写好测试用例的关键 /写好用例要关注的维度?
1. 覆盖用户的需求;
2. 从用户使用场景出发,考虑用户的各种正常和异常的使用场景;
3. 用例的颗粒大小要均匀。通常,一个测试用例对应一个场景;
4. 用例各个要素要齐全,步骤应该足够详细,容易被其它测试工程师读懂,并能顺利执行;
5. 做好用例评审,及时更新测试用例。
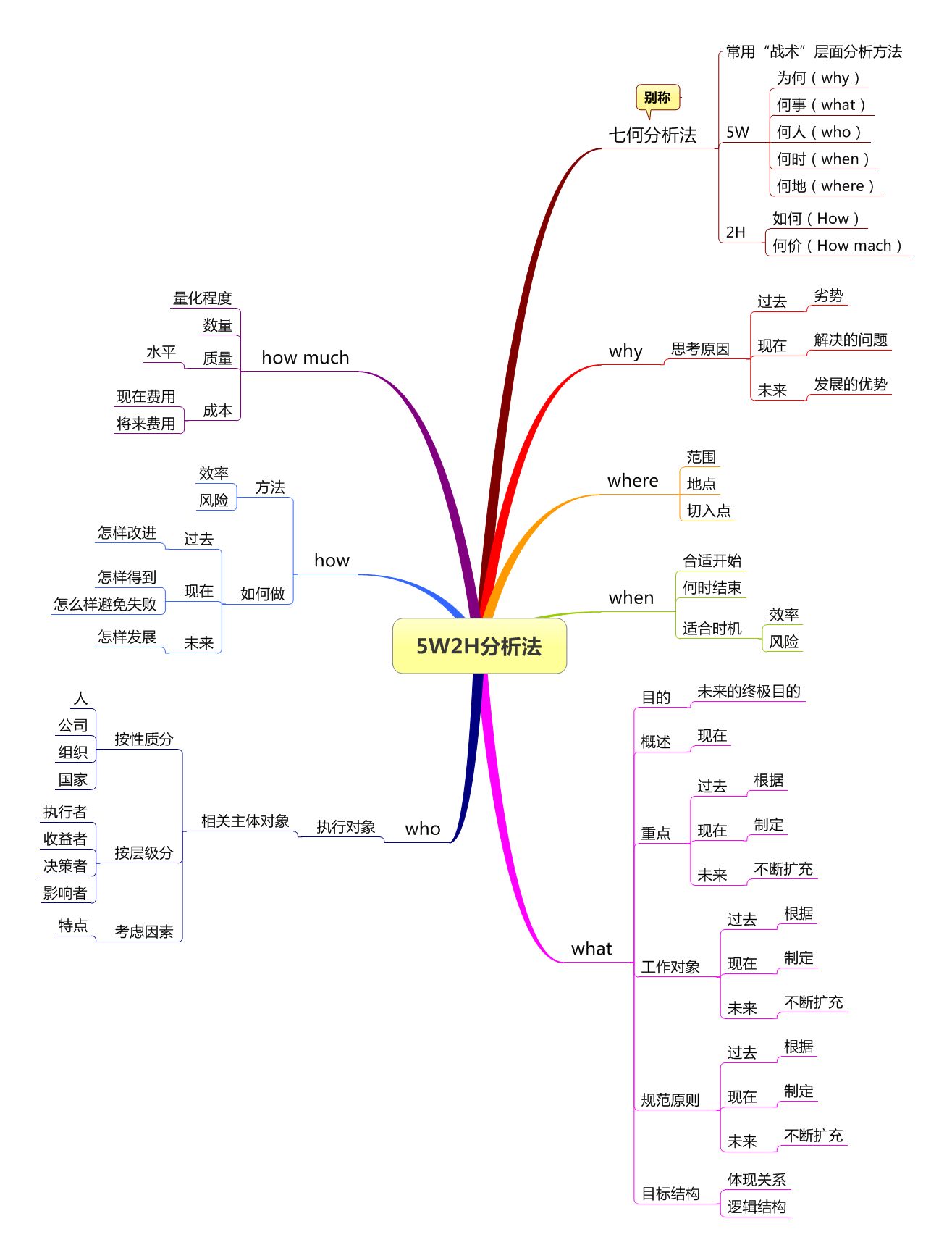
做好测试用例工作的关键是要充分考虑测试计划的实用性,坚持5W1H的原则,采用评审和更新机制以及测试策略。
要充分考虑测试计划的实用性,即测试计划与实际之间的接近程度和可操作性。
要坚持“5W1H”的原则,明确测试内容与过程。采用评审和更新机制,确保测试计划满足实际需求。
因为软件项目是一个渐进的过程,中间不可避免地会发生需求变化,为满足需求变化,测试计划也需要及时地进行变更。
测试策略要作为测试的重点进行描述。测试策略是测试计划中的重要组成部分,测试计划是从宏观上说明一个项目的测试需求、测试方法、测试人员安排等因素。
维度:功能、性能、安全、网络、界面、易用
UI 测试、功能、易用性、容错性:特殊字符测试性能、兼容性测试:IE8/9/10/11 谷歌浏览器 火狐浏览器、安全
软件测试的分类?
