很久之前就得到了百度机器阅读理解关于数据集的这篇文章,今天才进行总结!。。。。
论文地址:https://arxiv.org/abs/1711.05073
自然语言处理是人工智能皇冠上的明珠,而机器阅读理解可以说是自然语言处理皇冠上的明珠。近些年机器阅读理解领域也越来越火热,百度所创造的DuReader这个数据集以及百度的两篇被ACL所收录的论文都充分证明了我们又向机器阅读理解领域迈进了一步。
这篇文章主要介绍了DuReader这个数据集,这个数据集是目前最大的关于中文的MRC数据集。
0摘要:DuReader是一个全新的大规模的开放领域的用于解决真实世界MRC的中文数据集。DuReader相比较以前的MRC数据集有以下优点:
(1)数据来源:问题以及文档来自百度搜索和百度知道,答案是人工生成
(2)问题类型:包括了很多问题的研究类型,特别是之前很少被研究的是非以及观点型的问题
(3)规模:每个问题都对应多个答案,数据集包含200k问题、1000k原文和420k答案,是目前最大的中文MRC数据集。
1Introduce:将现有的机器阅读理解数据集进行比较:

分析图1,对于完形填空风格的CNN&Dailymail和HLF-RC数据集,一个中文一个英文分别将复杂的机器阅读理解问题简化为对单词的简单预测(也就是完形填空)而CBT选自儿童读物(提供候选答案);RACE通过对中国学生英语阅读理解考试数据的选项选择来测试机器阅读理解能力而MCTest是只包含儿童能够理解的故事的集合,其总体形式类似于英语考试中的单项选择阅读理解题;基于问答的MRC数据集:NewsQA、SQuAD和TrivaQA将新闻文章、维基百科等数据转换为阅读理解题目,并定位答案出现的起始和结束位置。
这些数据集相比较DuReader存在的缺点:1、人工合成2、应用领域有限3、任务简单
2 Pilot study
之前的数据集的问题类要么是fact型要么是opinion型,对应于Entity,Description或者YesNo类型中的一种。
Entity问题:实体类问题:答案是一个单一实体或者是实体列表。比如:iPhone是哪天发布?
Description问题:描述类问题:答案通常是多个句子的总结。比如:消防车为什么是红的?
YesNo问题:是非类问题:其答案往往较简单,是或者否。比如:39.5度算高烧吗?
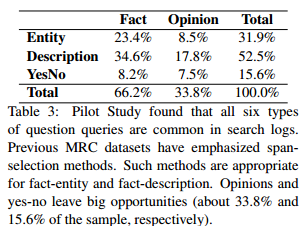
之前的MRC数据集主要侧重于对fact-entity和fact-description两类问题的研究。而DuReader对此做出了一些改变,形成了如下效果
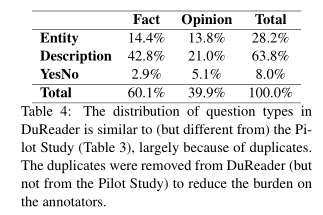
从两个维度划分,最终也形成了六种类型的问题。
3.DuReader数据集:
DuReader数据集的样本可用一个四维数组表示:{q, t, D, A},其中q表示问题,t表示问题类型,D表示文档集合,A表示答案集合。一半的样本来源于百度搜索引擎,一半来源于百度知道。下图展示了DuReader数据集的不同类型的定义。

DuReader相对具有挑战性:
(1)关于答案的数目
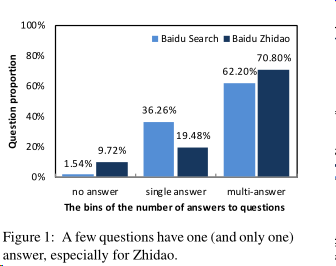
基于问题和文档来对答案进行标注,由于一个问题可能对应多个文档,所以一个问题可能有多个答案,但对于及其相似的答案则归为一个。其数据分布情况上图所示。在图中可以看出百度知道中含有多个答案的问题(70.80%)占比高于百度搜索引擎(62.20%),而含有一个答案的问题占比却低于百度搜索引擎,说明在问答社区中用户生成内容的主观性和多样性。同样对于没有答案的情况,百度知道(9.72%)明显高于百度搜索引擎(1.54%),对于没有答案的情况,对于研究也是一种挑战。
(2)编辑距离
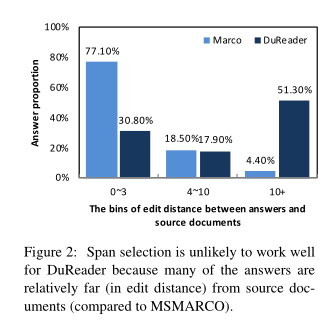
由于规模大且问题类型复杂,基于DuReader数据集的分析工作相比以往数据集都要难得多。百度通过计算人工答案和文档的最小编辑距离来判断回答问题的困难度。编辑距离越大,对文档的编辑修改就更多,回答问题的复杂度也就越高。对于答案直接来源于原文的数据集(如SQuAD),它们的编辑距离应该是0。上图展示了MS-MARCO和DuReader两个数据集答案与文档编辑距离分布情况。DuReader有超过一般的编辑距离都是大于10的,证明分析DuReader数据集好还是挺难的。
那么什么是编辑距离?(这里重点介绍一下)
编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一
个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。最小编辑距离通常作为一种相似度计算函数被用于多种实际应用中,详细如下: (特别的,对于中文自然语言
