什么是虚拟DOM
接下来用vdom(Virtual DOM)来简称为虚拟DOM。
指的是用JS模拟的DOM结构,将DOM变化的对比放在JS层来做。换而言之,虚拟DOM就是JS对象。
如下DOM结构:
<ul id="list"> <li class="item">Item1</li> <li class="item">Item2</li> </ul>
映射成虚拟DOM就是这样:
{ tag: "ul", attrs: { id: "list" }, children: [ { tag: "li", attrs: { className: "item" }, children: ["Item1"] }, { tag: "li", attrs: { className: "item" }, children: ["Item2"] } ] }
React会去调用render()方法来重新渲染整个组件的UI,但是如果我们真的去操作这么大量的DOM,显然性能是堪忧的。所以React实现了一个Virtual DOM,组件的真实DOM结构和Virtual DOM之间有一个映射的关系,React在虚拟DOM上实现了一个diff算法,当render()去重新渲染组件的时候,diff会找到需要变更的DOM,然后再把修改更新到浏览器上面的真实DOM上,所以,React并不是渲染了整个DOM树,Virtual DOM就是JS数据结构,所以 理论上原生的DOM快得多。
为什么使用 virtual dom
现有一个例子:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>eg</title> </head> <body> <div id="box"></div> <button id="btn">点击</button> <script src="https://cdn.bootcss.com/jquery/3.2.0/jquery.js"></script> <script> const data = ['哈哈', '呵呵','嘿嘿'] //渲染函数 function render(data) { const $box = $('#box'); $box.html(''); const $ul = $('<ul>'); // 重绘一次 $ul.append($('<li>10</li>')); data.forEach(item => { //每次进入都重绘 $ul.append($(`<li>${item}</li>`)) }) $box.append($ul); } $('#btn').click(function () { data[1] = data[1] + '嘿'; render(data); }); render(data) </script> </body> </html>
virtual dom 基本步骤
①用JS对象构建一颗虚拟DOM树,然后用虚拟树构建一颗真实的DOM树,然后插入到文档中。
②当状态变更时,重新构造一颗新的对象树,然后新树旧树进行比较,记录两树差异。
③把步骤2的差异应用到步骤1所构建的真实DOM树上,视图就更新了。
虚拟DOM的优点还有:
1、函数式的UI编程,即UI = f(data)这种构建UI的模式。
2、可以将JS对象渲染到浏览器DOM以外的环境中,也就是支持了跨平台开发,比如ReactNative。
diff算法
React的 virtual dom的性能好也离不开它本身特殊的diff算法。传统的diff算法时间复杂度达到o(n3),而react的diff算法时间复杂度只是o(n),react的diff能减少到o(n)依靠的是react diff的三大策略。
传统diff 对比 react diff
传统的diff算法追求的是“完全”以及“最小”,而react diff则是放弃了这两种追求:
在传统的diff算法下,对比前后两个节点,如果发现节点改变了,会继续去比较节点的子节点,一层一层去对比。就这样循环递归去进行对比,复杂度就达到了o(n3),n是树的节点数,想象一下如果这棵树有1000个节点,我们得执行上十亿次比较,这种量级的对比次数,时间基本要用秒来做计数单位了。那么react究竟是如何把复杂度降低到o(n)的呢?
