Spark权威指南读书笔记(五) 数据源、 SparkSQL 与 Dataset
一、数据源
数据源API结构
Read API结构
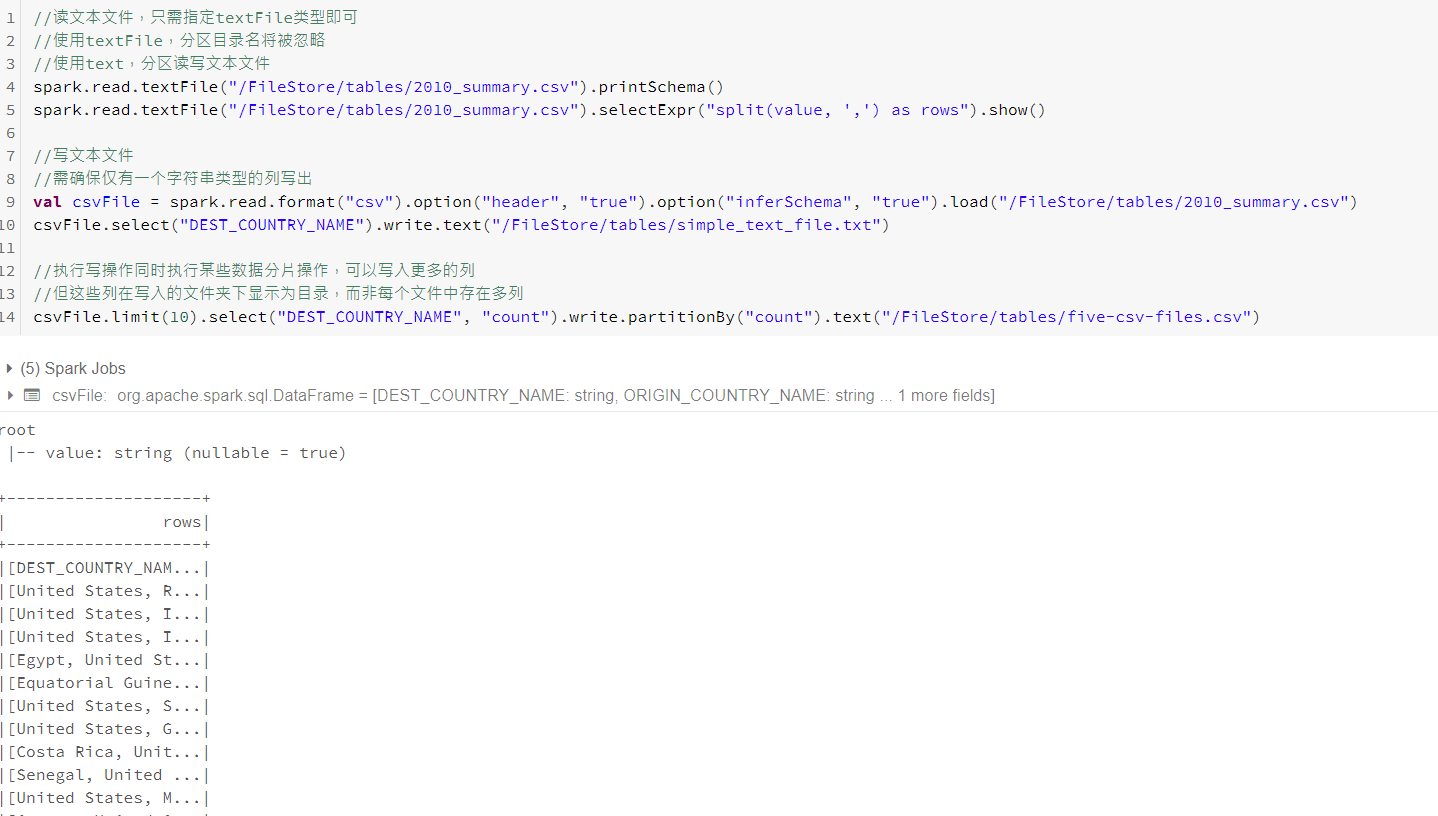
DataFrameReader.format(...).option("key", "value").schema(...).loadformat可选,默认情况下Spark使用Parquet格式,option配置键值对参数化读取数据方式。可通过指定schema解决数据源schema或使用模式推理(schema inference)。
Spark数据读取使用DataFrameReader,可通过SparkSession的read属性获得
Spark.read此外还需要指定以下值:
- format
- schema
- read模式
- 一系列option选项
format、option和schema都会返回一个DataFrameReader。
举例而言:
spark.read.format("csv").option("mode", "FAILFAST").option("inferSchema", "true").option("path", "path/to/file(s)").schema(someSchema).load()读取模式(默认是 permissive)
读取模式 说明 permissive 当遇到错误格式的记录时,将所有字段设置为null并将所有错误格式的记录放在_corrupt_record字符串列中 dropMalformed 删除包含错误格式记录的行 failFast 遇到错误格式的记录后立即返回失败 Write API结构
DataFrameWriter.format(...).option(...).partitionBy(...).bucketBy(...).sortBy(...).save()format是可选的,默认情况下Spark使用parquet格式,option用于配置写出数据的方法,PartitionBy、bucketBy和sortBy仅使用于基于文件的数据源。
首先需要使用DataFrame的write属性来获取DataFrameWriter:
dataFrame.write此外还需指定三个值,format,一系列option选项和save模式,并且必须至少提供一条写入路径来指定目标地址。
举例如下:
dataFrame.write.format("csv").option(" mode", "OVERWRITE").option(" dataFormat", "yyyy-MM-dd").option("path", "path/to/file(s)").save()保存模式
保存模式 描述 append 将输出文件追加到目标路径已存在文件上或目录的文件列表 overwrite 指完全覆盖目标路径中已存在的任何数据 errorIfExists 如果目标已存在数据或文件,则抛出错误并返回写入操作失败 ignore 如果目标已存在数据或文件,则不执行任何操作
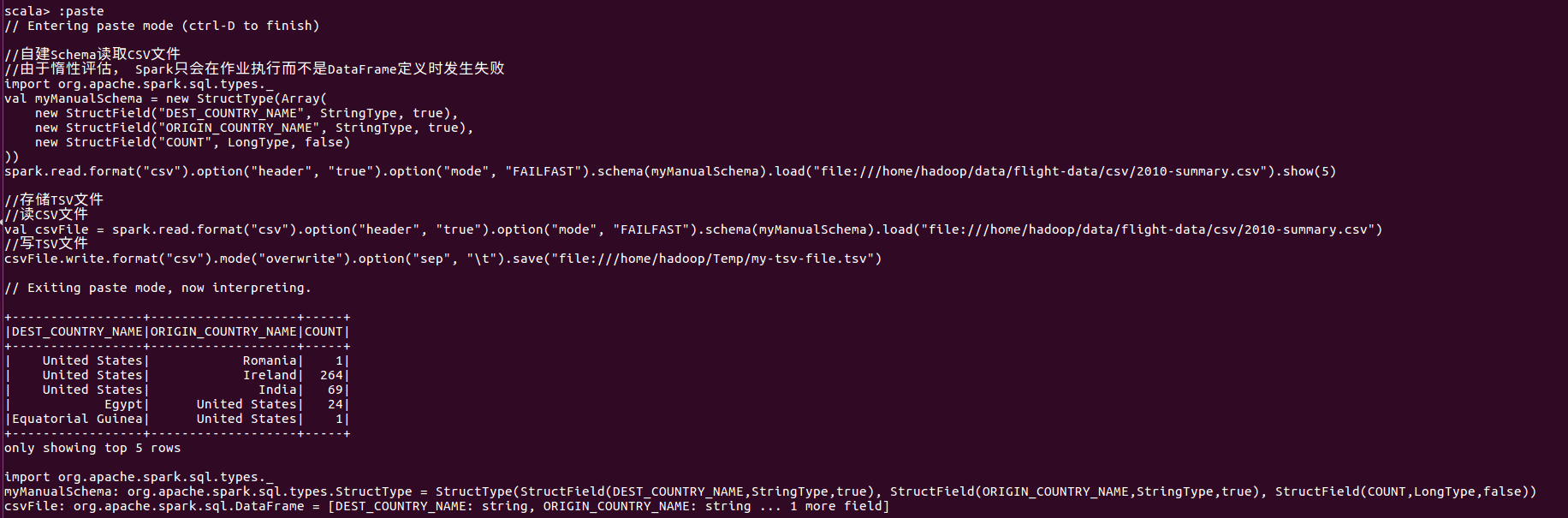
CSV(逗号分隔值)文件
csv选项
read/write Key 取值范围 默认值 说明 Both sep 任意单个字符串字符 , 用作每个字段和值得分隔符的单个字符 Both header true,false false 一个布尔标记符,用于声明文件中的第一行是否为列的名称 Both escape 任意字符串字符 用于转义的字符 Both inferSchema true,false false 指定在读取文件时,Spark是否主动推断列类型 Both ignoreLeadingWhiteSpace true,false false 声明是否应跳过读取值中的前导空格 Both ignoreTrailingWhiteSpace true,false false 声明是否应跳过读取值中的尾部空格 Both nullValue 任意字符串字符 “” 声明在文件中什么字符表示null值 Both nanValue 任意字符串字符 NaN 声明什么字符表示CSV文件中的NaN或缺失字符 Both positiveInf 任意字符串字符 Inf 声明什么字符表示正无穷大 Both negativeInf 任意字符串字符 -Inf 声明什么字符表示负无穷大 Both Compression 或 codec None, uncompressed, bzip2, deflate, gzip, lz4, or snappy none 声明Spark应该使用什么压缩编解码器来读取或写入文件 Both dateFormat 任何符合Java的SimpleDataFormat的字符串或字符 yyyy-MM-dd 日期类型的日期格式 Both timestampFormat 任何符合Java的SimpleDataFormat的字符串或字符 MMdd ‘T’ HH:mm:ss.SSSZZ 时间戳类型时间戳格式 Read maxColumns 任意整数 20480 声明文件中的最大列数 Read maxCharsPerColumn 任意整数 1000000 声明列中的最大字符数 Read escapeQuotes true, false true 声明Spark是否应该转义在行中找到的引号 Read maxMalformedLogPerPartition 任意整数 10 设置Spark将为每个分区记录错误格式的行的最大数目,超出此数目的格式错误记录将被忽略 Write quoteAll true,false false 指定是否将所有制括在引号中,而不是仅转义具有引号字符的值 read multiline true,false false 此选项用于读取多行CSV文件,其中CSV文件中的每个逻辑行可能跨越文件中的多行
