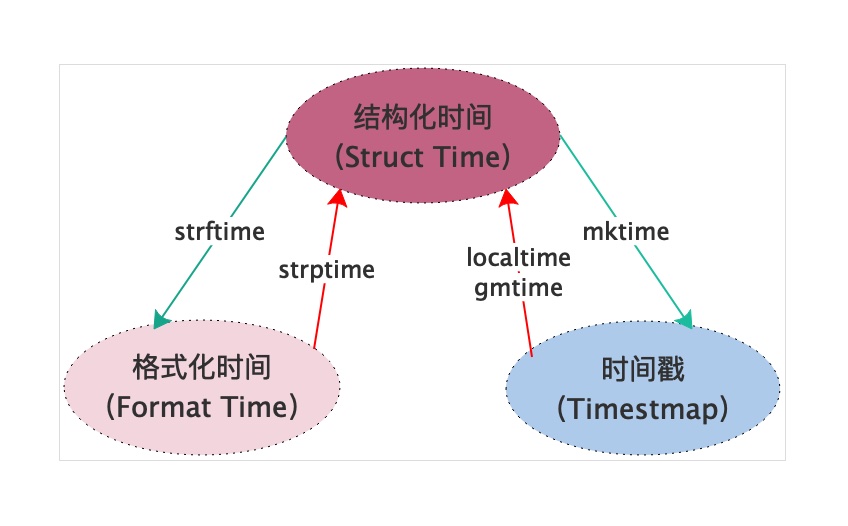
time模块
打印时间戳、格式化时间、结构化时间,总而言之就是打印不同类型的时间,进行不同类型时间的转换
import time
# 时间戳
time.time() (*****)
# 格式化时间
time.strftime('%Y-%m-%d %X')
# 结构化时间
time.localtime() # 北京时间
time.gmtime() # 格林威治时间
time.gmtime(0) # 1970/1/1/0:00
# 时间的转换(了解中的了解)
# 结构化时间转换为时间戳
now = time.localtime()
time.mktime(now)
# 结构化时间转格式化时间
time.strftime('%Y-%m-%d %X', now) # 2019-06-11 08:45:30
time.strftime('%Y-%m-%d', now) # 2019-06-11
# 格式化时间转结构化时间
now = time.strftime('%Y-%m-%d %X')
time.strptime(now,'%Y-%m-%d %X')
time.strptime('2019|06|11', '%Y|%m|%d')
# 时间戳转化为结构化时间
now = time.time()
time.localtime(now)
# 睡眠
time.sleep(n) # 暂停程序n秒(*****)
datetime模块
用于时间的加减
import datetime
now = datetime.datetime.now() #返回当前时间 (*****)牢记
now + datetime.timedelta(3) # +3day
now - datetime.timedelta(3) # -3day
now + datetime.timedelta(-3) # -3day
now + datetime.timedelta(minutes=3) # +3minutes
now + datetime.timedelta(seconds=3) # +3seconds
now + datetime.timedelta(365) # +1year
now.replace(year=2012, month=12, day=22, hour=5, minute=13, second=14)
random模块
随机数,随机取容器元素
import random
# (0,1) (*****)
random.random()
# [1,3] 的整数 (*****)
random.randint(1,3)
# [1,3] 的小数
random.uniform(1,3)
# [1,3) 的整数
random.randrange(1,3)
# 取容器中的一个元素 (*****)
random.choice([1,2,3])
# 取容器中的多个元素
random.sample([1,2,3],2)
# 打乱容器 (*****)
lis = [1,3,4]
random.shuffle(lis)
os模块
与操作系统交互,一般用来操作文件夹和文件
import os
# 新建一个文件夹
os.mkdir(path)
# 新建一个文件
f = open('','w',encoding='utf8')
f.close()
# 删除一个文件(*****)
os.remove(path)
# 重命名一个文件(*****)
os.rename(path)
# 删除空文件
os.removedirs(path)
# 删除一个空文件
os.rmdir(path)
# 拼接文件(*****)
os.path.join(path)
# 列出文件夹下所有内容(*****)
os.listdir(path)
# 获取文件大小(*****)
os.path.getsize(path)
# 获取文件夹下所有的文件夹和文件(*****)
os.walk(path)
# 当前当前项目路径
os.getcwd(path)
# 获取文件路径(*****)
os.path.dirname(os.path.dirname(__file__))
# 判断文件是否存在(*****)
os.path.exists(path)
# 执行linux命令
os.system('cd c:')
# 获取文件的绝对路径(*****)
os.path.abspath(__file__) # 获取当前文件的绝对路径
os.path.abspath(path) # 获取某一个文件的绝对路径
sys模块
与python解释器交互
import sys
# 获取当前文件的环境变量,就是模块的搜索路径(*****)
sys.path
sys.path.append # 添加环境变量
# 当终端 python test.py 参数1 参数2 ... 执行python文件的时候会接收参数(*****)
sys.argv
# 标准输出
sys.stdout.write()
# 标准输入
sys.stdin.read(n) # 读取的字符,如果输出过多的字符,只接受n个
json模块
序列化:把数据从内存到硬盘,对于json而言,需要按照json的标准
dict/list/str/int/float/bool/none
反序列化:把json形式的数据从硬盘读入内存
优点:跨平台性/跨语言传输数据
缺点:不能保存函数之类的数据类型,保存的类型为字符串形式
import json
# 内存中转换的
dic = {'name':'nick'}
# 了解
res = json.dumps(dic)
json.loads(res)
def write_json(filename, dic):
with open(filename,'w',encoding='utf8') as fw:
json.dump(dic, fw) (*****)
def read_json(filename):
with open(filename,'r',encoding='utd8') as fr:
data = json.load(fr) (*****)
return data
pickle模块
优点:能存储python的任意类型数据
缺点:无法跨平台,保存的数据为二进制类型
import pickle
# 内存中转换的
def func():
pass
# 了解
res = pickle.dumps(func)
pickle.loads(res)
def write_pickle(filename, func):
with open(filename,'wb') as fw:
pickle.dump(func, fw) (*****)
def read_pickle(filename):
with open(filename,'rb') as fr:
data = pickle.load(fr) (*****)
return data
