今天我们来谈一下akka的序列化框架,其实序列化、反序列化是一个老生常谈的问题,那么我们为什么还要研究一下akka的序列化框架呢?不就是使用哪种序列化、反序列化方法的区别么?其实刚开始的时候我也是这么想的,但是针对性、系统性的分析一下akka的序列化、反序列化过程,就会发现这个问题其实还是挺有意思的。
我们首先来看下什么是序列化、反序列化。序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程;反序列化,就是通过从存储区中读取或反序列化对象的状态,重新创建该对象。举个栗子,在跨网络传输的过程中,传输的都是二进制数,是无法直接传输对象的。对象是什么呢?数据和算法,状态和方法。数据就是对象的状态,比如一个整型字段的值,字符串的具体内容;算法就是对象所属的方法,简单来说就是二进制可执行代码。统一来看,他们都可以是二进制数据。那么为啥在序列化的定义中,没有说算法的。想想都知道,当然是为了减少传输的数据量啊。而且代码这部分不传输也是可以的,毕竟网络的两端代码这部分是需要预先协商好的。
那既然序列化就是用来保存、传输对象的状态的,那为啥还要单独研究akka的序列化框架呢?因为我喜欢!啊哈哈,其实也不是。主要是akka的序列化是一个框架,而不是只单独的某个算法或jar包。因为在这个框架内,你可以单独制定每个class的序列化、反序列化对应的实现。
记得之前在分析remote的时候,我们有谈到过序列化,下面还从这部分开始分析,因为这比较直接。如果上来就分析整个框架,比较容易迷失。
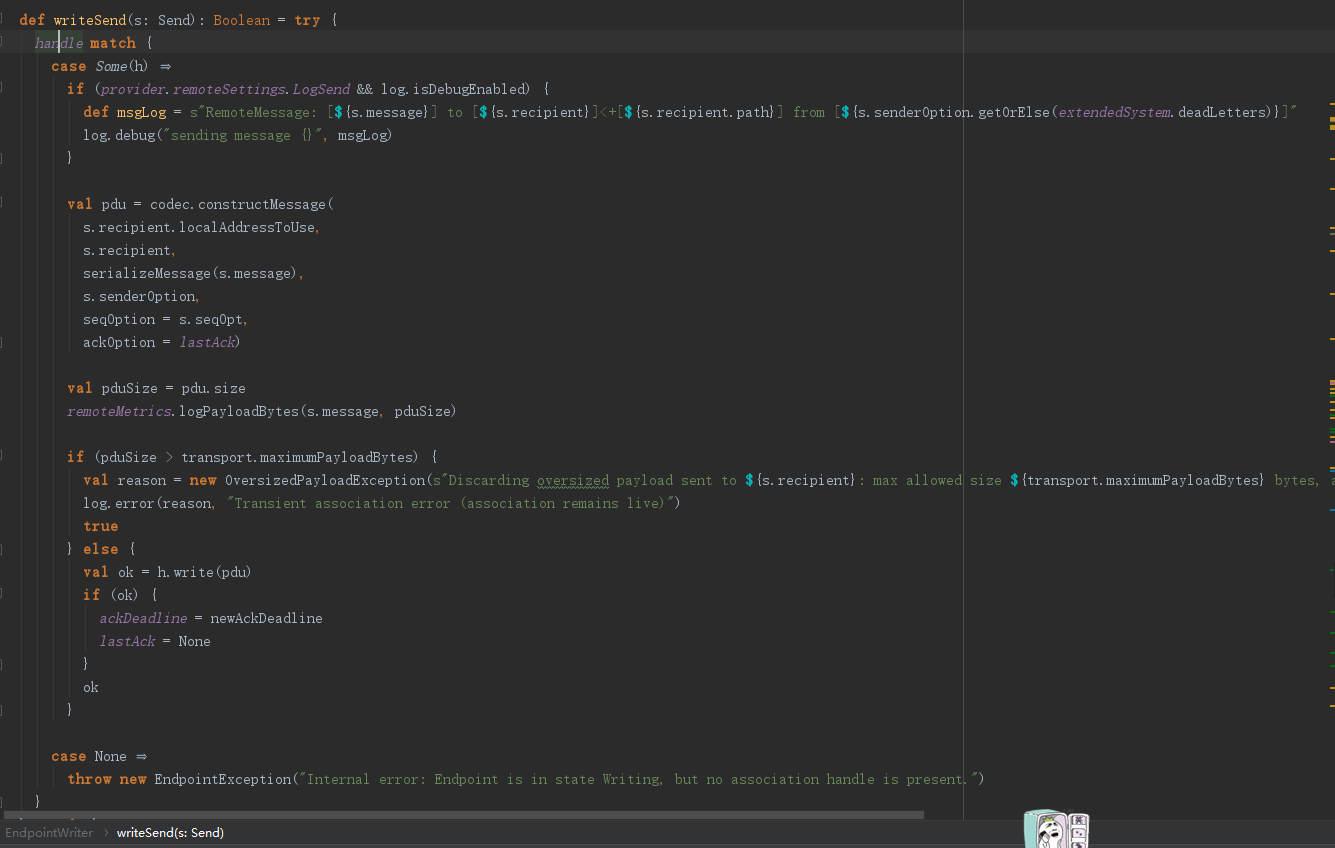
上面是跨网咯传输数据的相关代码,很明显,这里调用了codec.constructMessage,生成了pdu,然后调用handle.write把数据发送出去了。
def constructMessage(
localAddress: Address,
recipient: ActorRef,
serializedMessage: SerializedMessage,
senderOption: OptionVal[ActorRef],
seqOption: Option[SeqNo] = None,
ackOption: Option[Ack] = None): ByteString