React diff 三大策略
策略一(tree diff):Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计。(DOM结构发生改变-----直接卸载并重新creat)
策略二(component diff):DOM结构一样-----不会卸载,但是会update
策略三(element diff):所有同一层级的子节点.他们都可以通过key来区分-----同时遵循1.2两点
虚拟DOM树分层比较(tree diff)
两棵树只会对同一层次的节点进行比较,忽略DOM节点跨层级的移动操作。React只会对相同颜色方框内的DOM节点进行比较,即同一个父节点下的所有子节点。当发现节点已经不存在,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。这样只需要对树进行一次遍历,便能完成整个DOM树的比较。由此一来,最直接的提升就是复杂度变为线型增长而不是原先的指数增长。
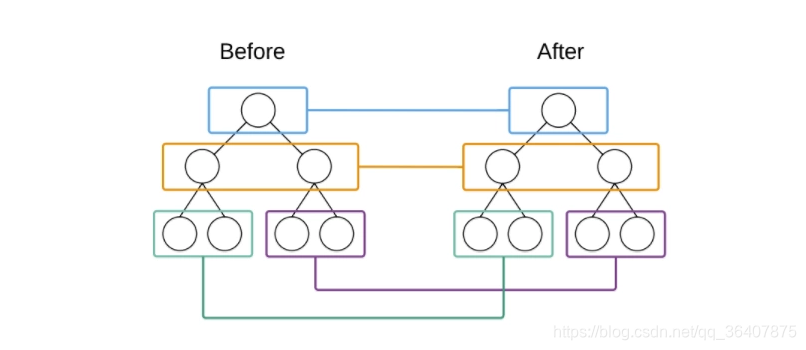
但是如果DOM节点出现了跨层级操作,diff会如何处理?
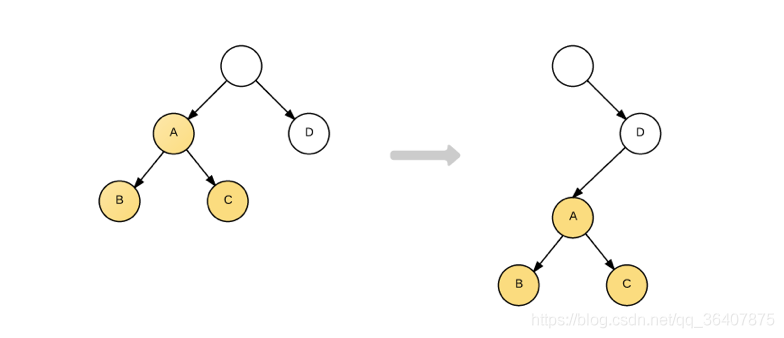
就比如上图,A节点及其子节点进行移动挂到另一个DOM下时,React是不会机智的判断出子树仅仅是发生了移动,而是会直接销毁,并重新创建这个子树,然后再挂在到目标DOM上。实际上,React官方也并不推荐我们做出跨层级的骚操作。所以我们可以从中悟出一个道理:就是我们自己在实现组件的时候,一个稳定的DOM结构是有助于我们的性能提升的。
组件间的比较(component diff)
查阅的网上的很多资料,发现写的都比较难懂,根据我自己的理解,其实最核心的策略还是看结构是否发生改变。React是基于组件构建应用的,对于组件间的比较所采用的策略也是非常简洁和高效的。
如果是同一个类型的组件,则按照原策略进行Virtual DOM比较。
如果不是同一类型的组件,则将其判断为dirty component,从而替换整个组价下的所有子节点。
如果是同一个类型的组件,有可能经过一轮Virtual DOM比较下来,并没有发生变化。如果我们能够提前确切知道这一点,那么就可以省下大量的diff运算时间。因此,React允许用户通过shouldComponentUpdate()来判断该组件是否需要进行diff算法分析。
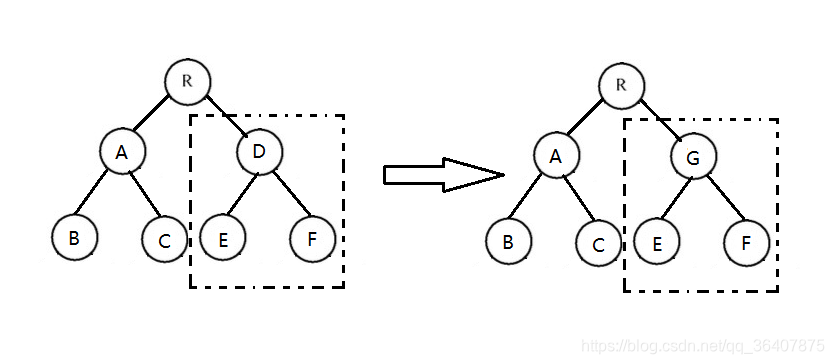
