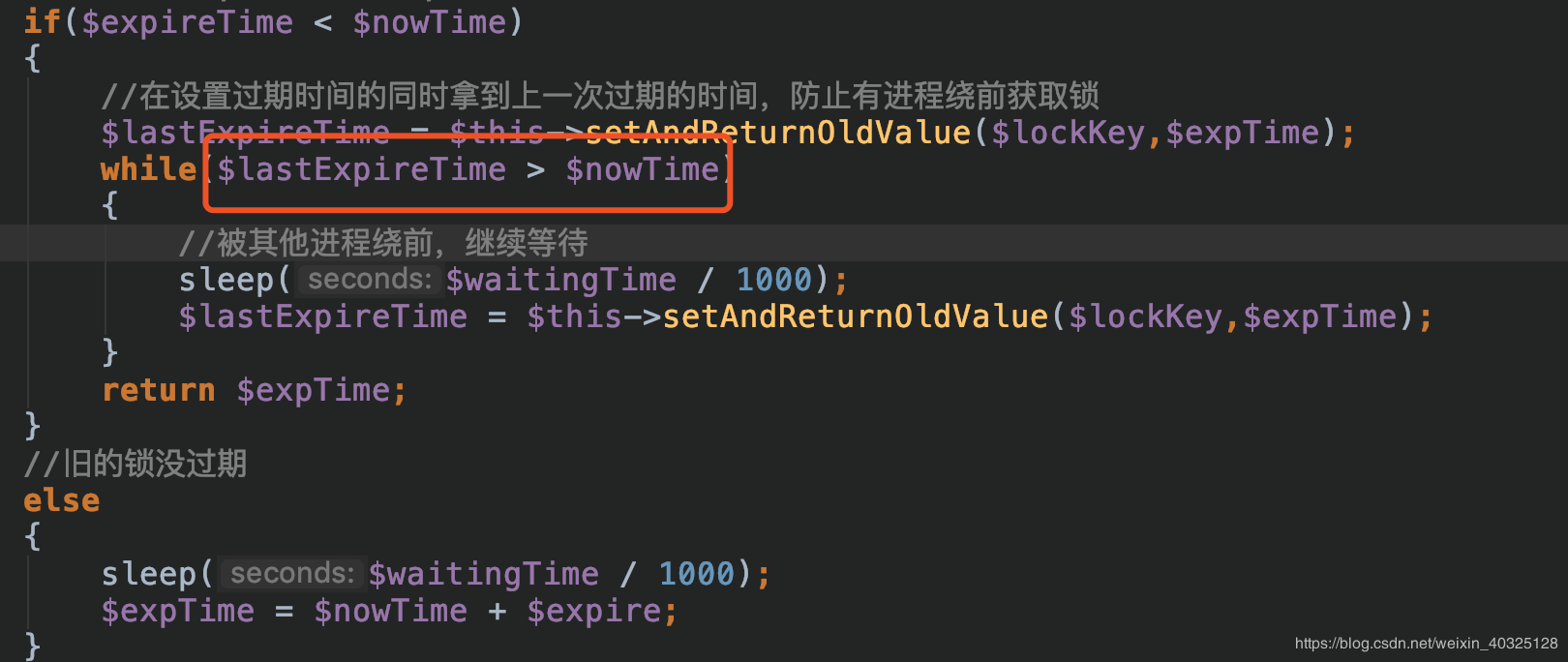
流程解释:
setnx 判断当前是否有锁
当前没有锁,则获得锁,返回过期时间
当前有锁,判断锁是否过期
如果过期则更新过期时间,getset获得锁,判断返回的的过期时间是否已经被抢先重置了,被抢先则等待20毫秒,没被抢先则返回过期时间
没有过期则等待20毫秒