也就是说constructMessage把待发送的消息转化成了ByteString,这就是可以跨网络传输的二进制数据流。不过还调用了serializeMessage这个方法,把用户待发送的消息序列化了。其实我们应该特别注意这一点,为啥呢?因为这意味着用户待发送数据的序列化和系统消息的序列化分开了,或者说是两个层面的东西。啥意思呢?简单来说就是,akka先调用序列化方法(可以是任意自定义)把用户待发送数据转成ByteString,然后把这个数据设置成系统消息的某个字段,再调用系统序列化器把系统消息序列化。
override def constructMessage(
localAddress: Address,
recipient: ActorRef,
serializedMessage: SerializedMessage,
senderOption: OptionVal[ActorRef],
seqOption: Option[SeqNo] = None,
ackOption: Option[Ack] = None): ByteString = {
val ackAndEnvelopeBuilder = AckAndEnvelopeContainer.newBuilder
val envelopeBuilder = RemoteEnvelope.newBuilder
envelopeBuilder.setRecipient(serializeActorRef(recipient.path.address, recipient))
senderOption match {
case OptionVal.Some(sender) ⇒ envelopeBuilder.setSender(serializeActorRef(localAddress, sender))
case OptionVal.None ⇒
}
seqOption foreach { seq ⇒ envelopeBuilder.setSeq(seq.rawValue) }
ackOption foreach { ack ⇒ ackAndEnvelopeBuilder.setAck(ackBuilder(ack)) }
envelopeBuilder.setMessage(serializedMessage)
ackAndEnvelopeBuilder.setEnvelope(envelopeBuilder)
ByteString.ByteString1C(ackAndEnvelopeBuilder.build.toByteArray) //Reuse Byte Array (naughty!)