如上图所示,当组件D变为组件G时,哪怕这两个组件结构相似,一旦React判断D和G是不用类型的组件,就不会比较两者的结构,而是直接删除组件D,重新创建组件G及其子节点。也就是说,如果当两个组件是不同类型但结构相似时,其实进行diff算法分析会影响性能,但是毕竟不同类型的组件存在相似DOM树的情况在实际开发过程中很少出现,因此这种极端因素很难在实际开发过程中造成重大影响。
元素间的比较(element diff)
当节点处于同一层级的时候,react diff 提供了三种节点操作:插入、删除、移动。
| 操作 | 描述 |
| 插入 | 新节点不存在于老集合当中,即全新的节点,就会执行插入操作 |
| 移动 | 新节点在老集合中存在,并且只做了位置上的更新,就会复用之前的节点,做移动操作(依赖于Key) |
| 删除 | 新节点在老集合中存在,但节点做出了更改不能直接复用,做出删除操作 |
简单先看个例子:
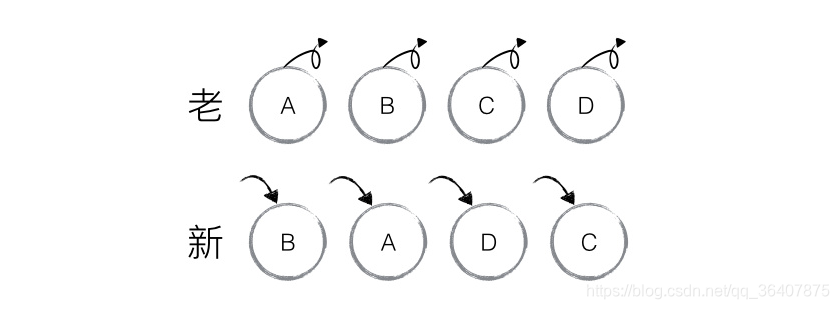
看上面的例子,得知,老集合包含节点 A、B、C、D,更新之后的新集合包括节点: B、A、D、C,然后diff算法对新老集合进行差异检测,发现B不等于A,然后就会创建B然后插入,并删除A节点,以此类推,创建并插入 A、D、C,然后移除B、C、D。
但是这些节点其实都没有发生改变,仅仅是位置上发生了变化,却要进行一大堆的繁琐低效的创建插入删除等操作,React说:“这样下去不行的,我们不如。。。”,于是React允许开发者对同一层级的同组子节点增加一个唯一的Key进行标识。
Key的作用
相信大部分刚开始接触react的时候,都看到过这样的警告:

这是由于我们在循环渲染列表时候(map)时候忘记标记key值报的警告,既然是警告,就说明即使没有key的情况下也不会影响程序执行的正确性.其实这个key的存在与否只会影响diff算法的复杂度,也就是说你不加上Key就会像上面的例子一样暴力渲染,加了Key之后,React就可以做出移动的操作了,看例子:
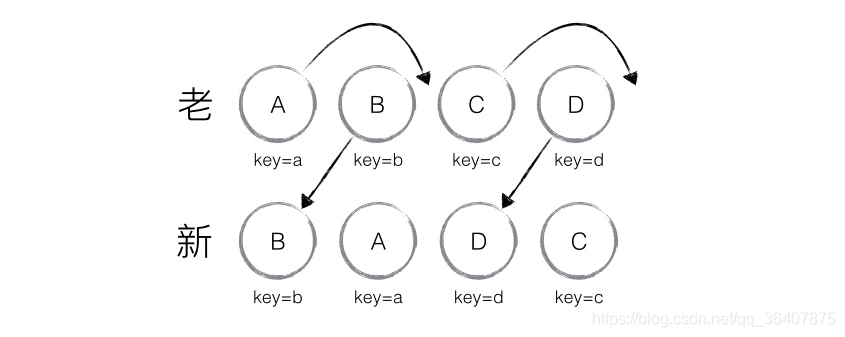
和上面的例子是一样的,只不过每个节点都加上了唯一的key值,通过这个Key值发现新老集合里面其实全部都是相同的元素,只不过位置发生了改变。因此就无需进行节点的创建、插入、删除等操作了,只需要将老集合当中节点的位置进行移动就可以了。React给出的diff结果为:B、D不做操作,A、C进行移动操作。react是如何判断谁该移动,谁该不动的呢?