JSON(JavaScript Object Notation)
换行符分隔JSON对象还是一个对象可以跨越多行,这个可以由multiLine选项控制。当multiLine为true时,则可以将整个文件作为一个json对象读取, 并且Spark将其解析为DataFrame。换行符分隔的JSON实际上是一种更稳定的格式,因为它可以在文件末尾追加新纪录。换行符分隔的JSON格式另一个关键原因是JSON对象具有结构化信息,并且JavaScript也支持基本类型。
read/write key 取值范围 默认值 说明 Both Compression或codec None, uncompressed, bzip2, deflate, gzip, lz4, or snappy none 声明Spark应该使用什么压缩编解码器来读取或写入文件 Both dateFormat 任何符合Java的SimpleDataFormat的字符串或字符 yyyy-MM-dd 日期类型的日期格式 Both timestampFormat 任何符合Java的SimpleDataFormat的字符串或字符 MMdd ‘T’ HH:mm:ss.SSSZZ 时间戳类型时间戳格式 Read primitiveAsString true、false false 将所有原始值推断为字符串类型 Read allowComments true、false false 忽略JSON记录中的Java/C++样式注释 Read allowUnquotedFieldNames true、false false 允许不带引号的JSON字段名 Read allowSingleQuotes true、false false 除双引号外,还允许使用单引号 Read allowNumericLeadingZeros true、false false 允许数字中存在前导零(如:00012) Read allowBackslashEscAPIngAny true、false false 允许反斜杠机制接受所有字符 Read columnNameOfCorruptRecord Any string spark.sql.column & NameOfCorruptRecord 允许重命名,permissive模式下添加的新字段,会覆盖重写 Read multiLine true、false false 允许读取非换行符分隔的JSON文件
parquet
parquet提供列压缩从而可以节省空间,且支持复杂类型。
read/write key 取值范围 默认值 说明 write Compression 或 codec None, uncompressed, bzip2, deflate, gzip, lz4, or snappy none 声明Spark应该使用什么压缩编解码器来读取或写入文件 read merge Schema true, false 配置值 spark.sql.parquet.mergeSchema 增量添加列到同一个表/文件夹中的parquet文件里,此选项用于启用或禁用此功能
ORC文件
ORC为Hadoop作业设计的自描述,类型敏感的列存储文件格式。针对大型流式数据读取进行优化,继承了对快速查找所需行的相关支持。与parquet相似,二者本质区别在于Parquet针对Spark进行优化,ORC针对Hive进行优化。
SQL数据库
读写数据库需要两步:在Spark类路径中为指定的数据库包含Java Database Connectivity(JDBC)驱动,并为连接驱动器提供合适的JAR包。
./bin/spark-shell --driver-class-path postgresql-9.4.1207.jar --jars postgresql-9.4.1207.jarJDBC数据源选项
属性名称 说明 Url 表示要连接的JDBC URL,可以在URL中指定特定源的连接属性 dbtable 表示要读取的JDBC表,请注意,可以使用SQL查询的From子句中任何有效内容 driver 用于连接此URL的JDBC驱动器的类名 partitionColumn, lowerBound, upperBound 若指定三者之一,则需要设置其他选项,还需设置numPartitions 这些属性主要描述如何在从多个worker并行读取时对表格进行划分。partitionsColumn是要分区的列,必须是整数类型。lowerBound和 upperBound仅用于确定分区跨度,而不用于过滤表中的行。 numsPartitions 读取与写入数据表时,数据表可用于并行的最大分区数。这决定了并发JDBC连接最大数目。若写入分区数超过限制,则可通过写入前调用coalesec(numPartitions)来讲分区数降到符合此标准。 fetchsize 表示 JDBC每次读取多少条记录。此选项与JDBC驱动器性能相关。JDBC驱动器默认该值为低获取行数。仅适用于读操作。 