处理,一般以词为基本处理单元)
应用于:1、拼写纠错(Spell Correction)2、命名实体抽取(Named Entity Extraction)(以将候选文本串与词典中的每个实体名进行编辑距离计算,当发现文本中的某一字
符串的编辑距离小于给定阈值时,将其作为实体名候选词;获取实体名候选词后,根据所处上下文使用启发式规则或者分类的方法判定候选词是否的确为实体名)3、实体共指(Entity
Coreference)4、机器翻译(Machine Translation)(识别平行网页对:将网页的HTML标签抽取出来,连接成一个字符串,然后用最小编辑距离考察两个字符串的近似度 自动
评测:字符串核函数(String Kernel):最小编辑距离作为字符串之间的相似度计算函数,用作核函数,集成在SVM中使用。)
求解算法:求cafe和coffee的编辑距离cafe→caffe→coffe→coffee
| c | o | f | f | e | e | ||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
| c | 1 | 0 | 1 | 2 | 3 | 4 | 5 |
| a | 2 | 1 | 1 | 2 | 3 | 4 | 5 |
| f | 3 | 2 | 2 | 1 | 2 | 3 | 4 |
| e | 4 | 3 | 3 | 2 | 2 | 2 | 3 |
编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一
个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。最小编辑距离通常作为一种相似度计算函数被用于多种实际应用中,详细如下: (特别的,对于中文自然语言
处理,一般以词为基本处理单元)
应用于:1、拼写纠错(Spell Correction)2、命名实体抽取(Named Entity Extraction)(以将候选文本串与词典中的每个实体名进行编辑距离计算,当发现文本中的某一字
符串的编辑距离小于给定阈值时,将其作为实体名候选词;获取实体名候选词后,根据所处上下文使用启发式规则或者分类的方法判定候选词是否的确为实体名)3、实体共指(Entity
Coreference)4、机器翻译(Machine Translation)(识别平行网页对:将网页的HTML标签抽取出来,连接成一个字符串,然后用最小编辑距离考察两个字符串的近似度 自动
评测:字符串核函数(String Kernel):最小编辑距离作为字符串之间的相似度计算函数,用作核函数,集成在SVM中使用。)
求解算法:求cafe和coffee的编辑距离cafe→caffe→coffe→coffee
最终求的编辑距离也就是右下角的3。
表格的求解过程也就是先建立一个表,对两个字符串建立一个二维数组A[][],二维数组的A[0][0]存放数字0,两个字符串标记他们的长度str1是cafe,str2是coffee,k=1,然
后循环遍历,比较str1[k]是否等于str2[k],
while(i<=str1.size()&&i<=str2.size()){
if(str1[k]==str2[k])b=0;
else b=1;
A[i][j]=min{A[i-1][j-1]+b,A[i-1][j]+1,A[i][j-1]+1}
}
可以参考文章:
http://www.cnblogs.com/biyeymyhjob/archive/2012/09/28/2707343.html
关于python中如何使用编辑距离,以及一些文本相似度的计算方法,可以参考:
https://www.jb51.net/article/98449.htm
(3)文本长度
DuReader数据集问题的平均字数长度为4.8,答案的平均字数长度为69.6,文档的平均字数长度为396.0,是MS-MARCO的5倍。
在本节中,我们使用两个最先进的models来实现和评估基线系统。此外,我们的数据集中有丰富的注释,我们从不同的角度进行综合评估。
两个基线系统:Match-LSTM和BiDAF。
Match-LSTM是广泛应用的MRC模型,Match-LSTM(1)依次遍历文章找答案,动态地将注意力权重与文章的每个标记进行匹配(2)使用一个应答指针层来查找文章中的答案跨度。
BiDAF既使用了语境对问题的注意,又使用了问题对上下文的注意,(1)使用了两个注意从而突出了问题和上下文中的重要部分(2)利用注意流层融合所有有用的信息,从而得到每个位置的向量表示。
模型的相关参数:
- 词向量维度:300
- 隐藏层节点大小:150
- 优化算法:Adam
- 初始学习率:0.001
- batch size:32