react源码逻辑梳理
react会去循环整个新的集合:
①从新集合中取到B,然后去旧集合中判断是否存在相同的B,确认B存在后,再去判断是否要移动:
B在旧集合中的index = 1,有一个游标叫做lastindex。默认lastindex = 0,然后会把旧集合的index和游标作对比来判断是否需要移动,如果index < lastindex ,那么就做移动操作,在这里B的index = 1,不满足于 index < lastindex,所以就不做移动操作,然后游标lastindex更新,取(index, lastindex) 的较大值,这里就是lastindex = 1
②然后遍历到A,A在老集合中的index = 0,此时的游标lastindex = 1,满足index < lastindex,所以对A需要移动到对应的位置,此时lastindex = max(index, lastindex) = 1
③然后遍历到D,D在老集合中的index = 3,此时游标lastindex = 1,不满足index < lastindex,所以D保持不动。lastindex = max(index, lastindex) = 3
④然后遍历到C,C在老集合中的index = 2,此时游标lastindex = 3,满足 index < lastindex,所以C移动到对应位置。C之后没有节点了,diff就结束了
以上主要分析新老集合中节点相同但位置不同的情景,仅对节点进行位置移动的情况,如果新集合中有新加入的节点且老集合存在需要删除的节点,那么 React diff 又是如何对比运作的呢?
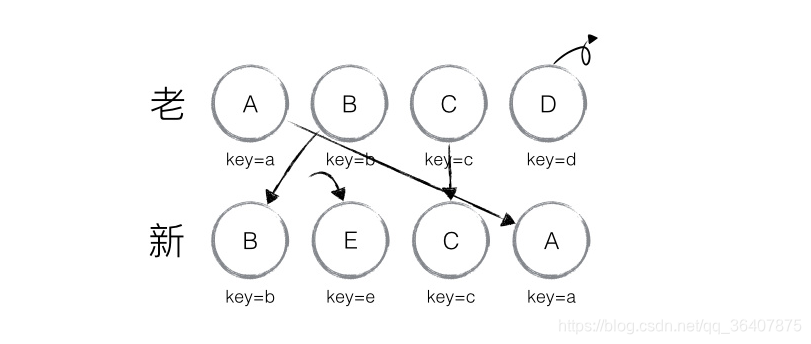
和第一种情景基本是一致的,react还是去循环整个新的集合:
①不赘述了,和上面的第一步是一样的,B不做移动,lastindex = 1
②新集合取得E,发现旧集合中不存在,则创建E并放在新集合对应的位置,lastindex = 1
③遍历到C,不满足index < lastindex,C不动,lastindex = 2
④遍历到A,满足index < lastindex,A移动到对应位置,lastindex = 2
⑤当完成新集合中所有节点 diff 时,最后还需要对老集合进行循环遍历,判断是否存在新集合中没有但老集合中仍存在的节点,发现存在这样的节点 D,因此删除节点 D,到此 diff 全部完成
但是 react diff也存在一些问题,和需要优化的地方,看下面的例子:
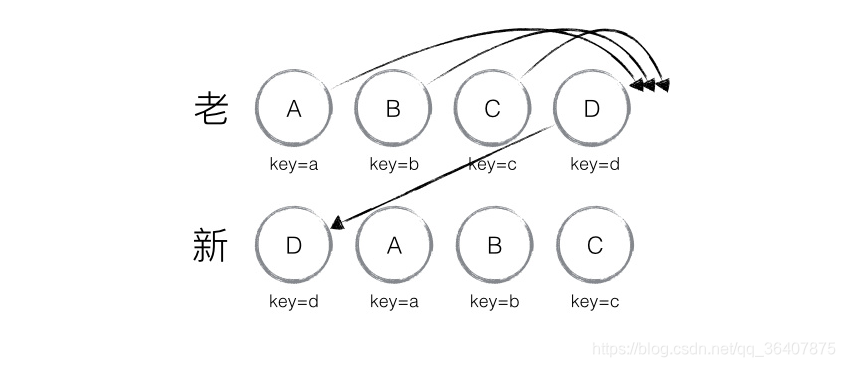
在上面的这个例子,A、B、C、D都没有变化,仅仅是D的位置发生了改变。看上面的图我们就知道react并没有把D的位置移动到头部,而是把 A、B、C分别移动到D的后面了,通过前面的两个例子,我们也大概知道,为什么会发生这样的情况了:
因为D节点在老集合里面的index 是最大的,使得A、B、C三个节点都会 index < lastindex,从而导致A、B、C都会去做移动操作。所以在开发过程中,尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,在一定程度上会影响 React 的渲染性能。
三句箴言
所以经过这么一分析react diff的三大策略,我们能够在开发中更加进一步的提高react的渲染效率。
箴言一:在开发组件时,保持稳定的 DOM 结构会有助于性能的提升;