白盒测试
指的是把盒子盖打开,去研究里边源代码和程序结构(单元测试,ui/接口自动化测试)
黑盒测试
把被测试的软件看做一个黑盒子,我们不去关心盒子里边的结构是什么样子,只关心软件的输入数据和输出结果
功能测试
逻辑功能测试
测试应用是否符合逻辑,比如应该先注册账号之后,才能进行登录,登录之后才能看我的购物车
界面测试
窗口大小,按钮大小,点击按钮弹出什么样的提示框,是否有滚动条,下拉菜单是否有展示内容
易用测试
从软件使用的合理性和方便性等角度对软件系统进行检查,比如,软件窗口长宽比例是否合适,颜色色彩是否赏心悦目,字体大小是否合适
安装测试
安装磁盘空间不足,安装中断(关闭程序,关机,,)下次安装时是否继续上次的安装等。。。
兼容测试
硬件兼容性测试和软件兼容性测试(硬件兼容性:比如一款软件在pc机,笔记本,主机上是否兼容,软件兼容性测试:比如一款软件在window8和window10上是否兼容)性能测试
负载测试
让被测系统在其能够忍受的压力范围之内连续运行,来测试系统的稳定性。(测试载重)
压力测试
持续不断的给被测试的系统增加压力,直到被测试的系统压垮为止,用来测试系统所承受的最大压力。(测试强度)回归测试
修改了旧代码后,重新在新环境上进行测试以确认修改没有引入新的错误或导致其他代码产生错误。冒烟测试
对一个软件进行系统大规模的测试之前,先验证一下软件的基本功能是否实现,是否具备可测性。单元测试 是指对软件中的最小可测试单元进行检查和验证
集成测试 集成测试是单元测试的下一个阶段,是指将通过测试的单元模块组装成系统或者子系统,再进行测试,重点测试不同模块的接口部分。
系统测试 指的是将整个软件系统看做一个整体进行测试,包括对功能、性能,以及软件所运行的软硬件环境进行测试。
验收测试 以用户为主的测试,软件开发人员和质量保证人员参加
测试流程是什么?
立项(确定项目)--编写需求(需求人员)--需求评审(编写需求人员发起)--
开发编写概要和详细设计(编码并自测[开发环境])
测试:测试用例-测试用例评审(测试人员发起)--部署环境--冒烟测试(通过)--提交bug--回归测试(测试报告)--验收测试--上线
测试的原则是?
1.应当把“尽早和不断的测试” 作为开发者的座右铭
2.设计测试用例时,应该考虑到合法的输入和不合法的输入,以及各种边界条件,特殊情况下要制造极端状态和意外状态,比如网络异常终端,电源断电等情况
3.一定要注意测试中的错误集中发生现象,这和程序员的编程水平和习惯有很大关系
4.对测试错误结果一定要有一个确认的过程,一般有A测试出来结果,一定要有一个B来确认,严重的错误可以召开评审会进行讨论和分析
5.制定严格的测试计划,并把测试时间安排的尽量宽松,不要希望在极短的时间内我弄成一个高水平的测试
6.回归测试的关联性一定要引起充分的注意,修改一个错误而引起更多错误出现的现象并不少见
7.妥善保存一切测试过程文档,意义是不言而喻的,测试的重现性往往要靠测试文档
软件测试的黑盒白盒灰盒的区别?
白盒测试:对程序的内部结构与算法进行的测试
黑盒测试:不考虑程序的内部结果,只检查程序是否实现了需求的功能
灰盒测试:关注系统接口所实现的功能,是否和需求一致。
1.从测试目标和依据来说:黑盒面对的是产品设计,白盒针对的是程序功能的实现,灰盒针对兼而有之,既要考虑产品设计要求,又考虑到功能实现的效果。
2.从实现者而言:黑盒在意的是客户的角度,白盒测试针对的研发人员。
3.从测试模块颗粒度而言:白盒在意的是代码实现层面,而灰盒更加侧重模块之间,颗粒度大于白盒。
4.在版本层面上,白盒测试一般发生在debug版本,灰盒大多一般在release版本进行。
5.从测试效果而言,大量的bug在黑盒测试阶段测试出来,而白盒和灰盒测试的bug数目相对较少。
6.从耗时上来讲,在同等时间内,一般白盒和灰盒的耗时长,bug数量少,一般表现为时间产出比较低,很难大范围普及白盒。黑盒相对bug时间投入产出比较高。黑盒入门较为容易,其次是灰盒,白盒入门门槛教黑盒高很多。
任何工程产品(注意是任何工程产品)都可以使用以下两种方法之一进行测试。
黑盒测试 :已知产品的功能设计规格,可以进行测试证明每个实现了的功能是否符合要求。
白盒测试 :已知产品的内部工作过程,可以通过测试证明每种内部操作是否符合设计规格要求,所有内部成分是否以经过检查。黑盒测试
软件的黑盒测试意味着测试要在软件的接口处进行。这种方法是把测试对象看做一个黑盒子,测试人员完全不考虑程序内部的逻辑结构和内部特性,只依据程序的需求规格说明书,检查程序的功能是否符合它的功能说明。因此黑盒测试又叫功能测试或数据驱动测试。
黑盒测试主要是为了发现以下几类错误:
1、是否有不正确或遗漏的功能?