}
上面是constructMessage的具体实现,可看到envelopeBuilder.setMessage(serializedMessage)这行代码确实把序列化后的数据赋值给了某个字段。
public Builder setMessage(akka.remote.WireFormats.SerializedMessage value) {
if (messageBuilder_ == null) {
if (value == null) {
throw new NullPointerException();
}
message_ = value;
onChanged();
} else {
messageBuilder_.setMessage(value);
}
bitField0_ |= 0x00000002;
return this;
}
这是setMessage的代码。需要特别注意的是它的参数是SerializedMessage类型,而不是ByteString。这意味着什么呢?这意味着,还有一层。

目前来看,序列化的过程大概是上面这个样子。那上面的系统消息又是啥呢?我们来分析ackAndEnvelopeBuilder.build.toByteArray这段代码。首先来看build返回了什么。
public akka.remote.WireFormats.AckAndEnvelopeContainer build() {
akka.remote.WireFormats.AckAndEnvelopeContainer result = buildPartial();
if (!result.isInitialized()) {
throw newUninitializedMessageException(result);
}
return result;
}
它返回了一个AckAndEnvelopeContainer,那就可以再补充一下上面的图。

下面是AckAndEnvelopeContainer的继承关系。
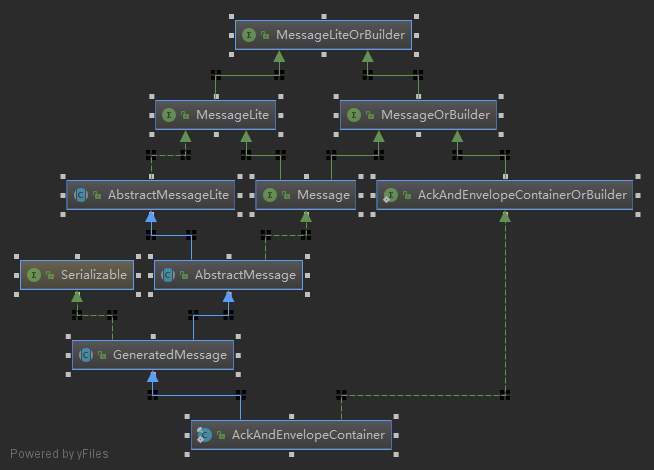
其实AckAndEnvelopeContainer内部还有其他的对象,但也不需要再过多深入分析,因为他们的序列化方法都是一样的。
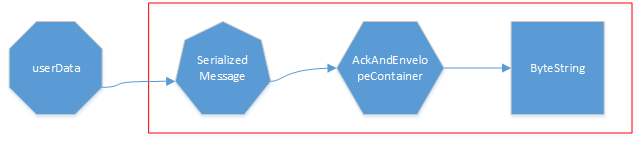
从上面红框开始,相关的序列化好像都是akka框架自定义的,那么它又是如何支持用户自定义序列化方法的呢?答案就在前面的serializeMessage方法中。
private def serializeMessage(msg: Any): SerializedMessage = handle match {
case Some(h) ⇒
Serialization.currentTransportInformation.withValue(Serialization.Information(h.localAddress, extendedSystem)) {
MessageSerializer.serialize(extendedSystem, msg.asInstanceOf[AnyRef])
}
case None ⇒
throw new EndpointException("Internal error: No handle was present during serialization of outbound message.")
