首先我们要明白正则表达式是什么,用来作什么
正则表达式是一个特殊的符号序列,他帮助开发人员检查是否与某种模式匹配。
正则表达式常用的符号
一般字符

说明:
"."字符为匹配单个字符。例如,a.b可以的匹配结果为abc,aic,a&c等等,但不包括换行符
""字符为转义字符,例如“ ”。
"[...]"为字符集,相当于在中括号中任选一个。例如a[bcd],匹配的结果为ab,ac,ad。
预定义字符集

说明:
正则表达式中预定义字符集易于理解,在爬虫实战中,通常会匹配数字而过滤文字部分的信息。例如“数字3450”,只需要数字信息,通过“d+”来匹配数据,“+”为数量词,匹配前一个字符1或无限次,这样便可以匹配到所有的数字。
数量词
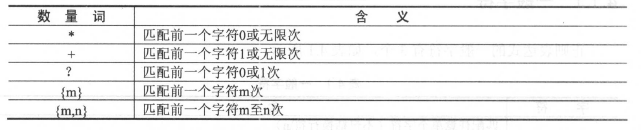
例子:
"*":ab*c 匹配ac abc abbc abbbc等等
“+“: ab+c匹配abc abbc abbbc 等等
“?” :ab?c 匹配 ac abc
"{m}":ab{3}c匹配abbbc
"{m,n}":ab{1,3}c 匹配abc abbc abbbc
边界匹配

例子:
"^": ^abc匹配abc开头的字符串
"$":abc$匹配abc结尾的字符串
在爬虫实战中常用的(.*?)"()"表示括号的内容作为返回结果,".*?"是非贪心算法,匹配任意的字符。
import re a="xxIxxxxlivexxxxstudyxx" info=re.findall('xx(.*?)xx',a) print(info)
re模块及其方法
search()函数
匹配并提取第一个符合规律的内容,返回一个正则表达式对象。
import re b="one1,tow2three3" info1=re.search("d+",b).group() print(info1)
sub函数
用于替换字符串中的匹配项
import re phone="123-456-789" new_phone=re.sub('D','',phone) print(new_phone)
findall()函数
匹配所有符合规律的内容,并以列表的形式返回结果。
import re a="xxIxxxxlivexxxxstudyxx" info=re.findall('xx(.*?)xx',a) print(info)
re模块修饰符