2、在 接口 上,输入是否能正确的接受?能否输出正确的结果?
3、是否有数据结构错误或外部信息(例如数据文件)访问错误?
4、性能上是否能够满足要求?
5、是否有初始化或终止性错误?具体的黑盒测试方法包括等价类划分、因果图、正交实验设计法、边值分析、判定表驱动法、功能测试等。
1、等价类划分 :
等价类划分是一种典型的黑盒测试方法,用这一方法设计测试用例可以不用考虑程序的内部结构,只以对程序的要求和说明,即需求规格说明书为依据,仔细分析和推敲说明书的各项需求,特别是功能需求,把说明中对输入的要求和输出的要求区别开来并加以分解。
2、边界值分析 :
软件测试常用的一个方法是把测试工作按同样的形式划分。对数据进行软件测试,就是检查用户输入的信息、返回结果以及中间计算结果是否正确。边界值分析(Boundary Value Analysis,BVA)是一种补充等价划分的测试用例设计技术,它不是选择等价类的任意元素,而是选择等价类边界的测试用例。
3、错误推测法:是基于经验和直觉推测程序中所有可能存在的各种错误, 从而有针对性的设计测试用例的方法. 错误推测方法的基本思想: 列举出程序中所有可能有的错误和容易发生错误的特殊情况,根据他们选择测试用例. 例如, 在单元测试时曾列出的许多在模块中常见的错误. 以前产品测试中曾经发现的错误等, 这些就是经验的总结. 还有, 输入数据和输出数据为0的情况. 输入表格为空格或输入表格只有一行. 这些都是容易发生错误的情况. 可选择这些情况下的例子作为测试用例.
4、因果图:考虑采用一种适合于描述对于多种条件的组合,相应产生多个动作的形式来考虑设计测试用例. 这就需要利用因果图(逻辑模型).
因果图方法最终生成的就是判定表. 它适合于检查程序输入条件的各种组合情况.
就是使用已经造好了的正交表格来安排试验并进行数据分析的一种方法,目的是用最少的测试用例达到最高的测试覆盖率白盒测试
软件的白盒测试是对软件的过程性细节做细致的检查。这种方法是把测试对象看做一个打开的盒子,它允许测试人员利用程序内部的逻辑结构及有关信息,设计或选择测试用例,对程序所有逻辑路径进行测试。通过在不同点检查程序状态,确定实际状态是否与预期的状态一致。因此白盒测试又称为结构测试或逻辑驱动测试。
白盒测试主要是想对程序模块进行如下检查:
1、对程序模块的所有独立的执行路径至少测试一遍。
2、对所有的逻辑判定,取“真”与取“假”的两种情况都能至少测一遍。
3、在循环的边界和运行的界限内执行循环体。
4、测试内部数据结构的有效性,等等。白盒测试方法包括:语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖、路径覆盖等。
以上事实说明,软件测试有一个致命的缺陷,即测试的不完全、不彻底性。由于任何程序只能进行少量(相对于穷举的巨大数量而言)的有限的测试,在未发现错误时,不能说明程序中没有错误。
灰盒测试
灰盒测试,是介于白盒测试与黑盒测试之间的,可以这样理解,灰盒测试关注输出对于输入的正确性,同时也关注内部表现,但这种关注不象白盒那样详细、完整,只是通过一些表征性的现象、事件、标志来判断内部的运行状态,有时候输出是正确的,但内部其实已经错误了,这种情况非常多,如果每次都通过白盒测试来操作,效率会很低,因此需要采取这样的一种灰盒的方法。
软件测试的开始条件和结束条件分别是什么?
需求的覆盖率、用例的执行率和缺陷的遗留率达到质量目标。
通常来说:需求覆盖率和用例执行率需要达到100%
致命/严重的缺陷需要当天解决,轻微/一般遗留率不得超过30%
怎么保证百分之百覆盖用户需求?
项目开始前,我们会先熟悉需求,画好流程图,保证整个流程都覆盖全面,小组之间每个人都要根据各自的流程图,各个功能点有哪些限制条件,来讲解一下自己对测试点的理解,防止之后编写测试用例时出现遗漏;
用例编写完之后,再进行用例的评审,看看测试点有没有用遗漏,对需求理解有没有错误,测试场景是否覆盖完全。
常见的测试风险有哪些?