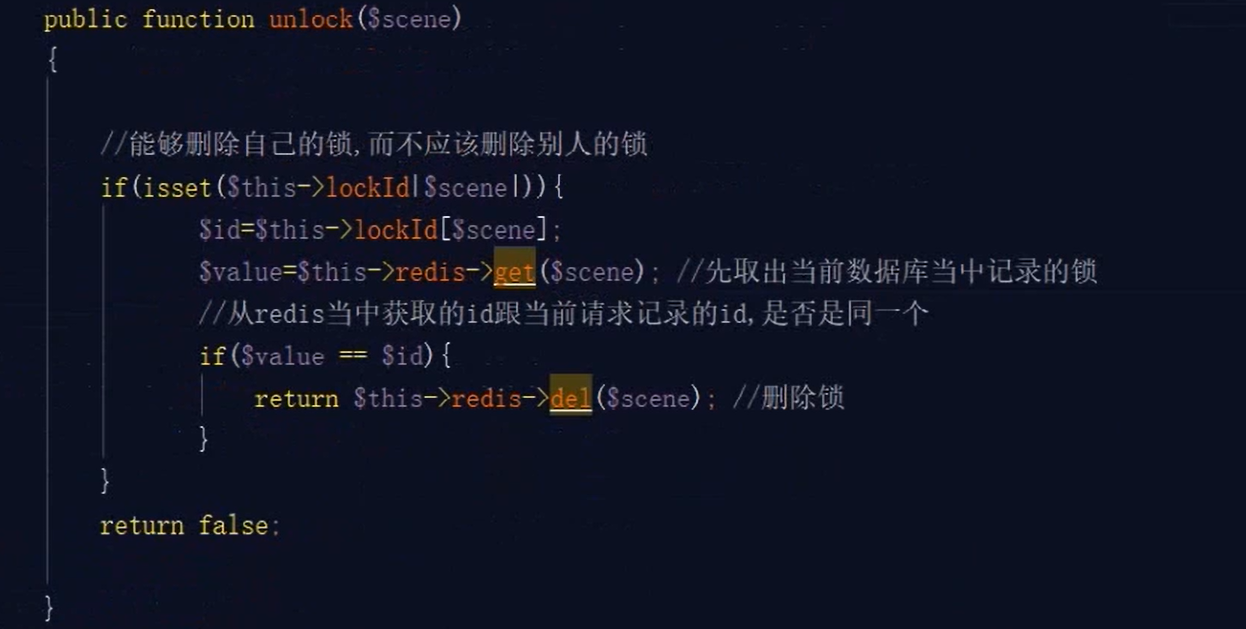
返回的过期时间,是为了解锁的时候配对上,谁加的锁,只有谁能解。防止执行时间过长的进程解掉了别人的锁,把后面的进程放进来
这样,分布式锁基本就完成了,解锁的时候直接让锁过期即可
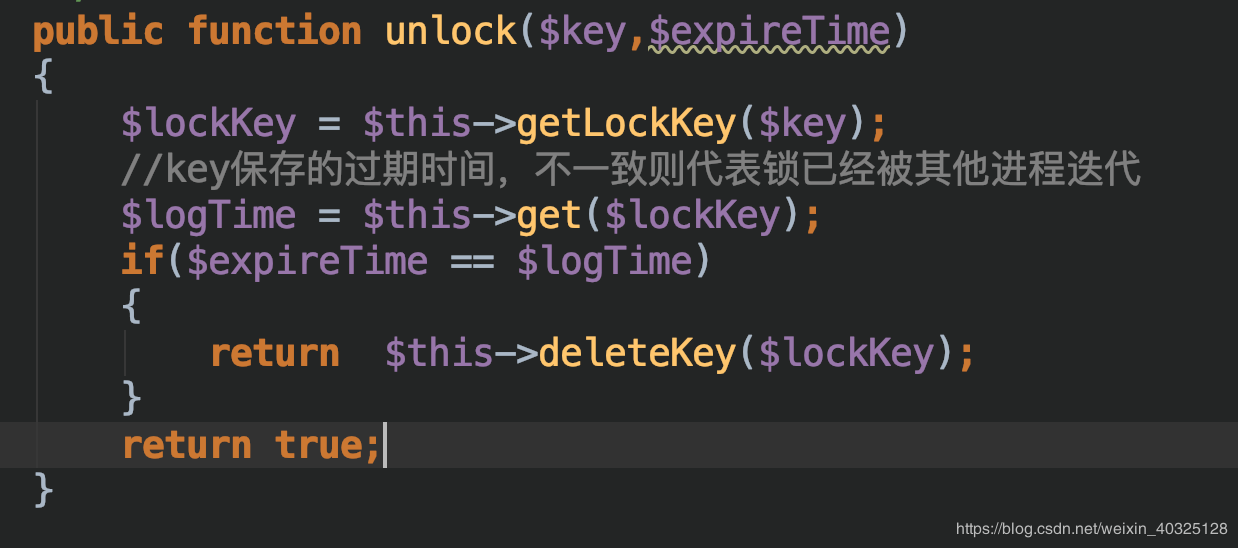
这样就可以保证 永远只有一个进程获得锁,永远只有一个进程在进行库存的相关判断和操作,防止超卖