batchsize 表示JDBC批处理大小,即指定每次写入多少条记录。此选项与JDBC驱动器性能相关。仅适用于写操作。默认值为1000. isolationLevel 表示数据库的事务隔离级别。取值分别为NONE,READ_COMMITED, READ_UNCOMMITED, REPEATABLE_READ, 或SERIALIZABLE,分别对应于JDBC的connection对象定义的标准事务隔离级别。默认值为READ_UNCOMMITED. 仅使用于写操作。 truncate JDBC写入相关选项。Spark执行覆盖表操作时,即启用SaveMode.Overwrite, Spark将截取现有表, 而不是删除之后再重新创建。这样可以提高效率,并防止表元数据被删除。默认为false,仅适用于写操作。 createTableOptions JDBC写入相关选项。用于在创建表时设置特定数据库的表和分区选项。如, CREATE TABLE t (name string) ENGINE=InnoDB. 仅适用于写操作 createTableColumnTypes 表示创建表时使用数据库列数据类型,而不是使用默认值。应使用与CREATE TABLE列语法相同格式来指定数据类型。指定类型应为Spark SQL数据类型。(如 “name CHAR(64) , commects VARCHAR(1024 )”)。仅适用于写操作。 //DataBrikes使用异常,使用本地环境测试 //以sqlite为例 //从SQL数据库中读取数据 val driver = "org.sqlite.JDBC" val path = "/home/hadoop/data/flight-data/jdbc/my-sqlite.db" val url = "jdbc:sqlite:" + path val tablename = "flight_info" /* 使用mysql等数据库时,需要进行连接测试 ** import java.sql.DrivenManager ** val connection = DriverManager.getConnection(url) ** connection.isClosed() ** connection.close() */ //sqlite库中表读取数据 val dbDataFrame = spark.read.format("jdbc").option("url", url).option("dbtable", tablename).option("driver", driver).load() dbDataFrame.show(5)
查询下推
在某些查询中,Spark会将过滤器函数下推到数据库端。
dbDataFrame.filter("DEST_COUNTRY_NAME in ('Auguilla', 'Sweden')").explain() == Physical Plan == *Scan JDBCRelation(flight_info) [numPartitions=1] [DEST_COUNTRY_NAME#0,ORIGIN_COUNTRY_NAME#1,count#2] PushedFilters: [*In(DEST_COUNTRY_NAME, [Auguilla,Sweden]], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:decimal(20,0)> //Spark不能把它的所有函数转换为你所用的SQL函数,有时需要使用SQL表达整个查询并将结果作为DataFrame返回。可采用将查询语句包含在括号内,对其重名命名 //查询下推 查询语句重命名 val pushdownQuery = """(SELECT DISTINCT (DEST_COUNTRY_NAME) FROM flight_info) AS flight_info""" val dbDataFrame = spark.read.format("jdbc").option("url", url).option("dbtable", pushdownQuery).option("driver", driver).load() dbDataFrame.explain() == Physical Plan == *Scan JDBCRelation((SELECT DISTINCT (DEST_COUNTRY_NAME) FROM flight_info) AS flight_info) [numPartitions=1] [DEST_COUNTRY_NAME#0] ReadSchema: struct<DEST_COUNTRY_NAME:string>并行读取数据库
spark有一个底层算法,可以将多个文件放入一个数据分片,或者反过来将一个文件划分到多个数据分片,这取决于文件大小、文件类型及压缩格式是否允许划分。