进度风险
质量风险
需求变更
常见的测试方法有哪些?
等价类划分。
多用于输入框:注册/登录
边界值
多和等价类划分结合使用,有边界限制的:注册的密码长度(掌握上点和离点的取值)
场景法
从基本流开始,再将基本流和备选流结合起来,可以确定用例场景
正交表
用于多个下拉框之间的组合,可以通过正交助手生成测试用例
错误推测
错误猜测法是测试经验丰富的人喜欢使用的一种测试用例设计方法。一般这种方法是基于经验和直觉推测程序中可能发送的各种错误,有针对性地设计。只能作为一种补充
因果图
因果图法比较适合输条件比较多的情况,测试所有的输入条件的排列组合。所谓的原因就是输入,所谓的结果就是输出
产品上线后发现bug怎么办?
开发不认为是bug的时候怎么办?
1.先跟开发沟通,确认系统的实际结果是不是和需求有不一致的地方;有些地方可能需求没提及,但是用户体检不好,我们也可以认为是bug
2.如果开发以不影响用户使用为理由,拒绝修改,我们可以和产品经理,测试经理等人员进行讨论,确定是否要修改,如果大家都一致认为不用改,就不改
如何跟踪bug?
当发现缺陷后,我们要在禅道上提交问题单给开发,并每隔一段时间(间隔一个小时,或两个小时都可以)去检查缺陷是否被处理,如果没及时处理,就要提示开发,让开发及时修复问题,问题修复后,要及时进行回归测试。
Bug的关注点有哪些?
缺陷标题,严重级别,问题所属模块,复现步骤,预期结果,实际结果,有关的日志和截图。
你发现一个bug后怎么处理?
发现bug后,我们会先自己定位一下,比如,抓个包,看看是前端的问题,还是后端的问题,检查下数据库的数据是不是正确的,尽量把问题发生的原因或者产生的日志找出来,方便开发定位问题,
然后就提单给开发,然后开发做出相应的处理,开发修复完后就进行回归测试,回归测试通过后就关闭这个bug,没有通过就继续给回开发修复。
如果遇到开发认为这个不是bug的话,那么我们就要和开发沟通,然后我们要坚持自己的立场,通过讨论后一致认为是bug就给开发修复,不是就关闭这个bug。
如果开发和我们意见一直不一致,那么就要将问题升级,召集开发经理和测试经理一起讨论,再做决定。
Bug的状态有哪些?
致命,严重,一般,轻微
1、New(新的):bug提交到缺陷库中会自动的被设置成New状态
2、Assigned(已指派):当一个bug被认为New之后,将其分配开发人员,开发人员将确认这是否是一个bug,如果是,开发组的负责人就将这个bug指定给某位开发人员处理,并将bug的状态设定为“Assigned”
3、Open(已打开):开发人员开始处理bug时,他将这个bug的状态设置为“Open”,表示开发人员正在处理这个“bug”
4、Fixed(已修复):当开发人员进行处理(并认为已经解决)之后,他(她)就可以将这个bug的状态设置为“Fixed”并将其提交给开发组的负责人,然后开发组的负责人将这个bug返还给测试组
5、Rejected(被拒绝):测试组的负责人接到上述bug的时候,如果他(她)发现这是产品说明书中定义的正常行为或者经过与开发人员的讨论之后认为这并不能算作bug的时候,开发组负责人就将这个bug的状态设置为“Rejected”
6、Postponed(延期):有些时候,对于一些特殊的bug的测试需要搁置一段时间,事实上有很多原因可能导致这种情况的发生,比如无效的测试数据,一些特殊的无效的功能等等,在这种情况下,bug的状态就被设置为“Postponed”
7、Closed(已关闭):测试人员经过再次测试后确认bug已经被解决,将bug的状态设置为“Closed”
8、Reopen(再次打开):如经过再次测试发现bug仍然存在,测试人员将bug再次开发组,将bug的状态设置为“Reopen”
用linux命令把a.log文件中的包含 Error 字符串的内容提取出来,追加到b.log文件中?
cat a.log |grep Error>>b.log
如果简单的文字就用
echo "xxx" >> /foo/bar
如果文字比较多也可以用
cat file.ext >> /foo/bar
或者也可以用某个程序的输出
./prog >> /foo/bar
>>就是在结尾追加
用linux命令从远程服务器(192.168.2.1)上把/root/log拷贝到本地的/opt目录下?