我们进行测试:
商品库存为2000

并发5000次请求
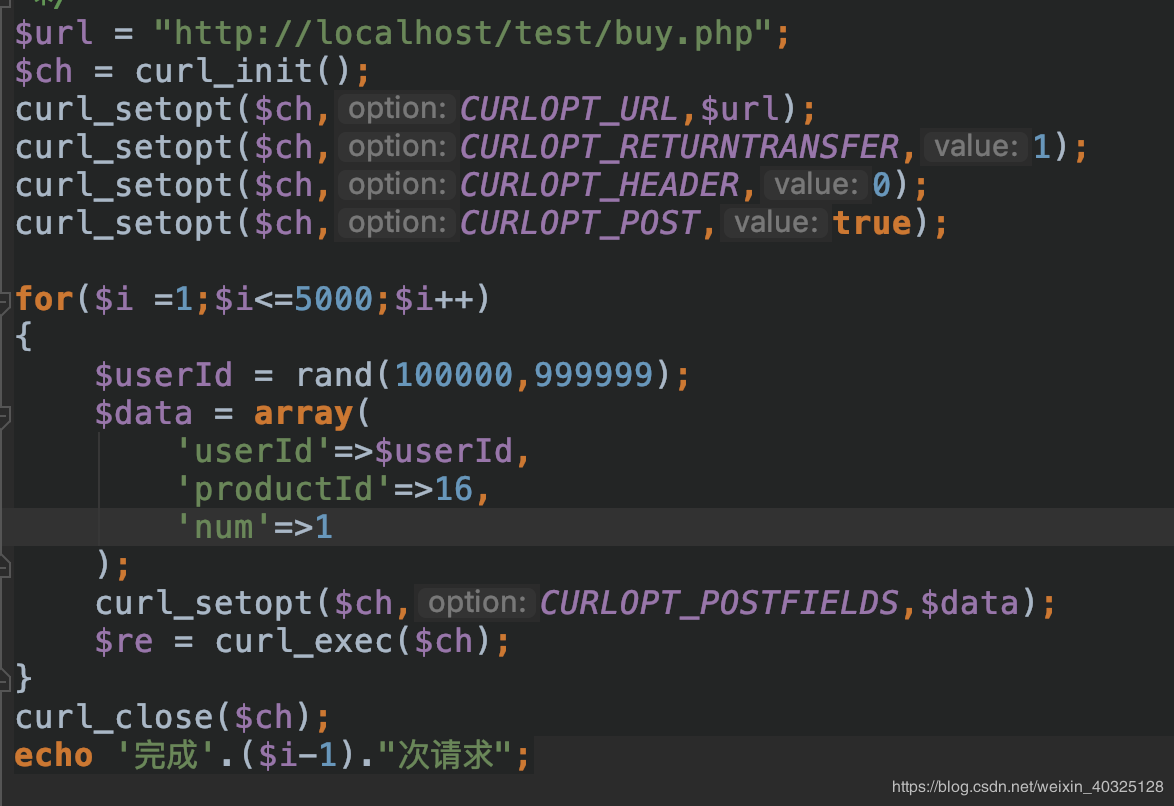
10秒完成,平均每秒500个并发

可以每人买一件的话,生成了2000个订单,写入redis列表
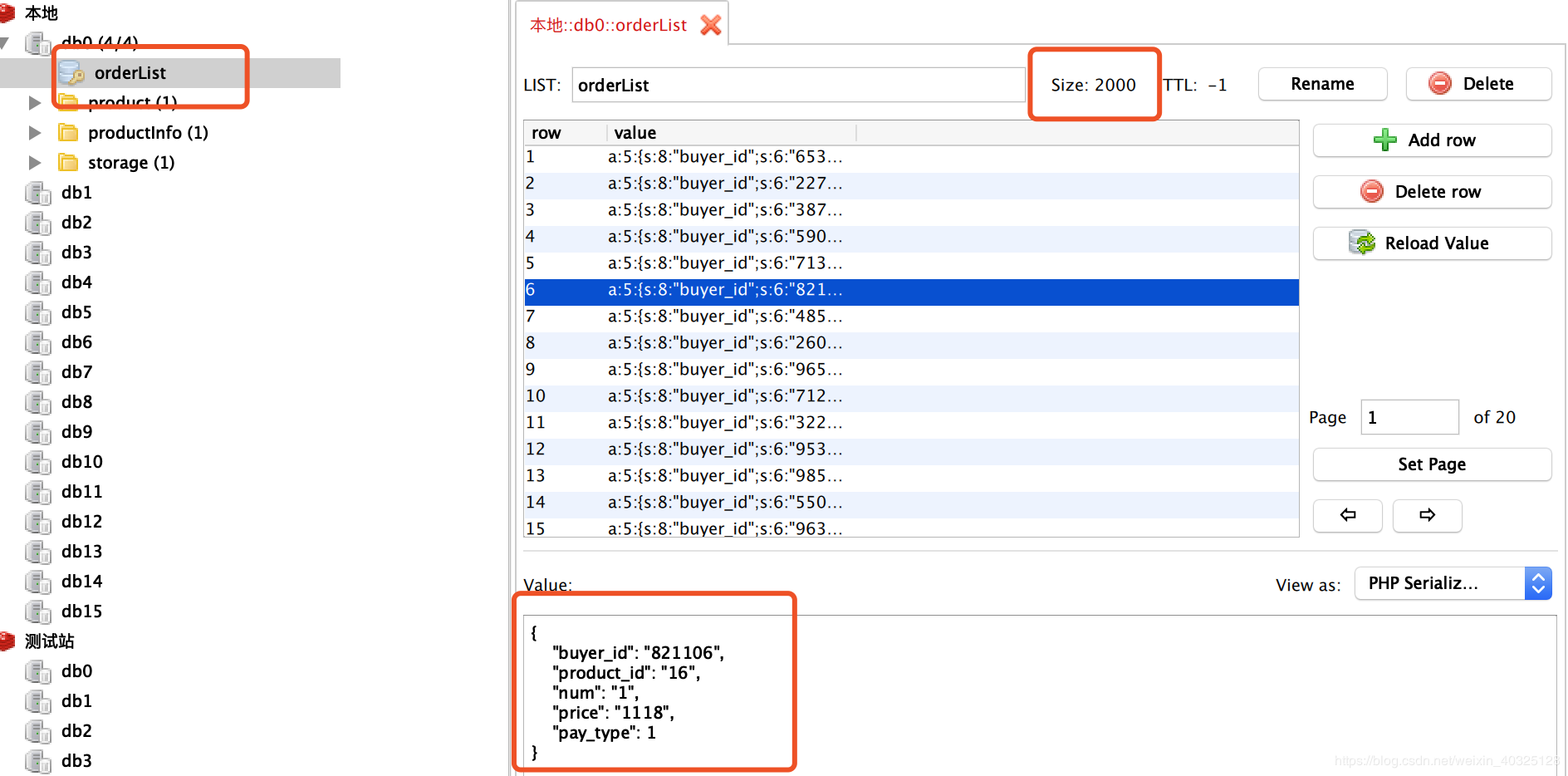