//指定最大分区数(由于文件过小,仍是一个分区) val dbDataFrame = spark.read.format("jdbc").option("url", url).option("dbtable", tablename).option("driver", driver).option("numPartitions", 10).load() dbDataFrame.explain() == Physical Plan == *Scan JDBCRelation(flight_info) [numPartitions=1] [DEST_COUNTRY_NAME#0,ORIGIN_COUNTRY_NAME#1,count#2] ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:decimal(20,0)> //连接中显式将谓词下推到SQL数据库执行 //有利于通过指定谓词来控制分区数据的物理存放位置 //注意谓词不相交的情况下,易出现大量重复行 val props = new java.util.Properties props.setProperty("driver", "org.sqlite.JDBC") val predicates = Array( "DEST_COUNTRY_NAME = 'Sweden' OR ORIGIN_COUNTRY_NAME = 'Sweden'", "DEST_COUNTRY_NAME = 'Anguilla' OR ORIGIN_COUNTRY_NAME = 'Anguilla'" ) spark.read.jdbc(url, tablename, predicates, props).show() spark.read.jdbc(url, tablename, predicates, props).rdd.getNumPartitions +-----------------+-------------------+-----+ |DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count| +-----------------+-------------------+-----+ | Sweden| United States| 65| | United States| Sweden| 73| | Anguilla| United States| 21| | United States| Anguilla| 20| +-----------------+-------------------+-----+基于滑动窗口的分区
这个例子中将对第一个分区和最后一个分区分别设置一个最小值于最大值,超出该范围的数据将存放第一个分区或最后一个分区。
val colName = "count" val lowerBound = 0L val upperBound = 348113L val numPartitions = 10 val props = new java.util.Properties props.setProperty("driver", "org.sqlite.JDBC") //下列操作根据count列数值从小到大均匀划分10个间隔区间数据,之后每个区间数据会被分配到一个分区 val ans = spark.read.jdbc(url, tablename, colName, lowerBound, upperBound, numPartitions, props).count() output:255 与 count(*) 结果一致写入SQL数据库
val props = new java.util.Properties props.setProperty("driver", "org.sqlite.JDBC") val newPath = "jdbc:sqlite://home/hadoop/Temp/my_sqlite.db" val csvFile = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("file:///home/hadoop/data/flight-data/csv/2010-summary.csv") //以overwrite模式写入SQLite数据库 csvFile.write.mode("overwrite").jdbc(newPath, tablename, props) //以append方式向表尾追加数据 csvFile.write.mode("append").jdbc(newPath, tablename, props) import org.apache.spark.sql.functions.count println(spark.read.jdbc(newPath, tablename, props).count()) OUTPUT: overwrite: 255 append: 510
文本文件
Spark支持纯文本文件,文件中的每一行被解析为DataFrame中一条记录,然后根据你的要求进行转换。由于文本文件能够充分利用原生类型的灵活性,很适合作为Dataset API输入。
高级I/O概念
并行读数据
多个执行器不能同时读取同一文件,但可以同时读取不同的文件。通常,这意味着当你从包含多个文件的文件夹中读取时,每个文件都将被视为DataFrame的一个分片,并由执行器并行读取,多余文件会进入读取队列等候。
并行写数据
写数据涉及文件数量取决于DataFrame的分区数,默认情况是每个数据分片都会有一定的数据写入,这意味虽然我们指定的是一个文件,但实际上它是由一个文件夹的多个文件组成,每个文件对应着一个数据分片。
数据划分
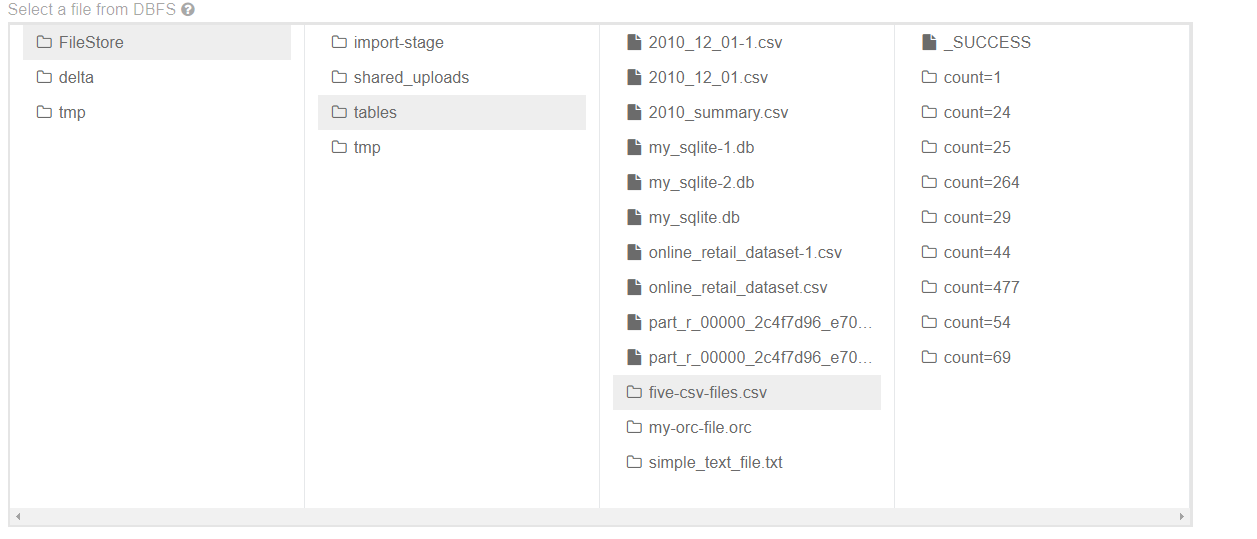
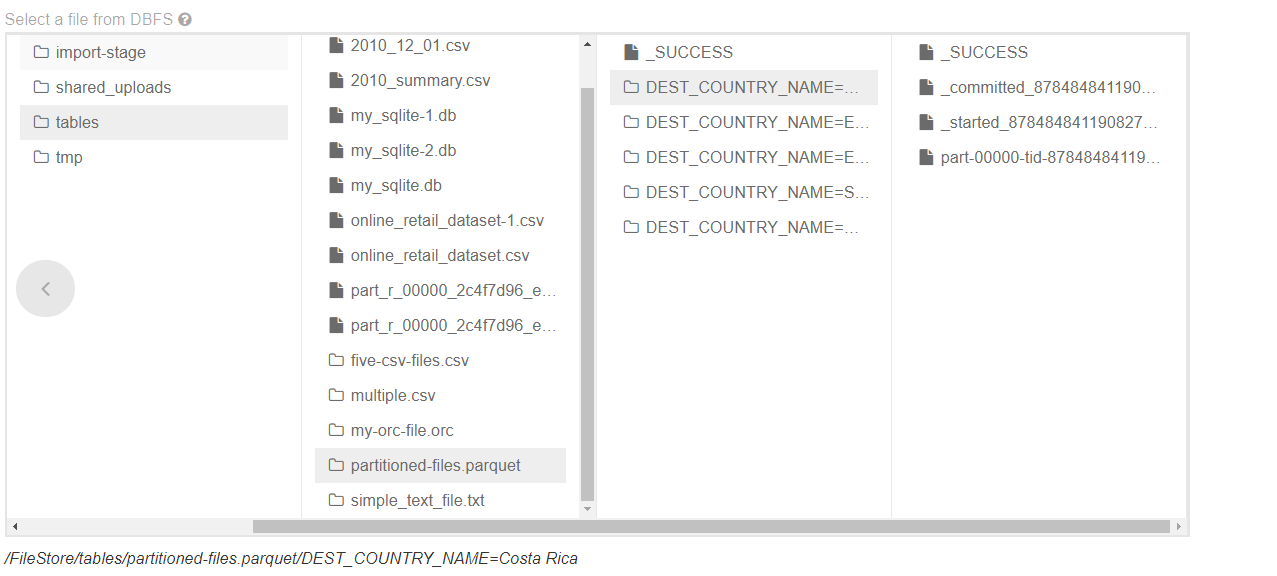