}
很明显,最终调用了MessageSerializer.serialize把用户自定义消息转化成了SerializedMessage。那SerializedMessage是用来干啥的呢?其实直观上来说,它还是用来保存用户序列化后的数据的,跟前面的伎俩一样,把ByteString赋值给某个字段。目前猜测来看,的确是这样的,但又感觉那里不对。4
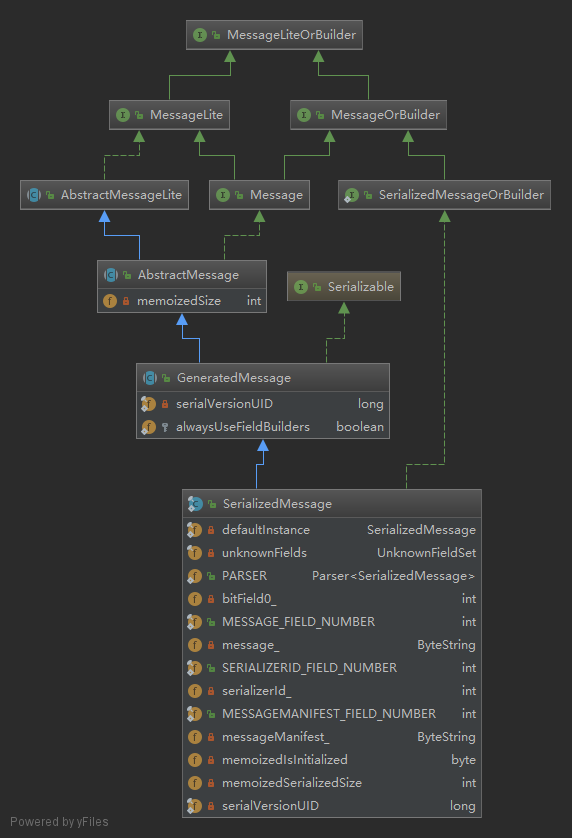
从SerializedMessage的继承关系和字段来看,好像确实是这样的。但需要注意这个类又两个ByteString的字段,分别是message_ 和 messageManifest_。一个是序列化后的消息,一个是序列化后消息的声明。
/**
* Uses Akka Serialization for the specified ActorSystem to transform the given message to a MessageProtocol
* Throws `NotSerializableException` if serializer was not configured for the message type.
* Throws `MessageSerializer.SerializationException` if exception was thrown from `toBinary` of the
* serializer.
*/
def serialize(system: ExtendedActorSystem, message: AnyRef): SerializedMessage = {
val s = SerializationExtension(system)
val serializer = s.findSerializerFor(message)
val builder = SerializedMessage.newBuilder
val oldInfo = Serialization.currentTransportInformation.value
try {
if (oldInfo eq null)
Serialization.currentTransportInformation.value = system.provider.serializationInformation
builder.setMessage(ByteString.copyFrom(serializer.toBinary(message)))
builder.setSerializerId(serializer.identifier)
val ms = Serializers.manifestFor(serializer, message)
if (ms.nonEmpty) builder.setMessageManifest(ByteString.copyFromUtf8(ms))
builder.build
} catch {
case NonFatal(e) ⇒
throw new SerializationException(s"Failed to serialize remote message [${message.getClass}] " +
s"using serializer [${serializer.getClass}].", e)
} finally Serialization.currentTransportInformation.value = oldInfo
}
这两个字段先忽略,先来看serialize这个方法。需要注意这段代码builder对象的三个set方法。它分别设置了序列化后的消息、消息的声明,还有一个是序列化器的identifier。
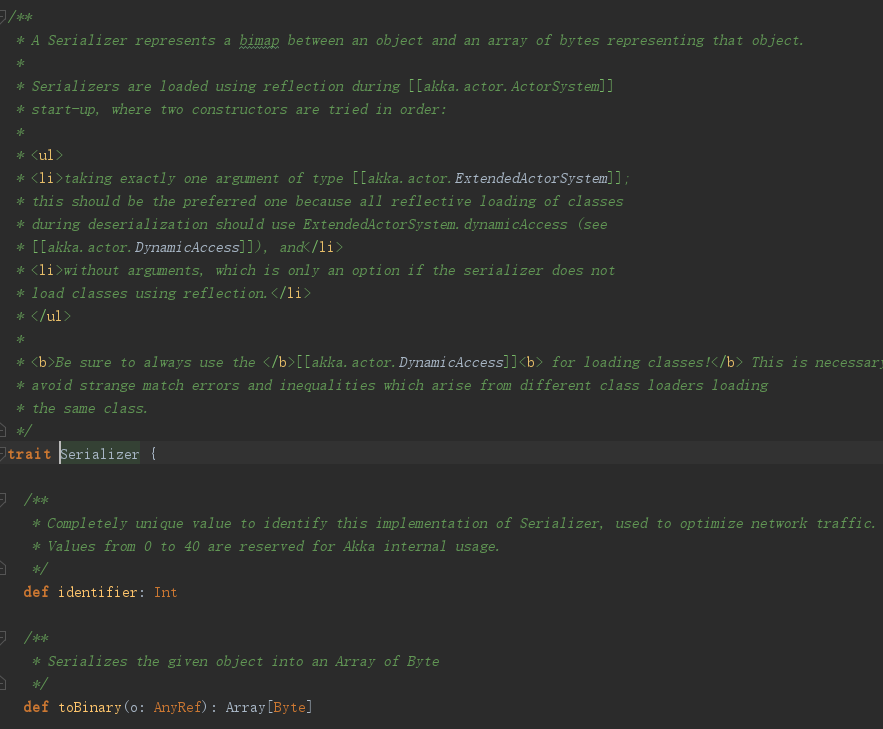
上面是Serializer的trait。抛开与序列化、反序列化相关的方法定义,第一个字段是一个identifier。从中文释义和官方注释来看,这是一个序列化器的数字标志,用以区分不同的序列化器。0~40是官方预留值,标志内部序列化用途,那为啥是40呢?你猜,哈哈哈,我也不知道,大概是官方觉得预留40个内部序列化器应该够用了吧。啥?如果不够用?鬼知道。
那为什么每个序列化器都需要一个identifier呢?后面再说吧。