箴言二:使用 shouldComponentUpdate()方法节省diff的开销
箴言三:在开发过程中,尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,在一定程度上会影响 React 的渲染性能。
为什么不推荐使用index作为Key
我们再写react的时候,当我们做map循环的时候,当我们没有一个唯一id来标识每一项item的时候,我们可能会选择使用index,官网不推荐我们使用index作为key,通过上面的知识背景,我们其实可以知道为什么使用index会导致一些问题:
看下面的一个场景吧:
data.map((item, index) => { return <li key={index}>{item}</li> })
上面这样写会存在很大的坑,比如看下面的例子:
class App extends Component{ constructor(props) { super(props) this.state = { list: [{id: 1,val: 'A'}, {id: 2, val: 'B'}, {id: 3, val: 'C'}] } } click() { this.state.list.reverse() this.setState({}) } render() { return ( <ul> { this.state.list.map((item, index) => { return ( <Li key={index} val={item.val}></Li> ) }) } <button onClick={this.click.bind(this)}>Reverse</button> </ul> ) } } class Li extends Component{ constructor(props) { super(props) } componentDidMount() { console.log('===mount===') } componentWillUpdate() { console.log('===update====') } render() { return ( <li> {this.props.val} <input type="text"></input> </li> ) } }
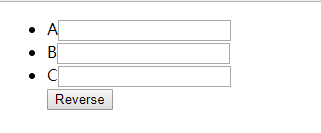
我们在三个输入框里面,依次输入1,2,3,点击Reverse按钮,按照我们的预期,这时候页面应该渲染成3,2,1,但是实际上,顺序依然还是1,2,3,再看控制台里面,确实是打印了===update===,证明数据确实是更新了的。那么为什么会发生这种事情,我们可以分析一下:
我们可以看下这个图就明白了:
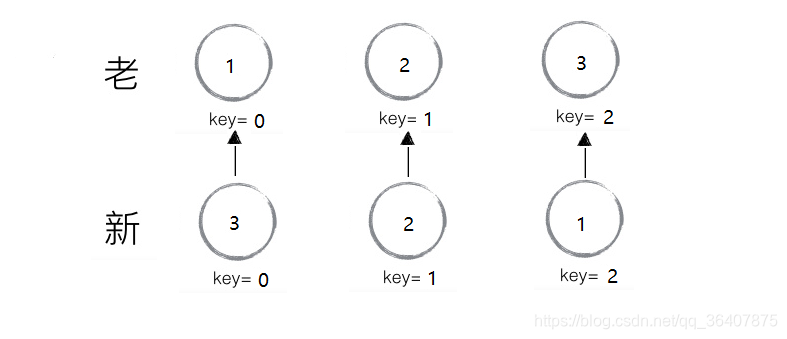
就像我们之前所说,react会通过key去老集合中找,是否有相同的元素,react发现新老key都是一致的,他会认为是同一个组件,所以input框内的值没有倒叙。我们只需要乖乖的把id作为key,就可以解决这个现象了。
还有存在一点隐藏的(性能问题):
当我们对数据有 删除、添加 等操作时。我们所遍历的index,就会有所变化,这种情况下diff算法对新老集合进行差异检测,发现key值有变化然后就会重新渲染,
我们只需要乖乖的把id(或者其他唯一标识)作为key,这样就只会对key值有变化的进行重绘,就可以解决这种性能问题了。