主题模型
主题模型可以从一系列文章中自动推测讨论的主题。这些主题可以被用作总结和整理文章,也可以在机器学习流程的后期阶段用于特征化和降维。
https://blog.csdn.net/qq_34531825/article/details/52608003
一、简介
LDA-隐含迪利克雷分配,latent dirichlet allocation,是一种主题模型,也就是从收集的文档中推测主题。甚至说LDA模型现在已经成为了主题建模的一个标准,是实践中最成功的主题模型止一。主题就是一篇文章、一段话、一个句子所表达的中心思想,从统计模型的角度来说,我们用一个特定的词频来刻画主题,并认为上述的文章、句子、话是从一个概率模型中生成的。也就是说主题模型中,主题表现为一系列相关的单次,是这些单次的条件概率。形象来说,主题就是一个桶,里面装了出现概率较高的单次,这些单次与这个主题有很强的相关性。
LDA可以用来识别大规模文档集或语料库中潜藏的主题信息。它采用了词袋的方法,将每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信息。但是词袋的方法并没有考虑词与词之间的顺序,这简化了问题的复杂性。同时为模型的改进提供了方案,每一篇文档代表一些主题构成的概率分布,而每一个主题又代表了很多单次所构成的一个概率分布。
LDA可以被认为是如下的一个聚类过程:
(1)各个主题(Topics)对应于各类的“质心”,每一篇文档被视为数据集中的一个样本。
(2)主题和文档都被认为存在一个向量空间中,这个向量空间中的每个特征向量都是词频(词袋模型)
(3)与采用传统聚类方法中采用距离公式来衡量不同的是,LDA使用一个基于统计模型的方程,而这个统计模型揭示出这些文档都是怎么产生的。
Latent Dirichlet allocation (LDA) is a topic model which infers topics from a collection of text documents. LDA can be thought of as a clustering algorithm as follows:
(1)Topics correspond to cluster centers, and documents correspond to examples (rows) in a dataset.
(2)Topics and documents both exist in a feature space, where feature vectors are vectors of word counts (bag of words).
(3)Rather than estimating a clustering using a traditional distance, LDA uses a function based on a statistical model of how text documents are generated.
它基于一个常识性假设-文档集合中的所有文本均共享一定数量的隐含主题。基于该假设,它将整个文档集特征化 为 隐含主题的集合,而每篇文本被表示为这儿写隐含主题的特定比例的混合。
例如:下图中,每个主题对应相关的词语
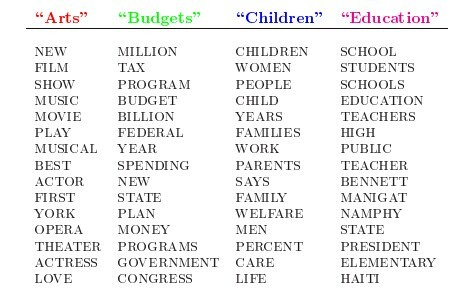
根据这些词语生成如下文章:

表面上理解LDA比较简单,无非就是:当看到一篇文章后,我们往往喜欢推测这篇文章是如何生成的,我们可能会认为某个作者先确定这篇文章的几个主题,然后围绕这几个主题遣词造句,表达成文。