scp -r root@192.168.2.1:/root/log /opt
1、从服务器上下载文件
scp username@servername:/path/filename /var/www/local_dir(本地目录)例如scp root@192.168.0.101:/var/www/test.txt 把192.168.0.101上的/var/www/test.txt 的文件下载到/var/www/local_dir(本地目录)
2、上传本地文件到服务器
scp /path/filename username@servername:/path例如scp /var/www/test.php root@192.168.0.101:/var/www/ 把本机/var/www/目录下的test.php文件上传到192.168.0.101这台服务器上的/var/www/目录中
3、从服务器下载整个目录
scp -r username@servername:/var/www/remote_dir/(远程目录) /var/www/local_dir(本地目录)例如:scp -r root@192.168.0.101:/var/www/test /var/www/
4、上传目录到服务器
scp -r local_dir username@servername:remote_dir
例如:scp -r test root@192.168.0.101:/var/www/ 把当前目录下的test目录上传到服务器的/var/www/ 目录
用linux命令在当前文件夹中查找a.log?
find / -name 'a.log'
查看可用内存,磁盘大小和CPU使用率的命令?
查看内存:free
free -m
以MB为单位显示内存使用情况
free -h
以GB为单位显示内存使用情况
free -t
以总和的形式查询内存的使用信息
free -s 5
周期性的查询内存使用信息
每5秒执行一次命令
解释:
Mem:内存的使用情况总览表(物理内存)
Swap:虚拟内存。即可以把数据存放在硬盘上的数据
shared:共享内存,即和普通用户共享的物理内存值
buffers:用于存放要输出到disk(块设备)的数据的
cached:存放从disk上读出的数据
total:机器总的物理内存
used:用掉的内存
free:空闲的物理内存
注:物理内存(total)=系统看到的用掉的内存(used)+系统看到空闲的内存(free)
查看某个pid的物理内存使用情况
cat /proc/PID/status | grep VmRSS
查看本机所有进程的内存占比之和
cat mem_per.sh
磁盘大小:df -h
df -Th
查看分区、挂载情况
lsblk
查看磁盘情况
top后键入P看一下谁占用最大
fdisk -l
查看详细的硬盘分区情况
CPU使用率: top
top后键入P看一下谁占用最大
top -d 5
周期性的查询CPU使用信息
每5秒刷新一次
测试环境怎么搭建的?
搭建环境前,开发都会给到我们一份系统发布手册,我们会根据这个手册来搭建。
比如,我这个xx系统,是搭建在Linux系统下的,web服务器用的是Tomcat8,MySQL版本是5.7,程序是JAVA编写的,首先我们向开发拿到编译好的安装包,然后用xshell(或CRT)远程连接上Linux系统,把tomcat服务器停掉,把程序包放到webapps目录下,
然后再启动tomcat服务器就可以了。
在需求文档不太详细的情况下,如何开展一个web端项目测试?
1.首先,把需求文档中有异议的部分标识出来,再找产品和开发一起讨论,把需求明确下来;
2.提取测试点,然后再叫上产品和开发一起对测试点进行讨论,看有没有遗漏,是不是合理的,
3.然后再编写测试用例,再评审,评审通过后,再进行后续的测试。
项目中的订单怎么测试?(主要测试订单的状态变化)?
我们系统的订单生成的流程是这样子的,用户下单后,系统会在用户端和卖家端生成一个待付款的订单,同时在数据库也会生成一个待付款的订单;当
用户付款之后,用户端显示待发货状态,卖家端显示已付款待发货状态,订单在数据库的状态为待发货,产品相应的库存量会减少,用户的账户金额减少相应的金额;
当卖家发货后,用户端和卖家端的订单状态都显示为配送中,数据库中的订单状态也同时发生变化;
当用户确认收货后,订单状态会显示为已完成,待评价状态,数据库中的订单状态也同时发生变化,买家支付的款项会打入到卖家的账户;
当用户评论完后,订单状态显示为已结束,数据库中的订单状态也同时发生变化。
这是一个正常的流程,我们测试的时候,要优先把这个流程测试通过。
然后再考虑用户的其他使用场景,比如:
1. 用户下单后,取消订单;
2. 下单后,一直不付款,检查订单超时不付款的场景下,会不会自动取消订单;
3. 在订单快超时时,付款;
4. 下单后,在不同的终端登录,一端取消订单,同时一端对该订单进行付款;
5. 弱网状态下,多次点击提交订单按钮,检查是否会生成多个订单;