hashlib模块
hash是什么
hash是一种算法(Python3.版本里使用hashlib模块代替了md5模块和sha模块,主要提供 SHA1、SHA224、SHA256、SHA384、SHA512、MD5 算法),该算法接受传入的内容,经过运算得到一串hash值。
hash值的特点:
- 只要传入的内容一样,得到的hash值一样,可用于非明文密码传输时密码校验
- 不能由hash值返解成内容,即可以保证非明文密码的安全性
- 只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的,可以用于对文本的哈希处理
import hashlib
m = hashlib.md5()
m.update('hello'.encode('utf8'))
print(m.hexdigest())
5d41402abc4b2a76b9719d911017c592
m.update('hash'.encode('utf8'))
print(m.hexdigest())
97fa850988687b8ceb12d773347f7712
m2 = hashlib.md5()
m2.update('hellohash'.encode('utf8'))
print(m2.hexdigest())
97fa850988687b8ceb12d773347f7712
撞库破解hash算法加密
hash加密算法虽然看起来很厉害,但是他是存在一定的缺陷的,即可以通过撞库可以反解,如下代码所示:
import hashlib
# 假定我们知道hash的微信会设置如下几个密码
pwd_list = [
'hash3714',
'hash1313',
'hash94139413',
'hash123456',
'123456hash',
'h123ash',
]
def make_pwd_dic(pwd_list):
dic = {}
for pwd in pwd_list:
m = hashlib.md5()
m.update(pwd.encode('utf-8'))
dic[pwd] = m.hexdigest()
return dic
def break_code(hash_pwd, pwd_dic):
for k, v in pwd_dic.items():
if v == hash_pwd:
print(f'hash的微信的密码是{k}')
hash_pwd = '0562b36c3c5a3925dbe3c4d32a4f2ba2'
break_code(hash_pwd, make_pwd_dic(pwd_list))
hash的微信的密码是hash123456
hmac模块
为了防止密码被撞库,我们可以使用python中的另一个hmac 模块,它内部对我们创建key和内容做过某种处理后再加密。
如果要保证hmac模块最终结果一致,必须保证:
- hmac.new括号内指定的初始key一样
- 无论update多少次,校验的内容累加到一起是一样的内容
import hmac
# 注意hmac模块只接受二进制数据的加密
h1 = hmac.new(b'hash')
h1.update(b'hello')
h1.update(b'world')
print(h1.hexdigest())
905f549c5722b5850d602862c34a763e
h2 = hmac.new(b'hash')
h2.update(b'helloworld')
print(h2.hexdigest())
905f549c5722b5850d602862c34a763e
h3 = hmac.new(b'hashhelloworld')
print(h3.hexdigest())
a7e524ade8ac5f7f33f3a39a8f63fd25
logging模块
日志总共分为以下五个级别,这个五个级别自下而上进行匹配 debug-->info-->warning-->error-->critical,默认最低级别为warning级别。
logging模块包含四种角色:logger、Filter、Formatter对象、Handler
- logger:产生日志的对象
- Filter:过滤日志的对象
- Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式
- Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端
打印日志:
'''
critical=50
error =40
warning =30
info = 20
debug =10
'''
import logging
# 1、logger对象:负责产生日志,然后交给Filter过滤,然后交给不同的Handler输出
logger = logging.getLogger(__file__)
# 2、Filter对象:不常用,略
# 3、Handler对象:接收logger传来的日志,然后控制输出
h1 = logging.FileHandler('t1.log') # 打印到文件
h2 = logging.FileHandler('t2.log') # 打印到文件
sm = logging.StreamHandler() # 打印到终端
# 4、Formatter对象:日志格式
formmater1 = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
formmater2 = logging.Formatter('%(asctime)s : %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
formmater3 = logging.Formatter('%(name)s %(message)s',)
# 5、为Handler对象绑定格式
h1.setFormatter(formmater1)
h2.setFormatter(formmater2)
sm.setFormatter(formmater3)
# 6、将Handler添加给logger并设置日志级别
logger.addHandler(h1)
logger.addHandler(h2)
logger.addHandler(sm)
# 设置日志级别,可以在两个关卡进行设置logger与handler
# logger是第一级过滤,然后才能到handler
logger.setLevel(30)
h1.setLevel(10)
h2.setLevel(10)
sm.setLevel(10)
# 7、测试
logger.debug('debug')
logger.info('info')
logger.warning('warning')
logger.error('error')
logger.critical('critical')