数据划分工具支持在写入数据时控制存储数据以及存储数据的位置。将文件写出时,可以将列编码作为文件夹,使得之后读取时可以跳过大量数据,只读入与问题相关的列数据而不必扫描整个数据集。
数据分桶
使用数据分桶可以控制每个文件的数据。具有相同桶ID(哈希分桶ID)数据将放置到一个物理分区中,避免在之后读取数据时进行shuffle。
管理文件大小
Spark不适合处理小文件
在2.2版本中引入了更自动化控制文件大小的新方法,使用maxRecordPerFile选项指定每个文件的最大记录数,可以通过控制写入文件的记录数来控制文件大小。

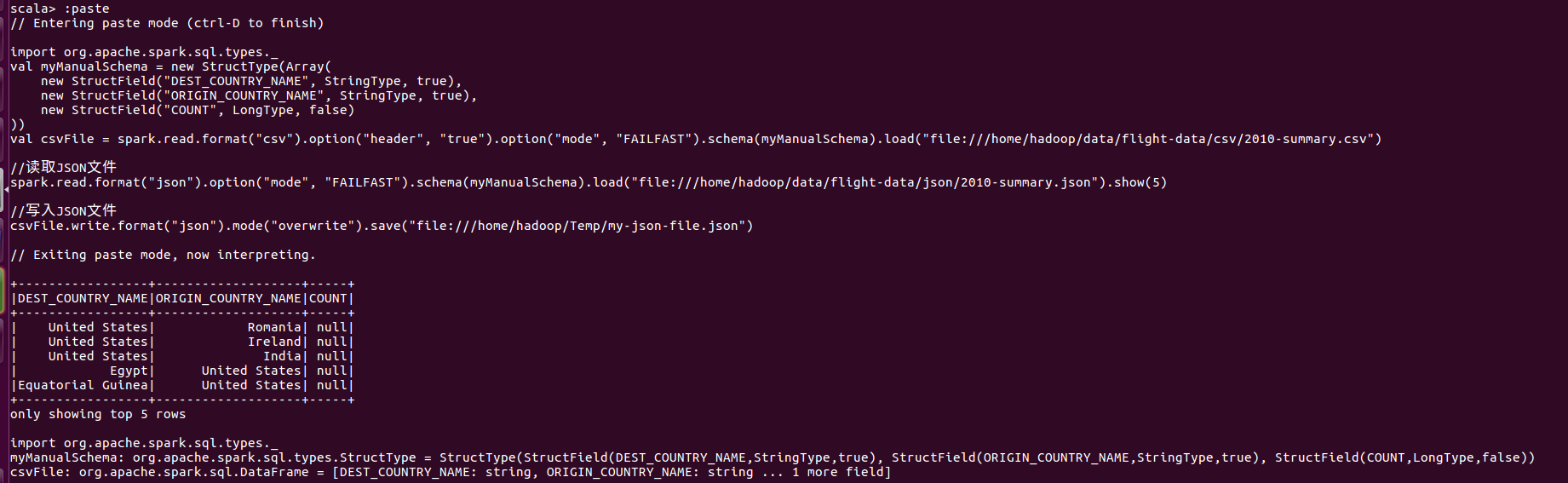


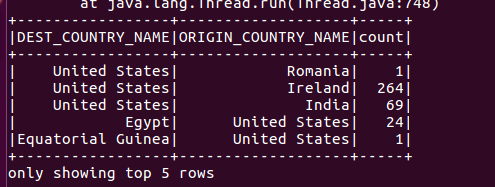

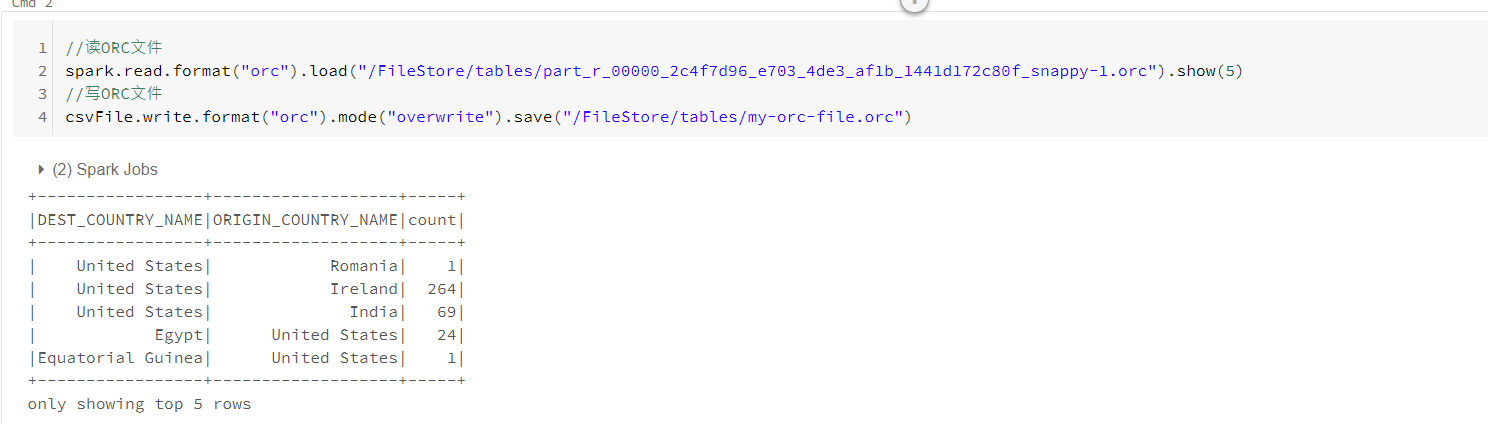
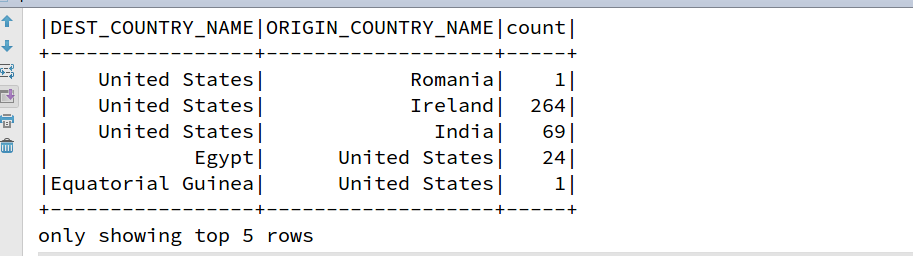




二、SparkSQL
SparkSQL 目的是作为一个在线分析处理(OLAP)数据库存在,而非在线事务处理(OLTP)数据库。Spark SQL目前并不适用于执行对低延迟要求极高的查询。
Spark与 Hive
SparkSQL 可以与 Hive metastores连接。Hive metastores维护了Hive跨会话数据表信息。使用SparkSQL可以连接到Hive metastores访问表的元数据,可以在访问信息时候减少文件列表操作带来的开销。
连接Hive metastores
首先,你需要设置spark.SQL.hive.metastore.version(Metastore版本),对应于需要放问的Hive metastore,默认版本号1.2.1.如需更改HiveMetastoreClient初始化方式,还需设置Spark.SQL.hive.metastore.jars.Spark使用默认版本,也可以通过设置JVM来指定Maven repositories 或 classpath。设置Spark与Hive共享前缀spark.SQL.hive.metastore.sharedPrefixes,以提供适当的类前缀,以便于存储Hive metastore不同数据库进行通信。
Spark SQL CLI
Spark SQL CLI无法与Thrift JDBC服务端通信。可通过修改conf文件夹下hive-site.xml, core-site.xml , hdfs-site.xml进行配置。
Spark 可编程SQL接口
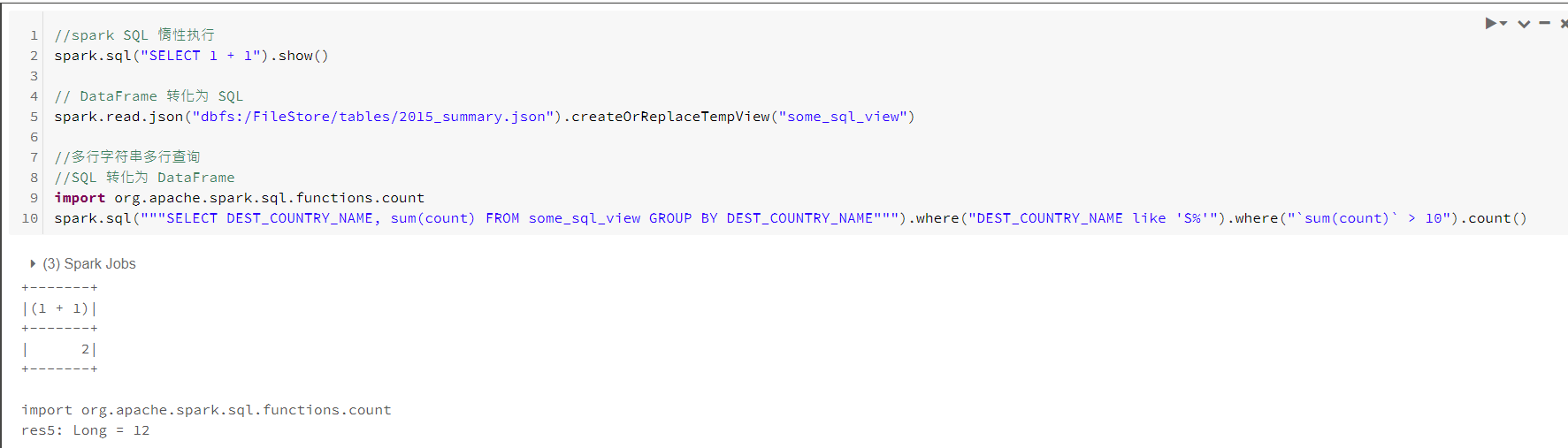
可通过SparkSession对象上sql方法实现,返回一个DataFrame。
SparkSQL Thrift JDBC/ODBC 服务器
Spark提供一个JDBC接口,以便执行Spark SQL查询。
//启动JDBC/ODBC服务器 支持Spark-submit命令行选项 ./sbin/start-thriftserver.sh // -- help 帮助选项 //默认情况下,服务器监听localhost:10000 //环境变量配置 export HIVE_SERVER2_THRIFT_PORT = <listening-port> export HIVE_SERVER2_THRIFT_BIND_PORT = <listening-host> ./sbin/start-thriftserver.sh -- master <master-url> ... //系统属性 ./sbin/start-thriftserver.sh --hiveconf hive.server2.thrift.port = <listening-port> --hiveconf hice.server2.thrift.bind.port = <listening-host> --master <master-url> //使用beeline测试连接 ./bin/beeline beeline> !connect jdbc:hive2//localhost:10000Catalog
SparkSQL中最高级别抽象。Catalog是一个抽象,用于存储用户数据中的元数据以及其他有用的东西。它在org.apache.spark.SQL.catalog.Catalog包中包含很多有用的函数。
数据表
数据表在逻辑上等同于DataFrame,均是承载数据的数据结构。数据表与DataFrame的核心区别在于,DataFrame是编程语言范围内定义的,而数据表是在数据库内定义的。需要注意的是在Spark2.x中,数据表始终是实际包含数据的,没有视图的临时表概念,只有视图不包含数据。
托管表
托管表(managed table)与非托管表(unmanaged table)均是重要概念。表存储两类重要信息,即表中数据和元数据(关于表中的数据)。当定义磁盘上的若干文件为一个数据表时,这就是非托管表。若通过DataFrame使用saveAsTable函数创建的数据表,即为托管表,Spark会跟踪托管表的所有相关信息。
在DataFrame上使用saveAsTable函数将读取你的表并将其写到一个新的位置。默认是写入Hive仓库位置。可通过配置spark.SQL.warehouse.dir为SparkSession时所选择的目录。默认情况下,Spark将此设置为/user/hive/warehouse.