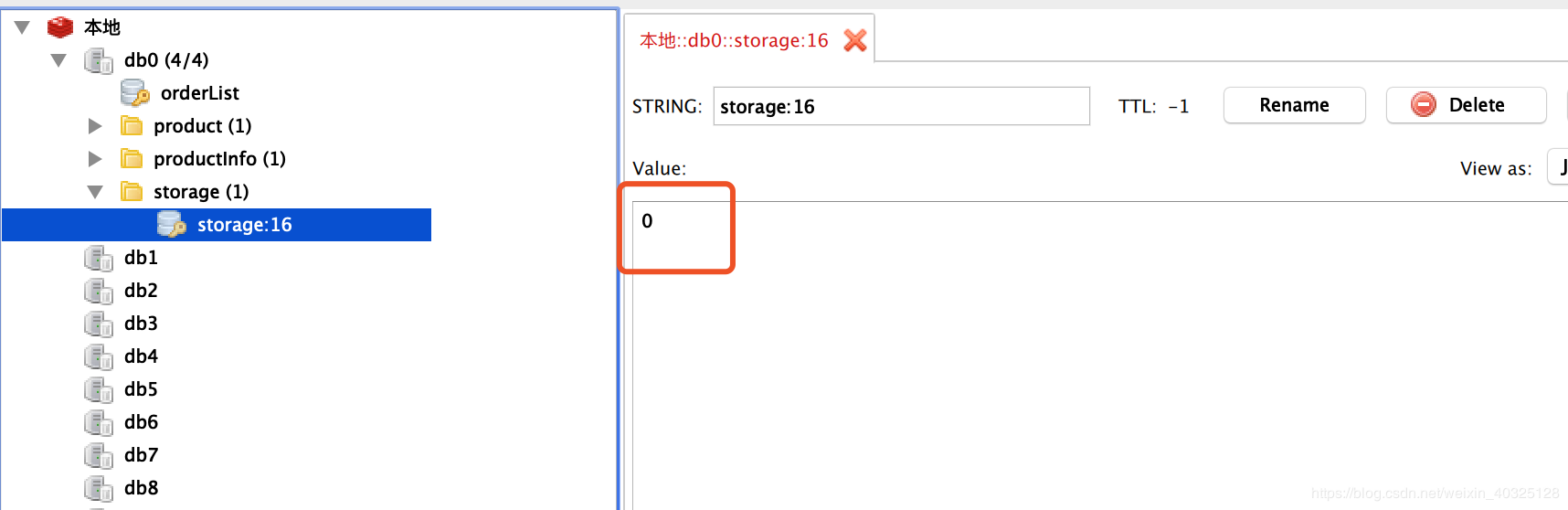
库存为0 没有出现超卖的情况
接下来后来启动个定时任务,每分钟启动一次,每次弹出3000个元素,写入数据库

linux添加定时任务

过一分钟我们看到,队列里的订单已被弹出批量写入数据库了

在这个过程中,我们这两个问题都得到了较好地解决
订单先写入redis 后台慢慢写入数据库,缓解了数据库写的压力
产品详情在后台发布秒杀活动的时候,就写入redis缓存,前段获取产品详情页的时候不会走数据库,缓解读的压力
redis分布式锁,让整个下单流程原子化,只允许一个进程进行下单,防止了超卖的情况
好了就到这,有什么经验 再跟大家分享
————————————————
原文链接:https://blog.csdn.net/weixin_40325128/java/article/details/89378834