/** * Returns whether this serializer needs a manifest in the fromBinary method */ def includeManifest: Boolean
其实Serializer还有一个非常重要的方法:includeManifest。它标志当前序列化器是否包含消息声明。那这个消息声明具体有啥用呢?
def manifestFor(s: Serializer, message: AnyRef): String = s match {
case s2: SerializerWithStringManifest ⇒ s2.manifest(message)
case _ ⇒ if (s.includeManifest) message.getClass.getName else ""
}
从获取消息声明的代码来看,它首先判断是否为SerializerWithStringManifest类型,如果是就调用manifest返回消息声明;否则就判断是否需要消息声明,如果需要则获取当前class的名称,否则返回空字符串。目前我们知道当前class的名称可以是消息的声明。那我们应该能大胆的猜测这个字段的意义了。
它是用来给反序列化提供相关的参数或信息的。因为序列化后的对象都是二进制数据,在接收端怎么知道该用哪个序列化器进行反序列化呢?如果有这部分二进制数据对应的类名,那就可以从配置里面查找到了!!!这有什么意义呢?其实我们在开发系统的时候,一般都非常具有针对性,或者说不会考虑通用性。比如会在系统设计阶段,使用固定的序列化器,比如kryo,或Hessian。这就意味着我们已经提前知道了该用哪种序列化框架,不需要进行选择。拿过来的数据,用对应的序列化器反序列化就好了,不用担心格式不兼容!!!所以一般是没有manifest的。所以我觉得manifest是通用序列化框架的关键。
其实SerializerWithStringManifest继承了Serializer,就是多提供了一个manifest方法。
/** * Return the manifest (type hint) that will be provided in the fromBinary method. * Use `""` if manifest is not needed. */ def manifest(o: AnyRef): String
就是返回给定消息的类型提示字符串。
那么在序列化之前是如何知道改用那个序列化器呢?答案就在SerializationExtension.findSerializerFor这个方法上。
/**
* Returns the Serializer configured for the given object, returns the NullSerializer if it's null.
*
* Throws akka.ConfigurationException if no `serialization-bindings` is configured for the
* class of the object.
*/
def findSerializerFor(o: AnyRef): Serializer =
if (o eq null) NullSerializer else serializerFor(o.getClass)
/**
* Returns the configured Serializer for the given Class. The configured Serializer
* is used if the configured class `isAssignableFrom` from the `clazz`, i.e.
* the configured class is a super class or implemented interface. In case of
* ambiguity it is primarily using the most specific configured class,
* and secondly the entry configured first.
*
* Throws java.io.NotSerializableException if no `serialization-bindings` is configured for the class.