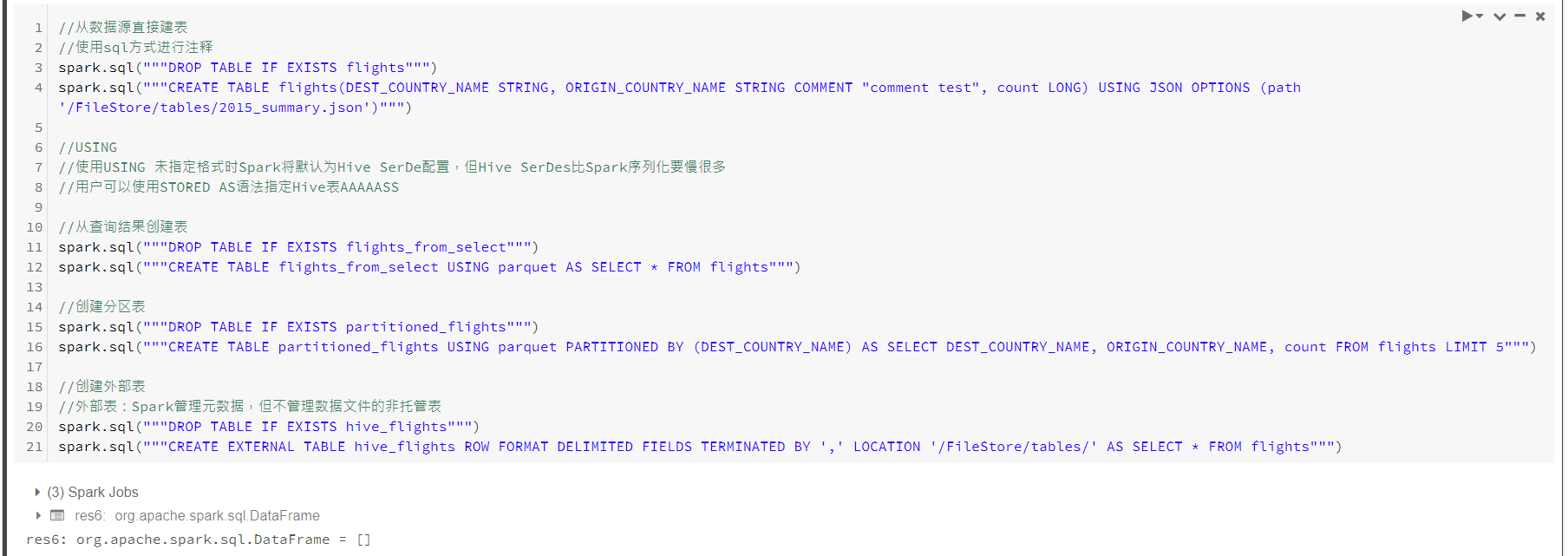
创建表
插入表
元数据
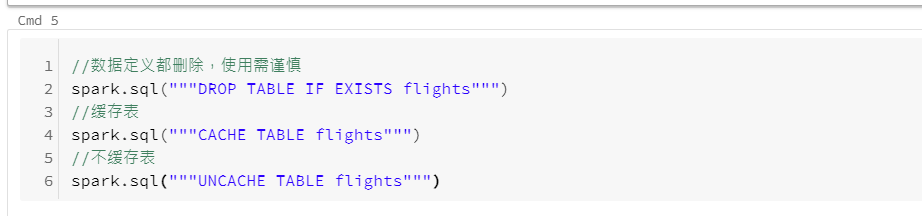
删除与缓存表
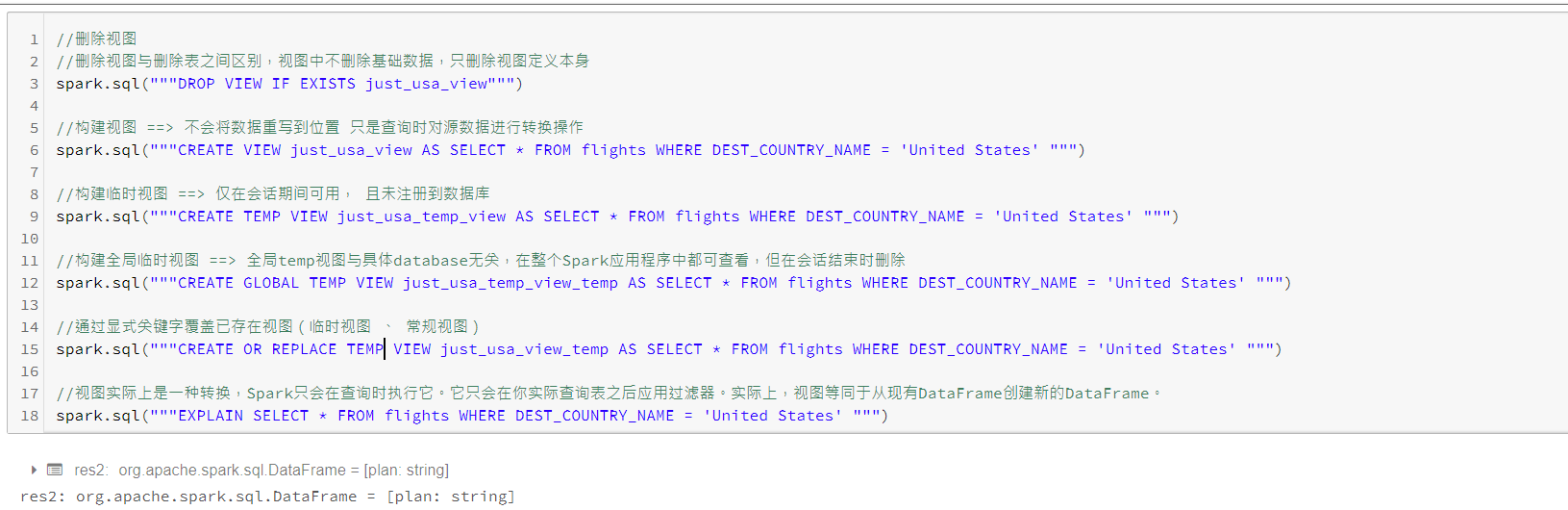
视图
定义视图即指定基于现有表的一组转换操作,基本上只是保存查询计划,方便组织或重用查询逻辑。
数据库
选择语句
SELECT [ALL|DISTINCT] named_expression[, named_expression, ...] FROM relation[, relation, ...] [lateral_view[, lateral_view, ...]] [WHERE boolean_expression] [aggregation [HAVING boolean_expression]] [ORDER BY sort_expression] [CLUSTER BY expression] [DISTRIBUTE BY expression] [SORT BY expression] [WINDOW named_window[, WINDOW named_window, ...]] [LIMIT num_rows] named_expression: :expression [AS alias] relation: | join_relation | (table_name|query|relation) [sample][As alias] | VALUES (expression)[, (expression), ...] [AS (column_name[, column_name, ...])] //case...when...then...end SELECT CASE WHEN DEST_COUNTRY_NAME = 'UNITED STATES' THEN 1 CASE WHEN DEST_COUNTRY_NAME = 'Egypt' THEN 0 ELSE -1 END FROM partitioned_flights复杂结构
函数
