过去一年,谷歌提出的VIT成为最火的模型,说明全部由Self-attention组成的模型会超越CNN。但最近学者又在反思,问题的本质是什么?
-
2021年5月,谷歌挖坑 MLP-Mixer ,说明保持VIT的图像序列化输入,使用全连接网络,就可以取得非常好的性能
-
2021年10月,ICLR2022的一个投稿论文《Patches are all your need》(只有4页),直接用 depth-wise 卷积替换了VIT的注意力模块,同样取得非常好的性能。但也有overclaim的嫌疑,因为该论文用的7x7大小的 token,VIT为16x16,可能性能提升是因为使用了更小的 token。
-
2021年11月,颜水成组提出,Transformer的成功来自于整体架构,他们把Transformer中的注意力模块替换成了简单的空间池化算子(原文中说是embarrassingly simple),但性能很好。
token mixer 过去一年科研人员做了很多工作,self-attention、spatial mlp、depth conv、fft,以及 pooling 都能取得非常好的性能。所以,目前国内外研究某种程度上也陷入了混战期,大家都在发表论文,但涨点的核心本质原因并不明确。
本周记录两个论文,MAE 和 TransMix。
1、MAE
Masked Autoencoders Are Scalable Vision Learners,何恺明大神最新的工作。
这个论文思想特别简单,就是掩盖住图片中的一部分让模型预测。其实NLP自监督的方法就是遮盖住一部分文字,让模型来预测遮盖住的那部分。但这个思想一直没有用于CV里面来。这个论文还有一个有趣的地方:一个公式都没有。模型越简单,也会越凸显其思路的厉害。现在大多人做科研就是在想着加公式,加步骤,加loss,确实境界不一样 ... ...
论文框架如图所示,Encoder 采取VIT的处理方式,将图像划分为规则的非重叠patch,然后随机采样25%的patch输入到VIT 的特征提取器。对于Decoder,将全部 patch输入其中,这个Decoder只在预训练过程中使用,很轻量(论文中的描述为 narrower and shallower than the Encoder, 只有Encoder 10% 的计算量),这样可以减少预训练时的成本。
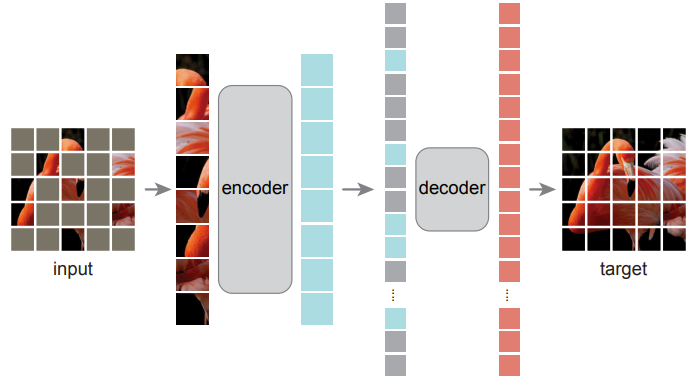
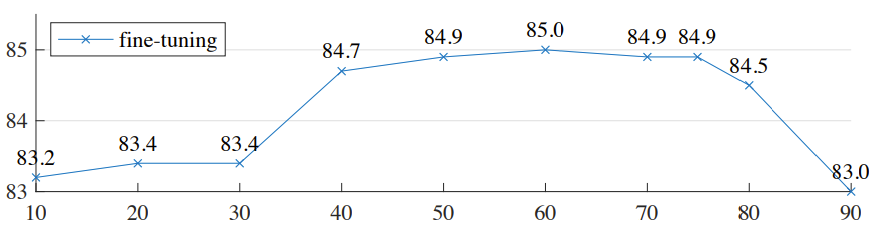
论文中比较神奇的一点是下面的实验,当 mask ratio 过多或者过少时,性能都不够好。这是因为,当 mask ratio 过少时,网络倾向于修复图像细节,无法获得图像的高层语义信息。当 mask ratio 过大时,网络就无法捕捉到图像内容了。mask ratio 取60%到75%时,性能较好。在准确率允许的条件下,丢弃更多的patch有助于降低编码器的计算量,因此作者选择 mask ratio = 75%。
2、TransMix
TransMix: Attend to Mix for Vision Transformers, 这是来自Johns Hopkins大学,牛津大学和字节跳动的工作,尽管题目里说是为 transformer设计的,实际可以用于任何网络。

这个工作解决了之前 Mixup 和 CutMix 的一个痛点:并非所有像素是相等的,如上图所示,背景中的像素对于标签的贡献并不大。
这个工作就是基于 VIT 的 attention map 来融合标签,正常VIT有196个 patch,因此可以最后一个 Transformer Block 的中间输出,即得到Attention map \(A\)。整个算法的代码如下图所示,也非常容易理解。

论文实验部分的一个图很好的说明了TransMix的效果。通过比较 attention map,TransMix很好的修正的 label 的比例权重。