*/
@throws(classOf[NotSerializableException])
def serializerFor(clazz: Class[_]): Serializer =
serializerMap.get(clazz) match {
case null ⇒ // bindings are ordered from most specific to least specific
def unique(possibilities: immutable.Seq[(Class[_], Serializer)]): Boolean =
possibilities.size == 1 ||
(possibilities forall (_._1 isAssignableFrom possibilities(0)._1)) ||
(possibilities forall (_._2 == possibilities(0)._2))
val ser = {
bindings.filter {
case (c, _) ⇒ c isAssignableFrom clazz
} match {
case immutable.Seq() ⇒
throw new NotSerializableException(s"No configured serialization-bindings for class [${clazz.getName}]")
case possibilities ⇒
if (unique(possibilities))
possibilities.head._2
else {
// give JavaSerializer lower priority if multiple serializers found
val possibilitiesWithoutJavaSerializer = possibilities.filter {
case (_, _: JavaSerializer) ⇒ false
case (_, _: DisabledJavaSerializer) ⇒ false
case _ ⇒ true
}
if (possibilitiesWithoutJavaSerializer.isEmpty) {
// shouldn't happen
throw new NotSerializableException(s"More than one JavaSerializer configured for class [${clazz.getName}]")
}
if (!unique(possibilitiesWithoutJavaSerializer)) {
_log.warning(LogMarker.Security, "Multiple serializers found for [{}], choosing first of: [{}]",
clazz.getName,
possibilitiesWithoutJavaSerializer.map { case (_, s) ⇒ s.getClass.getName }.mkString(", "))
}
possibilitiesWithoutJavaSerializer.head._2
}
}
}
serializerMap.putIfAbsent(clazz, ser) match {
case null ⇒
if (shouldWarnAboutJavaSerializer(clazz, ser)) {
_log.warning(LogMarker.Security, "Using the default Java serializer for class [{}] which is not recommended because of " +
"performance implications. Use another serializer or disable this warning using the setting " +
"'akka.actor.warn-about-java-serializer-usage'", clazz.getName)
}
log.debug("Using serializer [{}] for message [{}]", ser.getClass.getName, clazz.getName)
ser
case some ⇒ some
}
case ser ⇒ ser
}
简单来说这个方法就是从SerializationExtension这个扩展配置的序列化器中根据类的claz信息找到一个序列化器,如果找不到就招父类对应的序列化器,如果还找不到那就用Java默认的序列化器。