//查看函数列表 SHOW FUNCTIONS //查询系统函数 SHOW SYSTEM FUNCTIONS //查看用户函数 SHOW USER FUNCTIONS //使用通配符查看函数 SHOW FUNCTIONS "S*" SHOW FUCNTIONS LIKE "collect*" //UDF 与之前提到的一致 def power3(number: Double): Double = number * number * number spark.udf.register("power3", power(_: Double): Double) spark.sql("""SELECT count, power3(count) FROM flights""")子查询
//Spark中包括两个子查询,相关子查询和不相关子查询。 //不相关子查询 不依赖与外部的查询(两个不相关查询组合) spark.sql(""" SELECT * FROM flights WHERE Origin_country_name IN ( SELECT dest_country_name FROM flight ORDER BY sum(count) DESC LIMIT 5 ) """) //相关子查询依赖于外部查询。多数情况下是子查询的WHERE子句中引用了外部查询的表 spark.sql(""" SELECT * FROM flights f1 WHERE ESISTS (SELECT 1 FROM flight f2 WHERE f1.dest_country_name = f2.origin_country_name) AND EXISTS (SELECT 1 FROM flight f2 WHERE f2.dest_country_name = f1.origin_country_name ) """)SparkSQL 配置
property name default meaning spark.sql.inMemoryColumnarStorage.compressed true 若为true,则SparkSQL会根据统计信息自动为每一列选择压缩编码器 spark.sql.inMemoryColumnarStorage.batchSize 10000 控制柱状缓存批处理大小,较大的批处理可提供内存利用率和压缩能力,但缓存易造成OOMs。 