selenium 安装与 chromedriver安装
参考:https://www.cnblogs.com/technologylife/p/5829944.html
因为版本必须对应 :2019 Selenium Chrome版本与chromedriver兼容版本对照表
https://blog.csdn.net/yoyocat915/article/details/80580066
s1:直接使用pip安装
下载地址:http://npm.taobao.org/mirrors/chromedriver/
参照表:
注意 :chromedriver的版本要与你使用的chrome版本对应,对应关系如下:
下面是谷歌浏览器与chromedriver的版本对应关系,供参考:
ChromeDriver v2.46 (2019-02-01)----------Supports Chrome v71-73
-------以下为2018年兼容版本对照表,以上为2019年兼容版本对照表------
ChromeDriver v2.45 (2018-12-10)----------Supports Chrome v70-72
ChromeDriver v2.44 (2018-11-19)----------Supports Chrome v69-71
ChromeDriver v2.43 (2018-10-16)----------Supports Chrome v69-71
ChromeDriver v2.42 (2018-09-13)----------Supports Chrome v68-70
ChromeDriver v2.41 (2018-07-27)----------Supports Chrome v67-69
ChromeDriver v2.40 (2018-06-07)----------Supports Chrome v66-68
ChromeDriver v2.39 (2018-05-30)----------Supports Chrome v66-68
ChromeDriver v2.38 (2018-04-17)----------Supports Chrome v65-67
ChromeDriver v2.37 (2018-03-16)----------Supports Chrome v64-66
ChromeDriver v2.36 (2018-03-02)----------Supports Chrome v63-65
ChromeDriver v2.35 (2018-01-10)----------Supports Chrome v62-64
ChromeDriver v2.34 (2017-12-10)----------Supports Chrome v61-63
|
chromedriver版本 |
支持的Chrome版本 |
|
v2.33 |
v60-62 |
|
v2.32 |
v59-61 |
|
v2.31 |
v58-60 |
|
v2.30 |
v58-60 |
|
v2.29 |
v56-58 |
|
v2.28 |
v55-57 |
|
v2.27 |
v54-56 |
|
v2.26 |
v53-55 |
|
v2.25 |
v53-55 |
|
v2.24 |
v52-54 |
|
v2.23 |
v51-53 |
|
v2.22 |
v49-52 |
|
v2.21 |
v46-50 |
|
v2.20 |
v43-48 |
|
v2.19 |
v43-47 |
|
v2.18 |
v43-46 |
|
v2.17 |
v42-43 |
|
v2.13 |
v42-45 |
|
v2.15 |
v40-43 |
|
v2.14 |
v39-42 |
|
v2.13 |
v38-41 |
|
v2.12 |
v36-40 |
|
v2.11 |
v36-40 |
|
v2.10 |
v33-36 |
|
v2.9 |
v31-34 |
|
v2.8 |
v30-33 |
|
v2.7 |
v30-33 |
|
v2.6 |
v29-32 |
|
v2.5 |
v29-32 |
|
v2.4 |
v29-32 |
下载解压完之后添加到python/scripts目录下,因为这个目录是已经放在环境变量中的;当然也可以自己把解压路径添加到环境变量
from selenium import webdriver driver=webdriver.Chrome()
此时弹出下面:

![]()
然后
driver.get(“http://www.baidu.com”)
此时弹出:

driver.get("http://www.python.org")
弹出:

![]()
driver.page_source #获得网页源代码

![]()
有时候在爬虫的时候一直采用chrome不是很方便,因此可以采用一个无界面浏览器:phantomjs:
安装phantomjs
下载地址:http://phantomjs.org/download.html
解压:

![]()
进入bin目录:

![]()
将phantomjs.exe目录配置到环境变量中去:
打开电脑》》属性》》高级系统设置》》高级》》环境变量》》path中添加环境变量(记得路径之间加分号)
然后测试:

![]()
安装正确,ctrl+c退出;
接下来爬取网页:
from selenium import webdriver driver=webdriver.PhantomJS() driver.get("http://www.baidu.com")#爬取网页 driver.page_source#获取网页内容

![]()
安装lxml用来解析网页
pip install lxml
#或者另一个方式:
前提安装pip install wheel

![]()
安装beautifulsoup库:
pip install beautifulsoup4 from bs4 import BeautifulSoup
安装pyquery:网页解析库(比bs4更方便)
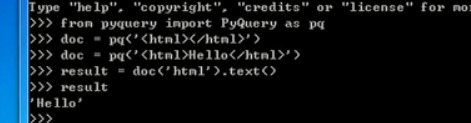
![]()
安装数据库
pip install pymysql
测试:
import pymysql conn=pymysql.connect(host='localhost',user='root',password='123456',port=3306,db='mysql') cursor=conn.cursor()#建立操纵对象 cursor.execute('select * from db')
输出:
2
cursor.fetchone()#取出里面的内容
输出:
('localhost', 'performance_schema', 'mysql.session', 'Y', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N', 'N')
安装pymongo
#键值形式存放,非关系型数据库,不需要见表,不需要关心表的结构,动态增加键名,完成数据存储
pip install pymongo#安装
测试:
import pymongo client=pymongo.MongoClient('localhost')#mongodb的连接对象 db=client['newtestdb']#声明一个数据库 db['table'].insert({'name':'Bob'})#声明表名,并插入一条数据
输出:
ObjectId('5c94e991fb8cf862d46be74c')
db['table'].find_one({'name':'Bob'})#利用函数将数据传送过来,查询数据
输出:
{'_id': ObjectId('5c94e991fb8cf862d46be74c'), 'name': 'Bob'}
安装Redis
Redis也是key-value形式存在,分布式爬虫,维护爬取序列的数据库
import redis r=redis.Redis('localhost',6379)#建立数据库对象 r.set('name','Bob')#添加键值
输出:
True
>>> r.get('name')#查询键值
b'Bob'
安装flask库
之后因为要用到web代理,进行代理的获取,代理的存储
pip install flask
安装django
web服务器框架,提供了后台管理,一些模板,引擎,接口,路由
pip install django
安装jupyter
pip install jupyter