
1、Motivation
这个论文的思想非常简单:将CNN和 VIT 结合,浅层用CNN,深层用VIT。 同时,在attention 分支添加一个卷积层分支。
2、Method
网络整体架构如下图所示,包括三个 Reduction Cell (RC) 和若干 Normal Cell(NC)。
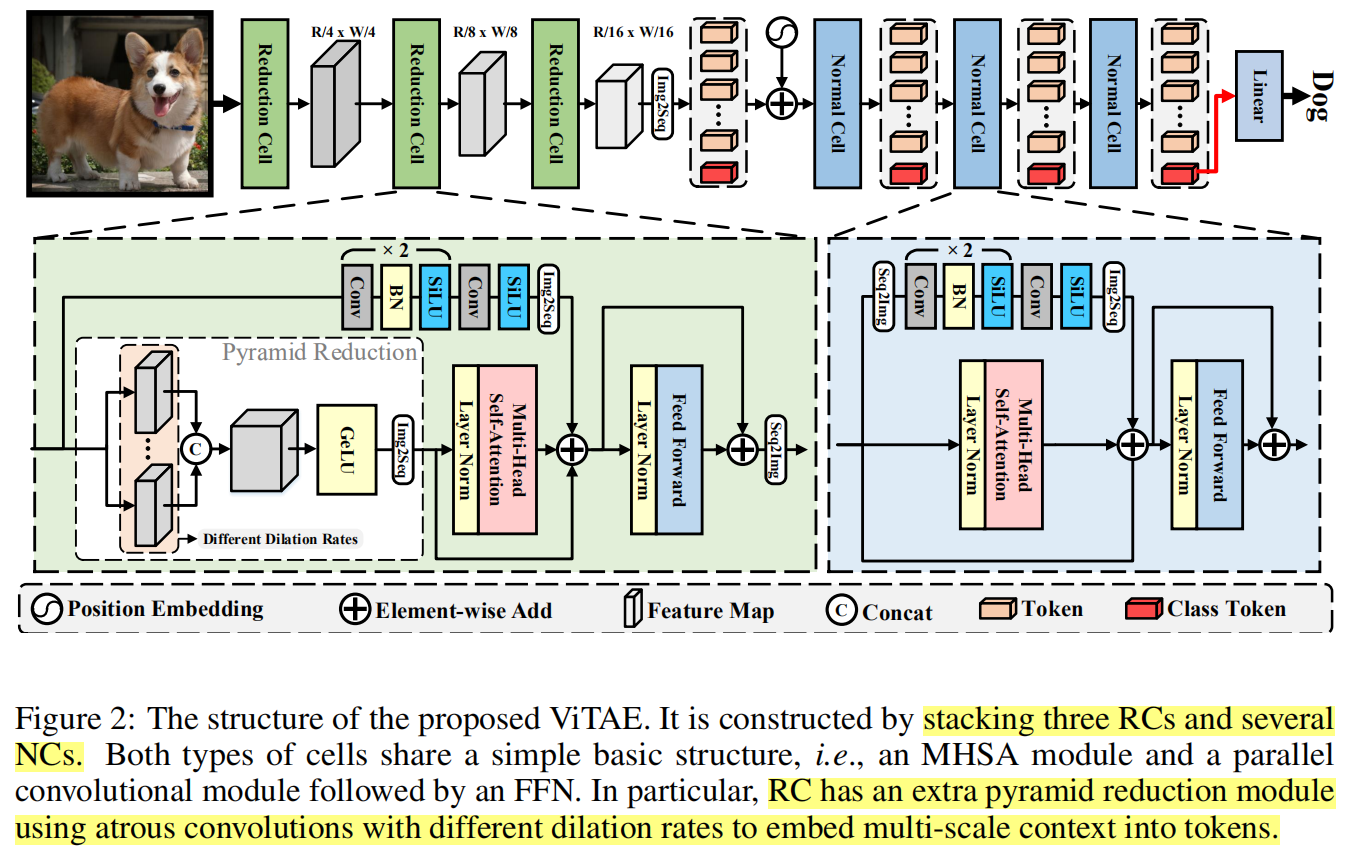
RC 模块
和 VIT 的 Transformer block 相比,RC多了一个 pyramid reduction ,就是多尺度空洞卷积并行,最终拼接成一个。同时,在 shortcut 里,多了3个卷积。最后,还要 seq2img 转成 feature map。
NC 模块
和VIT的 transformer block 有区别的地方就是计算 attention 那里多了一个卷积分支。
3、有趣的地方
从openreview的意见来看,审稿人认可的 strong points:
- The idea of injecting multi-scale features is interesting and promising.
- The paper is well written and easy to follow.
同时,论文也存在一些薄弱环节:
- The paper use an additional conv branch together with the self-attention branch to construct the new network architecture, it is obvious that the extra conv layers will help to improve the performance of the network. The proposed network modification looks a little bit incremental and not very interesting to me.
- There are no results on the downstream object detection and segmentation tasks, since this paper aims to introduce the inductive bias on the visual structure.
- The proposed method is mainly verified on small input images. Thus, I am a little bit concerned about its memory consumption and running speed when applied on large images (as segmentation or detection typically uses large image resolutions).