spark.sql.files.maxPartitionBytes 128M 单个分区的最大字节数 spark.sql.files.openCostInBytes 4MB 打开一个文件的开销估计,即同时可以扫描的字节数量。配置大一些,装着小文件的分区往往比装更大的分区运行更快。 spark.sql.broadcastTimeout 300 广播连接中广播等待时间的超时秒数 spark.sql.autoBroadcastJoinThreshold 10MB 广播给所有工作节点的表的最大大小,可将此值设置为-1来禁用广播 spark.sql.shuffle.partitions 200 配置在为连接或聚合shuffle数据时分区数




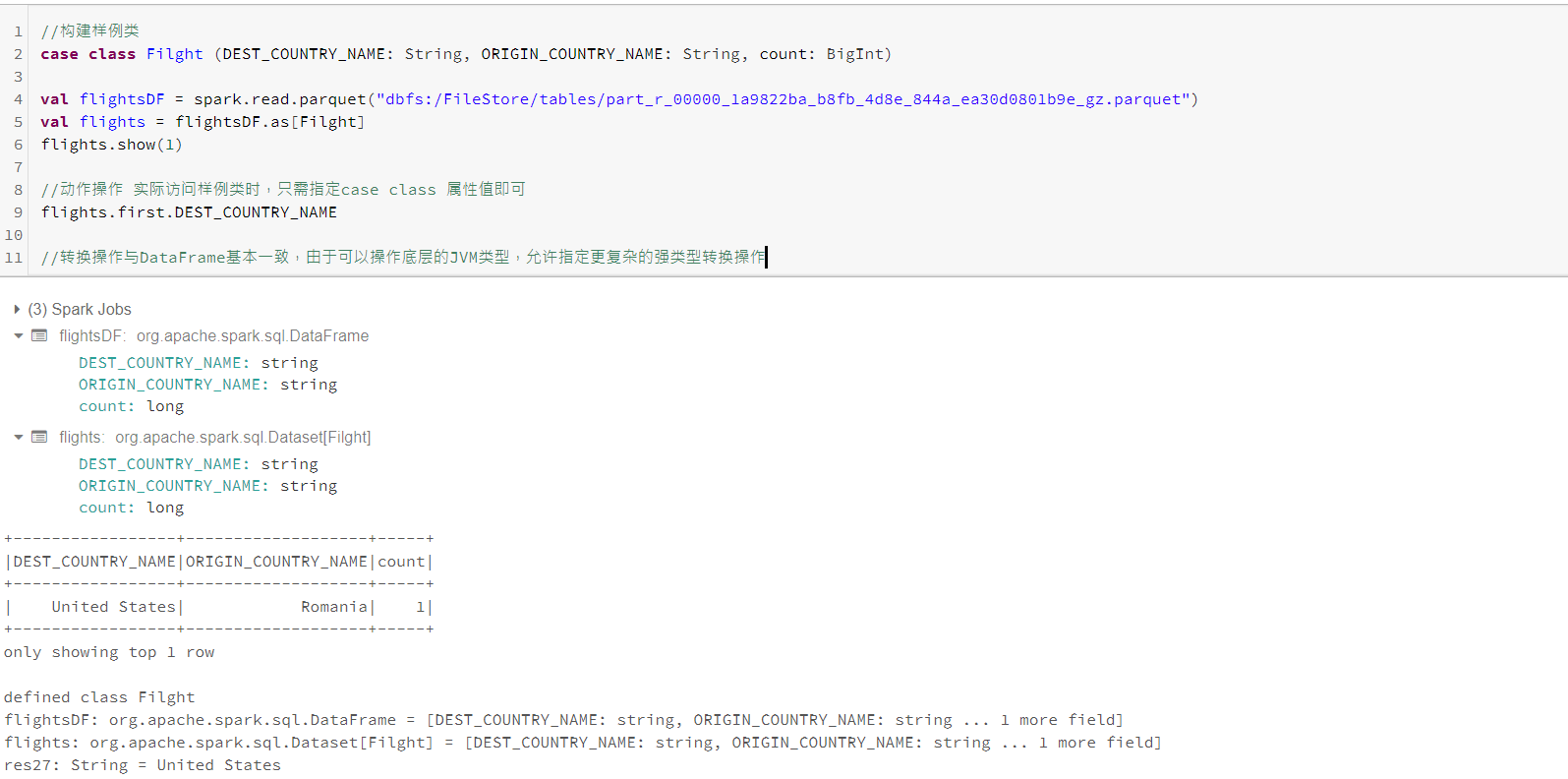
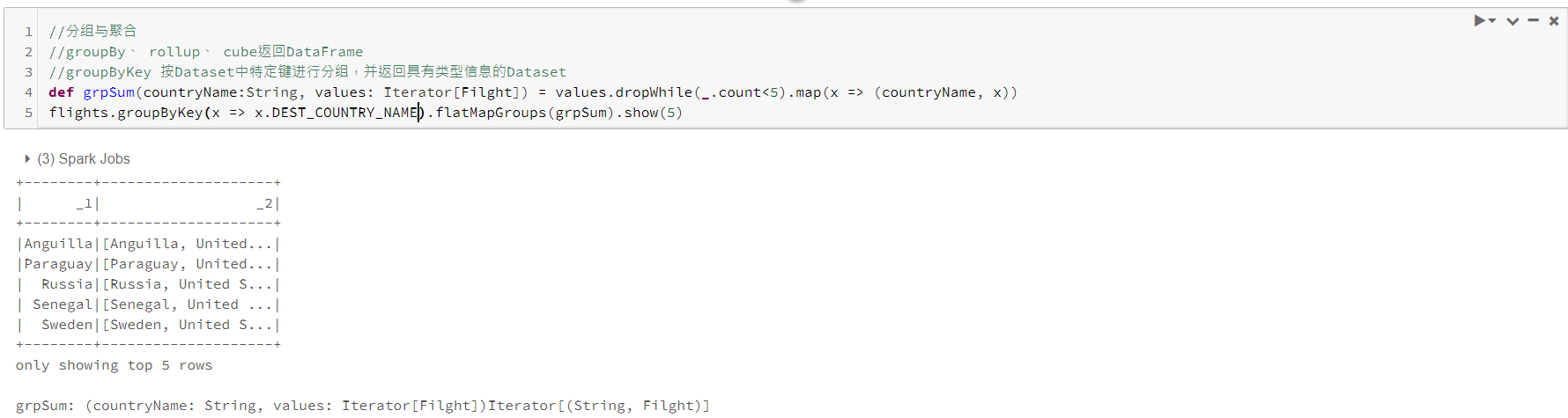
三、Dataset
Dataset 是具有严格的JVM语言特性,可定义Dataset中每一行所包含的对象,在scala中就是一个样例类,实质上定义了一种模式Schema。 为了有效的支持特定领域对象,需要一个“编码器”的特殊概念,将特定领域类型T映射为Spark内部类型。
为什么使用Dataset
- 当你要执行的操作无法使用DataFrame操作表示时
- 若需要类型安全,并且愿意牺牲一定性能来实现它
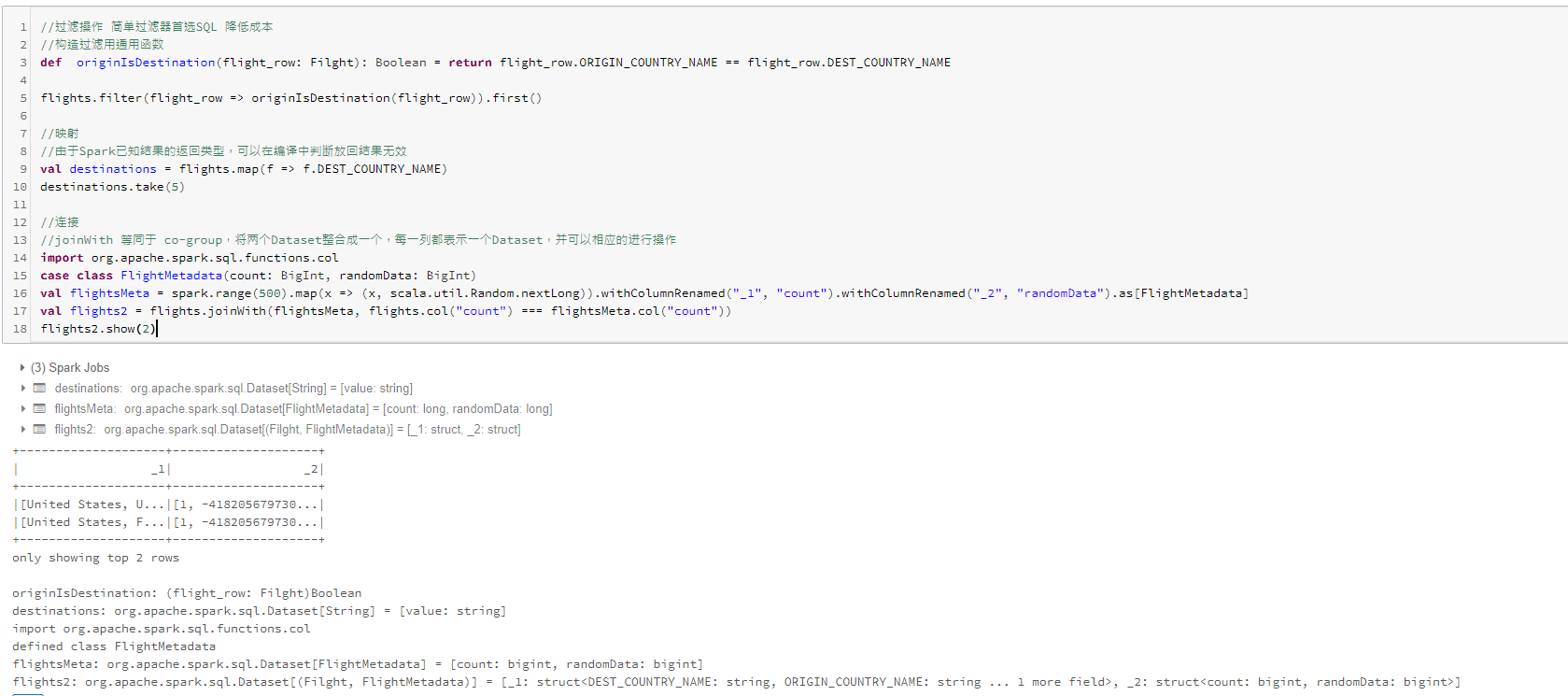
Dataset API类型安全,对其类型无效操作将在编译时出错,而不是运行时失败。使用Dataset的另一种情况是,在单节点作业和spark作业建重用对行的各种转换代码。使用Dataset的一个优点在于,如果你将所有数据和转换定义为case类,那么在分布式或单机作业中使用并无区别。
创建Dataset、
样例(case)类特征
- 不可变
- 通过模式匹配可分解,来获取类属性
- 允许基于结构的比较而不是基于引用的比较
- 易于使用和操作
因此
- 不变性是你无需跟踪对象变化和时间和位置
- “按值比较”允许直接比较实例的值,避免了混淆类实例基于值比较或是引用表脚所带来的不稳定性
- 模式匹配简化了分支逻辑,更小的bug和更好的可读性