6. 用户付款后,申请退款,买家端的订单状态为退款申请中,卖家端显示为退款审核;申请退款通过后,订单状态为已关闭状态,买家收到退还的金额;卖家拒绝退款,订单状态为待发货状态;卖家超时不处理退款申请,自动退款,订单自动设置为已退款状态,买家收到退还的金额;
7. 当卖家发货后,买家申请退款,买家端的订单状态为退款申请中,卖家端显示为退款审核;申请退款通过后,订单状态为已关闭状态,买家收到退还的金额;卖家拒绝退款,订单状态为待发货状态;卖家超时不处理退款申请,自动退款,订单自动设置为已退款状态,买家收到退还的金额;
8. 买家收货后,买家申请退款/退货,买家端的订单状态为退款申请中,卖家端显示为退款审核;申请退款通过后,订单状态为已关闭状态,买家收到退还的金额;卖家拒绝款/退货,订单状态为已确认收货状态;卖家超时不处理退款/退货申请,自动退款,订单自动设置为已退款状态,买家收到退还的金额;
9. 买家长时间不确认收货,系统自动确认收货,系统自动设为好评,订单状态为已结束,卖家收到买家的货款;
10. 收货后,超时不评论,系统自动设为好评,订单状态为已结束。
这些是功能测试的场景,每个场景,我们都要检查数据库对应订单的数据变化。
- 用户体验:
- 订单界面是否整洁,清晰,文字大小是否适中,订单编号是否能复制;
- 下单,取消订单,申请退款等功能是否有响应的提示,提示是否合理;
- 超时时长是否有倒计时提示;
- 只对订单的部分商品进行发货,订单里的商品发货状态是否分开展示;
- 是否支持Enter,tab等快捷键。
- 安全性:
- 使用Fiddler,检查是否能拦截篡改修改订单的信息。
- 兼容性:
- web端,在不同的浏览器,比如:谷歌,IE,火狐,360上测试;
- app端,在主流的不同的机型,不同的分辨率,不同的操作系统的手机上进行测试,比如:xxx;
- 性能:
- 多用户并发下单;
- 提交订单,取消订单,申请退款的响应时间。
- 可靠性:
- 多用户长时间运行提交订单功能。
项目中的支付模块怎么测试?
- 从功能方面考虑:
- 正常完成支付的流程;
- 支付中断后继续支付的流程;
- 支付中断后结束支付的流程;
- 单订单支付的流程;
- 多订单合并支付的流程;
- 余额不足;金额的最小值 :如0.01;金额为0;金额为负数
- 未绑定银行卡;
- 密码错误;
- 密码错误次数过多;
- 找人代付;
- 弱网状态下,连续点击支付功能功能,会不会支付多次;
- 有优惠券、折扣、促销价进行结算是否正确;
- 不同终端上支付:包括PC端的支付、笔记本电脑的支付、平板电脑的支付、手机端的支付等;
- 不同的支付方式:银行卡网银支付、支付宝支付、微信支付等;
- 支付失败后,再次支付。
- 从性能方面考虑:
- 多个用户并发支付能否成功;
- 支付的响应时间;
- 从安全性方面考虑
- 使用Fiddler拦截订单信息,并修改订单金额,或者修改订单号,(下两个订单A,B,付款时拦截订单B,并把订单B的订单号改为A订单的订单号)无法完成支付;
- 从用户体验方面考虑
- 是否支持快捷键功能;
- 点击付款按钮,是否有提示;
- 取消付款,是否有提示;
- UI界面是否整洁;
- 输入框是否对齐,大小是否适中等。
- 兼容性
- BS架构:不同浏览器测试。
- APP:不同类型,不同分辨率,不同操作系统的手机上测试
项目中的登录怎么测试?
功能方面的测试:
- 输入正确的用户名和密码,点击提交按钮,验证是否能正确登录,能否能跳转到正确的页面
- 输入错误的用户名, 验证登录失败,并且提示相应的错误信息
- 输入错误的密码, 验证登录失败,并且提示相应的错误信息
- 用户名为空, 验证登录失败,并且提示相应的错误信息
- 密码为空, 验证登录失败,并且提示相应的错误信息
- 用户名和密码都为空,点击登陆
- 用户名和密码前后有空格的处理
性能方面的测试
- 打开登录页面,需要多长时间
- 输入正确的用户名和密码后,登录成功跳转到新页面,需要多长时间
安全性方面的测试
- 密码是否在前端加密,在网络传输的过程中是否加密
- 用户名和密码的输入框,能否防止SQL注入攻击
- 用户名和密码的输入框,能否防止XSS攻击
- 错误登陆的次数限制(防止暴力破解)
- 是否支持多用户在同一机器上登录
- 一个用户在不同终端上登陆
- 用户异地登陆
用户体验测试:
- 页面布局是否合理,输入框和按钮是否对齐
- 输入框的大小和按钮的长度,高度是否合理
- 是否可以全用键盘操作,是否有快捷键
- 输入用户名,密码后按回车,是否可以登陆
- 牵扯到验证码的,还要考虑文字是否扭曲过度导致辨认难度大,考虑颜色(色盲使用者),刷新或换一个按钮是否好用
兼容性测试
- BS架构:不同浏览器测试,比如:IE,火狐,谷歌,360这些。
- APP:在主流的不同类型,不同分辨率,不同操作系统的手机上测试,华为,vivo,oppo等
Python中的模块有哪些?
pyMsql,HtmlTestRunner,pytest,requests,selenium
Python中的2.0和3.0有什么区别?
用自己熟悉的语言编写一个9*9乘法表?