针对一个问题可能对应了多个文档的这个问题,为了训练和测试的效率,在每个文档中选择具有代表意义的段落。
(1)在训练时,选择与答案相比较时可达到最高查全率的段落(即选择查全率最高的段落作为答案,也就是选择与人工生成的答案重叠度最高的段落)(2)在测试时,由于没有答案,则使用问题来计算查全率(选择与相应问题重叠度最大的)。接着在这写被选段落中训练得到答案的具体范围。
评价方法为:BLEU-4和Rouge-L。基于DuReader数据集模型实验结果如下图所示。
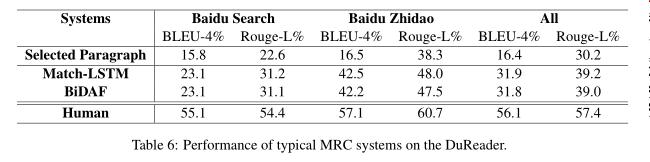
由上图可知,目前的阅读理解模型与选择段落基线相比有了显著的改善,验证了选择的两个模型的有效性。此外MRC上的两个经典系统在DuReader的表现可以看出,模型在百度搜索引擎的数据集的表现比百度知道的数据集要差,这表明,对于模型来说,理解开放域名比从问答中找到答案要难得多。
 每个文档中最相关的段落都是在测试阶段根据与相应问题的重叠度来选择的。为了分析段落选择的效果,并获得基线MRC模型的上限,我们重新评估了我们在黄金段落上的系统,如果每个黄金段落与文档中人工生成的答案重叠最大,则选择每个黄金段落。实验结果如表7所示。对比表6和表 7,我们可以看到黄金段落的使用可以显著提高整体性能。此外,直接使用黄金段可以获得很高的Rouge-L分数。这些结果表明,para graph选择是实际应用中需要解决的一个关键问题,而大多数MRC数据集都假设在一个小的段落或文章中找到答案。相比之下,DuReader提供了每个文档的完整正文,以促进在现实环境中的研究。
每个文档中最相关的段落都是在测试阶段根据与相应问题的重叠度来选择的。为了分析段落选择的效果,并获得基线MRC模型的上限,我们重新评估了我们在黄金段落上的系统,如果每个黄金段落与文档中人工生成的答案重叠最大,则选择每个黄金段落。实验结果如表7所示。对比表6和表 7,我们可以看到黄金段落的使用可以显著提高整体性能。此外,直接使用黄金段可以获得很高的Rouge-L分数。这些结果表明,para graph选择是实际应用中需要解决的一个关键问题,而大多数MRC数据集都假设在一个小的段落或文章中找到答案。相比之下,DuReader提供了每个文档的完整正文,以促进在现实环境中的研究。
为了更深入地了解数据集的特性,下面是基于不同问题类型模型实验结果所示。

由上图可知,模型在描述类问题普遍表现良好,但在是非问题上表现较差。分析可能是因为描述类问题答案往往是同一主题下的长文本,而是非问题的答案则较短(有时候只有Yes或No),且是非类问题的答案主观性强,答案之间往往是矛盾的。
BLEU和Rouge这两种评价指标对是非类问题并不友好,因为这两种评价指标不能很好的反应答案之间的一致性,比如两个完全相反的两个答案:“你可以做到”和“你不可以做到”,在BLEU和Rouge评价指标上,这两种矛盾的答案具有高一致性。
为了解决以上出现在是非类问题的问题,我们提出了一种新的意见感知系统(将 Match-LSTM最终的指针网络层用一个全连接层代替),该方法要求evaluated系统不仅要用自然语言输出答案,还要给它贴上意见标签(Yes、No或Depend)。最终只使用相同标签的答案来计算BLEU和Rouge评价指标。图9表示对YesNo类型问题添加和不添加标签模型的表现。

上图可以看出YesNo问题的标签感知模型明显要比高于不带标签感知的模型的性能。
4.小结
首先,我们的数据集中有一些以前没有被广泛研究过的问题,例如“是-否”问题和需要多文档MRC的意见问题。在意见识别、跨句推理、多文档摘要等方面需要新的方法。希望DuReader丰富的注释对研究这些潜在的方向有用。
其次,我们的基准系统采用了一个简单的段落选择策略,这导致系统性能相较黄金段落的性能大大降低。所以为实际的MRC问题设计一个更复杂的段落排名模型是必要的。
第三,最先进的模型将阅读理解作为一个跨领域的选择任务。然而,在DuReader中,人们实际上用他们自己的理解来总结答案。如何总结或产生答案值得更多的研究。
第四,作为数据集的第一个发布版本,它还远远不够完善,留下了很大的改进空间。例如,我们仅为“是-否”问题注释opin- ion标签,我们也将为描述和实体问题注释意见标签。
总结与启发:接下来的工作之后1、对现有机器阅读理解数据集进行比较总结;2、对百度基于DuReader开发的两个基线系统进行总结以及代码分析;3、阅读同期百度被ACL2018录用的两篇文章《Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification》《Joint Training of Candidate Extraction and Answer Selection in Reading Comprehension》