本篇论文是卡内基梅隆大学语言技术研究所2016年
- 摘要:
(1)引入一个端到端的系统,不再需要特征表示和数据预处理。
(2)该系统结合了LSTM,CNN和CRF
(3)该系统在两个语料上进行了评估,其中在Penn Treebank WSJ corpus上进行了POS词性标注任务,取得了97.55%的准确率,在CoNLL 2003 corpus上进行了NER命名实体识别,在F1上取得了91.21%。
- Introduction
(1)解决序列标注问题,例如NER和POS
(2)目前对于序列标注的研究:
传统方法:基于线性统计模型,例如HMM和CRF
存在问题:1、严重依赖手工特征 2、需要引入外部相关资源 3、耗费高、普适性差
近来方法:基于非线性神经网络模型,例如RNN-based Neural Network (RNNLSTMGRU) 、feed-forward neutral network、
存在问题:1、尽管使用一些分布式表示,例如词嵌入作为输入,但是仅仅是为了增加手工特征而不是替换它 2、如果完全依赖神经嵌入,则性能会大大降低
作者方法:1、为语言序列标注提出一个新颖的神经网络结构2、在两个经典的NLP基准数据集上进行了评估3、在这个端到端的系统上取得了很好的成果。

优点:1、真正的端到端,无需特定任务资源2、没有特征工程表示3、除了在无标签的语料上进行与训练的词嵌入没有其他数据预处理。
- Neural Network Architecture
step1:CNN获取Character-level 的词表示(另一个word-level级别的表示用已经训练好的glove-100d的词向量)

采用CNN的优点:CNN是一个非常有效的方式去抽取词的形态信息(例如词的前缀和后缀)。图中虚线表示字符嵌入在输入到CNN的时候采用了dropout层。
step2:将第一步CNN获得的字符级的嵌入和训练好的word embedding的字级别的嵌入联合输入到BLSTM,以获得过去和未来的上下文信息。


右边这个LSTM图更清晰,我们就一一来分解并说明一下LSTM内部结构:

图1
上面这个图1从左到右会有一个向量传输,左侧进入称为Ct-1,右侧输出Ct,第一部分乘号,也就是说Ct-1上一单元的输入在这里要进行一次乘法,乘一个系数,表示要忘记多少信息,之后进行一次加法线性运算,最后进行输出。

图2
上面图2就解释了刚刚图一所要乘的系数的来源,可以看出是将左侧的上一级输出ht-1和输入xt进行连接,也就是一个拼接的过程,在通过一个线性单元,也就是和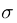 也就是sigmod函数之后生成一个0到1之间的数字,表达式如上图所示,这算一个“忘记门”,1表示完全记住,0表示完全忘记,也就是个比例问题,Wf和bf作为待定系数需要进行训练。
也就是sigmod函数之后生成一个0到1之间的数字,表达式如上图所示,这算一个“忘记门”,1表示完全记住,0表示完全忘记,也就是个比例问题,Wf和bf作为待定系数需要进行训练。
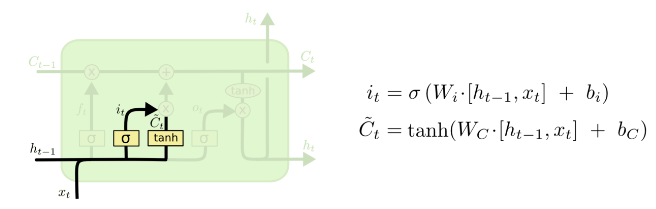
图3
上面图3是要计算图一所要进行加法运算的值,公式如图所示,tanh函数是把值映射到0到1之间。
图4
上面图4中图3显示的两部分进行乘运算,到这里进行加法运算,决定本次输出的Ct究竟采取多少本次输入的信息,采取多少上次遗留的信息。如果在语言模型中就是前一次主语到当前是否应该被遗忘,而当前新的主语是否应该替代之前的主语。

图5
上面图5显示该单元生成的ht一部分输出到同层下一单元,另一部分输出到下一层的单元上。这里看出来由图3显示的Ct在输出时经过tanh函数后又经历了一次“忘记门”Ot,进行相乘之后输出ht。在语言模型中,这种影响是可以影响前后词之间词形的相关性的,例如前面输入的是一个代词或者名词,后面跟随的动词会学到是否使用“单三”或者根据前面输入的名词的数量来决定动词的单复数。
上面的图都是采用的这篇文章中的,并且其中还涉及了一些变体,https://www.cnblogs.com/wangduo/p/6773601.html
RNN方向上的突破:LSTM以及LSTM变体(GRU等)、注意力、Grid LSTM、生成模型的 RNN。
step3:用CRF进行标注,联合解码输出最佳序列标注

CRF进行词性标注,考虑相邻词之间的词性标注,并且对于一个序列CRF模型(只考虑两个连续标签之间的相互作用),通过采用Viterbi算法,可以有效地解决训练和解码问题。Y(z)表示z可能的标注序列。 和
和 分别是权重矩阵和(y’和y的)对应偏差。
分别是权重矩阵和(y’和y的)对应偏差。
最后将BLSTM的输出作为CRF的输入,模型总结构具体如下:

图中在BLSTM的输入和输出均采用了dropout层,并且实验结果显示使用dropout层能够明显提高模型的性能。
- Network Training
我们使用Theano库, 单个模型的计算在GeForce GTX TITAN X GPU上运行。 使用本节中讨论的设置,模型培训需要大约12小时的POS标记和8小时的NER。
(1)Parameter Initialization
word embedding:glove 100-dim embeddings
Character Embeddings:30-dim
Weight Matrices and Bias Vectors:偏差除了在lstm的忘记门初始化为1,其余都初始化为0
(2)Optimization Algorithm
1)使用SGD(batchsize=10,momentum=0.9,η=0.01(POS-tagging)/η=0.015(NER), ,
, )
)
2)Early Stopping( The “best” parameters appear ataround 50 epochs)
3)Fine Tuning
4)Dropout Training(在输入到CNN之前以及BLSTM的输入和输出都应用了dropout,且dropout rate=0.5)
5)Tuning Hyper-Parameters
由于时间限制,不可在整个超参空间进行随机搜索,因此两个任务共享很多参数

在表中除了(初始学习率不同,其他均相同)
- Experiments
1)Data Sets数据集:作者在两个序列标注任务中评估了自己的模型:POS tagging and NER.
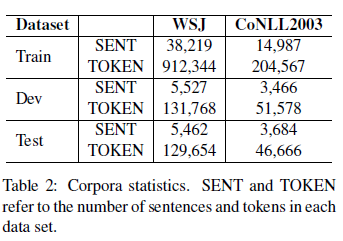
POS Tagging:WSJ(华尔街日报的PTB部分)
NER:CoNLL 2003
作者没有对语料做任何预处理,使得本文的模型是真正的端到端的模型。
2)Main Results
本实验中,下面表中的模型采用的都是GLOVE100-dim word embeddings以及Table1中相同的超参数。

从表中可以看出:BLSTM-CNN明显比BLSTM结果好,表明了在序列标注任中,characterlevel representations是很重要的。
添加在BLSTM-CNN上添加CRF之后,比原来的模型表现更好,表明联合解码对结果能够有很大的提高。
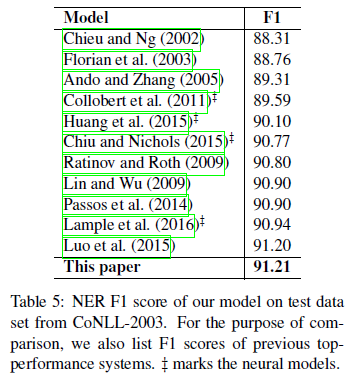
3)Comparison with Previous Work

4)Word Embeddings
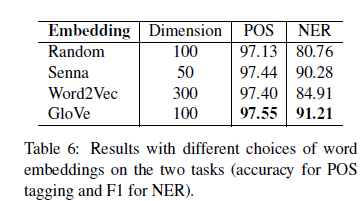
从图中可以看出,NER比POS-tagging更加依赖于与训练词向量;word2vec在NER上没有像其他两个词嵌入表现的好可能的原因是词表不匹配。
5)Effect of Dropout
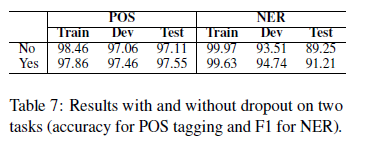
在两个任务上分别对比了未使用(No)和使用(Yes)了dropout的效果,结果表明在避免过拟合中dropou起到了很好的作用。
6)OOV Error Analysis
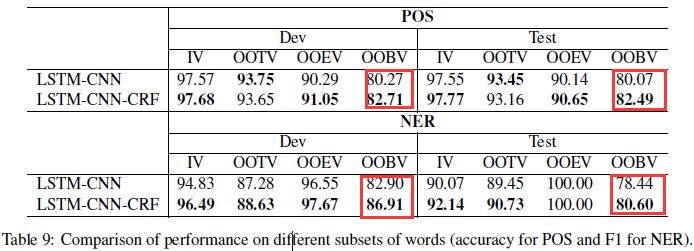
通过添加CRF进行联合解码,我们的模型在那些既没有出现在训练集中也没有出现在词嵌入表中的词的数据集上表现出更好的效果。
- Related Work
- Conclusion
本文提出了基于LSTM-CNNs-CRF的模型来处理序列标注问题,虽然LSTM、CNN、CRF已经是很成熟的模型,但是作者合理的将三者组合,形成了不需要大量的特定任务知识、特征工程以及预处理语料的完全的端到端的模型。并在POS和NER两个具体任务中验证取得了同等条件下的当前最好结果。
未来方向:
1)探索多任务学习(例如可以设计一个联合训练POS和NER标签的神经网络模型)
2)将该模型应用于其他领域(因为是端到端,所以也不会需要特定领域的知识)
参考(代码地址):
https://github.com/jayavardhanr/End-to-end-Sequence-Labeling-via-Bi-directional-LSTM-CNNs-CRF-Tutorial
https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF
glove 100-dimensional embeddings:http://nlp.stanford.edu/projects/glove/
Senna 50-dimensional embeddings:http://ronan.collobert.com/senna/
Google's Word2Vec 300-dimensional embeddings:https://code.google.com/archive/p/word2vec/