用自己熟悉的语言编写一个冒泡排序?
用自己熟悉的语言编写一个2分排序?
显示等待 隐式等待 强制等待的区别以及对应的代码是?
1、selenium的显示等待
原理:显示等待,就是明确的要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,那么就跳出Exception
(简而言之,就是直到元素出现才去操作,如果超时则报异常)2、selenium的隐式等待
原理:隐式等待,就是在创建driver时,为浏览器对象创建一个等待时间,这个方法是得不到某个元素就等待一段时间,直到拿到某个元素为止。
注意:在使用隐式等待的时候,实际上浏览器会在你自己设定的时间内部不断的刷新页面去寻找我们需要的元素
3、强制等待
使当前线程进入等待,time.sleep();这种等待属于死等,很容易让线程挂掉,使程序抛异常,所以要慎用此方法
Time.sleep(1)
常见的定位方式有哪些?Web端和app端?
TouchAction(driver).press()

Adb查看当前运行的APP的包名和打开的Activity?
adb shell dumpsys window | findstr mCurrentFocus
Adb先监控日志中关于START关键字的日志?
Adb 将 安卓/data目录下a.txt文件 下载到D: est中?
adb pull 安卓/data/a.txt D: est
Charles中如何进行请求断点替换?
1. 首先点击选中的接口,右键选中Breakpoints(断点)
2. 点击Proxy(代理),点击Breakpoint Settings(设置断点)弹出弹窗
3. 把所对应的url复制粘贴到Host里,点击任意处,自动填充,把Query里的数据替换成*,选中request,点击ok
4. 重新刷新页面,此时你的断言会弹出两条接口,点击Edit Request,修改参数值,点击完成(Execure)
5. 此时查看网页,下面的值就修改成功了
6. 此时退出断点的话,点击Abort,再点击任务栏的红色图案,表示取消断点,重新加载页面就恢复正常了
Charles中如何进行响应断点替换?
1. 首先点击选中的接口,右键选中Breakpoints(断点)
2. 点击Proxy(代理),点击Breakpoint Settings(设置断点)弹出弹窗
3. 把所对应的url复制粘贴到Host里,点击任意处,自动填充,把Query里的数据替换成*,选中response,点击ok
4. 重新刷新页面,此时你的断言会弹出两条接口,点击Edit Response,修改参数值,点击完成(Execure)
5.此时查看网页,下面的值就修改成功了
6. 此时退出断点的话,点击Abort,再点击任务栏的红色图案,表示取消断点,重新加载页面就恢复正常了
Charles中如何进行对app端抓包?
1. 首先在代理里把Windows Proxy关掉
2. 点击Help,点击SSL Proxying,再点击下载最长的那个下载证书
3 .点击Proxy,点击代理设置(Proxy Setting),查看端口号
4. 打开手机WLAN长摁,手动输入代理,把本地ip和代理号输入保存
5. 浏览器下载证书,手机随意点开软件,就会有接口显示出来
Charles中如何进行弱网测试?
1. 请求网页,点击proxy(代理),选中Throttle Setting(节流阀调整)
2. 点击Enable Throttling(使用节流阀)进行调整里面的数据
3. 最后点击ok保存
4. 如果想退出就点菜单栏的小乌龟,取消慢网测试
Charles中如何模拟404/403?
Tools----black list-----Drop connection(404)/return 403 response(403) 添加要进行测试的接口路径-------点击ok
1.点击tools(工具)选择blacklist(黑名单)
2.允许启动黑名单功能 选择接口返回值的形式 添加接口地址并保存
3.选中需要返回404/403的接口 点击ok再次请求
Jmeter中如何进行对数据库压测?
1. 添加-配置元件-jdbc Connection Configuration 填写数据库信息,database Url中有地址,端口号,数据库名称,协调时间的和可以多条执行sql的路径
还有jdbc驱动和数据库账号密码,并且创建连接池的变量名2. 右键线程组-取样器-添加-jdbc request 填写JDBC连接池中声明的池的变量名
3. jdbc request中写sql语句
4. 线程组增加次数点击运行进行压测
Jmeter中如何实现参数化关联?
1. 把测试的数据写到txt文件中
2. 右键线程组-添加-配置元件--csv数据文件设置
3. 选择txt文件路径并填写作为全局变量的变量名称,多条数据用逗号隔开
4. 添加一个http请求
5. 请求的参数就用全局变量${变量名}替换进行取值
1. 选项里点击函数助手对话框
2. 黏贴测试txt文件的地址
3. 填写提取的第几个参数(0是第一个,1是第二个。。)
4. 点击生成
5. 拷贝函数字符串,黏贴到http请求的参数栏中
Ant+jmeter+jenkins 如何实现的(关键步骤)?
tps和qps的区别?
tps:每秒事务数
qps: 每秒查询率,是一台服务器每秒能够响应的查询次数(数据库中的每秒执行查询sql的次数)
Cookie和session的区别?
1. cookie存储在客户端/session存储在服务器端
2. cookie和session有ID映射,通过ID映射可以管理不同用户的session对象
3. cookie数据存储不如session安全
4. session存储数据,加大服务器负载/考虑性能方面减轻服务器压力使用cookie
cookie与session的联系:
当服务器端生成一个session时就会向客户端发送一个cookie保存在客户端
这个cookie保存的是session的sessionId
这样才能保证客户端发起请求后,
客户端已经登录的用户能够与服务器端成千上万的session中准确匹配到已经保存了该用户信息的session,
同时也能够确保不同页面之间传值时的正确匹配。
你知道的请求方式有哪些以及区别?
一.请求方式
所有的请求都可以给服务器传递内容,也可以从服务器获取内容。
GET:从服务器获取数据(给的少拿的多)
POST:向服务器推送数据(给的多拿的少)
DELETE:删除服务器的一些内容
PUT:向服务器存放一些内容
HEAD:只请求页面的头部
TRACE(或OPTIONS):发送一个探测性请求,如果返回了信息说明建立了连接
二.区别
1.传递给服务器信息的方式不一样
GET:基于URL地址“问号传参”,POST基于“请求主体”把信息传给服务器。(GET一般用于拿,POST一般用于推送内容)
2.GET不安全,POST相对安全(记住是相对)
因为GET是基于“问号传参”把信息传递给服务器,容易被骇客进行URL劫持。POST是基于请求主体传递的,相对来说不好被劫持。所以涉及到登录注册等信息应使用POST。
3.GET会产生不可控制的缓存,POST不会
不可控:这是浏览器自主记忆的缓存,我们无法基于js控制,项目中会将去掉这个缓存。
GET请求产生缓存的原因:连续多次向相同的地址(传递的参数也是一致的)发送请求,浏览器会把之前获取的数据从缓存中拿到,导致无法从服务器获取最新的数据(POST不会)。
1. GET使用URL或Cookie传参。而POST将数据放在BODY中
2. GET的URL会有长度上的限制,2kb,则POST的数据则可以非常大
3. POST比GET安全,因为数据在地址栏上不可见
4. 一般get请求用来获取数据,post请求用来发送数据
举例说明下你的自动化如何做的?
你知道的测试框架有哪些都怎么用的?
unittest
自动化中如何切换不同的浏览器和iframe的以及对应的代码?
切换 iframe
1. 切换方式一:通过主网页源代码中frame或iframe标记的元素id或name属性值来切换
driver.switch_to.frame("frame或iframe标记的元素id或name属性值")
2. 切换方式二:使用frame或iframe标记的元素在整个主网页里的索引号来切换。
driver.switch_to.frame(索引号)
注意:索引号是代表当前frame或iframe标记的元素是主网页里的第几个的整数,从0开始编号。
3. 切换方式三:使用其他方式来定位到frame或iframe标记的元素,然后把定位到的元素对象作为切换frame时的参数。其他方式包括class name或xpath或css selector定位等任何定位方法
变量=driver.find_element(By.XXX,"xxxx")
driver.switch_to.frame(变量)
4. 如果已经切换进入某个frame内,从该frame回到默认主网页,下面的语法可以切换:driver.switch_to.default_content()
# 好比从包间1出来,回到进门处---就是指主网页
如果已经回到默认主网页,就可以切换到其他frame里。如果在一个子网页里,不能切换到同级的其他子网页里,否则抛出NoSuchFrameException
切换 窗口
获得此属性值可以获得当前窗口的句柄
driver.current_window_handle
获得此属性值可以获得所有由WebDriver本次运行所启动的窗口的句柄,是以list类型存储的
driver.window_handles
采用排除法切换到新窗口的算法---适用于一共只有2个窗口的情况:
1. 获得当前窗口句柄
2. 获得所有窗口句柄
3. 循环遍历所有窗口句柄
4. 判断如果不等于第(1)步骤的当前窗口句柄
5. 就用这个遍历到的句柄来切换
6. 退出循环
现在一共有2个浏览器窗口,切换窗口的程序代码:
# 切换到新窗口
a=driver.current_window_handle
b=driver.window_handles
for c in b:
if c!=a:
driver.switch_to.window(c)
break现在一共有3个窗口,希望能切换到网页标题是“复选框案例”的窗口
a=driver.current_window_handle
b=driver.window_handles
for c in b:
if c!=a:
driver.switch_to.window(c)
if driver.title=="复选框案例":
break下标切换窗口
第一个窗口下标为0,依次~
handle = browser.window_handles
browser.switch_to_window(handle[1])
如果有验证码功能怎么实现自动化?
1. 后台给予一个万能验证码(不变的一个验证码)
2. 后台注释掉验证码功能,等上线前(等自动化实现)对验证码做测试保证无误
3. 识别验证码