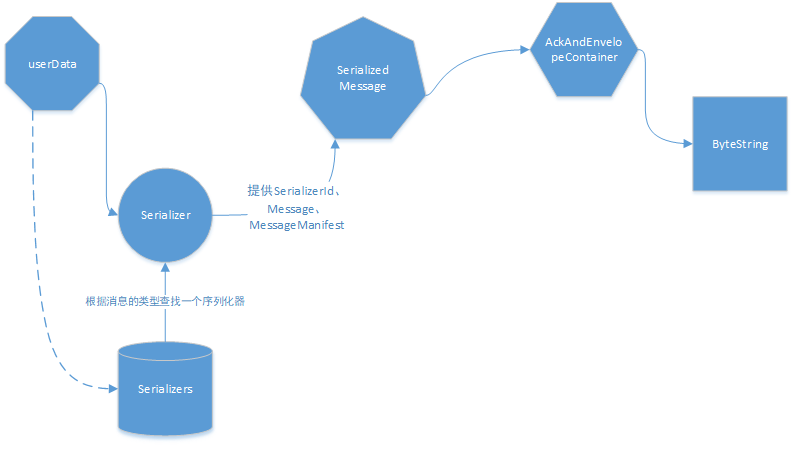
其实序列化的过程可以简单总结为上面这样的流程图。下面我们简要分析一下反序列化的过程。
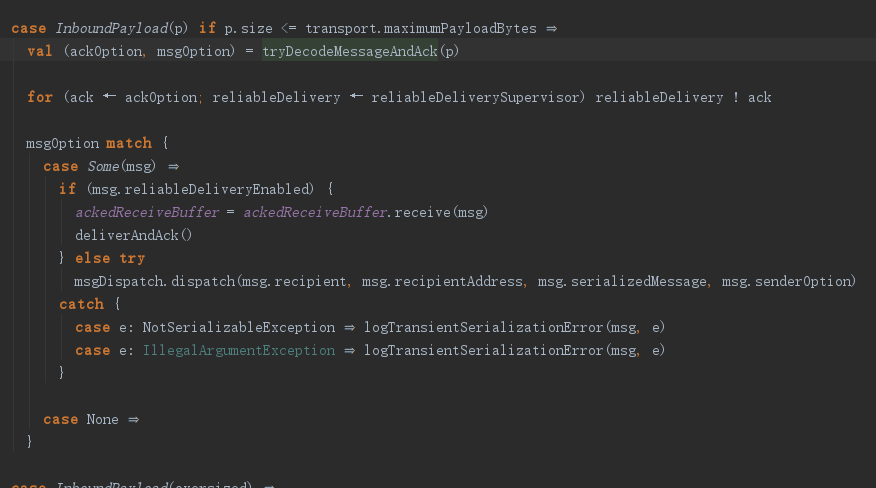
上面是收到消息时的处理过程,很显然调用了tryDecodeMessageAndAck方法。
private def tryDecodeMessageAndAck(pdu: ByteString): (Option[Ack], Option[Message]) = try {
codec.decodeMessage(pdu, provider, localAddress)
} catch {
case NonFatal(e) ⇒ throw new EndpointException("Error while decoding incoming Akka PDU", e)
}
这个方法输入是一个ByteString,返回一个Tuple,第二个类型是Message。
override def decodeMessage(
raw: ByteString,
provider: RemoteActorRefProvider,
localAddress: Address): (Option[Ack], Option[Message]) = {
val ackAndEnvelope = AckAndEnvelopeContainer.parseFrom(raw.toArray)
val ackOption = if (ackAndEnvelope.hasAck) {
import scala.collection.JavaConverters._
Some(Ack(SeqNo(ackAndEnvelope.getAck.getCumulativeAck), ackAndEnvelope.getAck.getNacksList.asScala.map(SeqNo(_)).toSet))
} else None
val messageOption = if (ackAndEnvelope.hasEnvelope) {
val msgPdu = ackAndEnvelope.getEnvelope
Some(Message(
recipient = provider.resolveActorRefWithLocalAddress(msgPdu.getRecipient.getPath, localAddress),
recipientAddress = AddressFromURIString(msgPdu.getRecipient.getPath),
serializedMessage = msgPdu.getMessage,
senderOption =
if (msgPdu.hasSender) OptionVal(provider.resolveActorRefWithLocalAddress(msgPdu.getSender.getPath, localAddress))
else OptionVal.None,
seqOption =
if (msgPdu.hasSeq) Some(SeqNo(msgPdu.getSeq)) else None))
} else None
(ackOption, messageOption)
}
上面是decodeMessage的源码,第一行是用来反序列化的。
public static akka.remote.WireFormats.AckAndEnvelopeContainer parseFrom(byte[] data)
throws akka.protobuf.InvalidProtocolBufferException {
return PARSER.parseFrom(data);
}
它返回一个AckAndEnvelopeContainer对象。怎么样这个类型是不是比较熟悉?没错,在序列化的过程中,用户消息的最终序列化数据传给了这个对象,然后序列化发送出去的。
后面的代码就是在解析AckAndEnvelopeContainer的其他字段了,比如Recipient/Sender/Seq等。其中我们最关心的是Message。还记得这个Message的类型是什么吗?没错就是SerializedMessage。
不过上面的代码并没有对用户消息进行反序列化,而是调用msgDispatch.dispatch(msg.recipient, msg.recipientAddress, msg.serializedMessage, msg.senderOption)对消息进行处理。
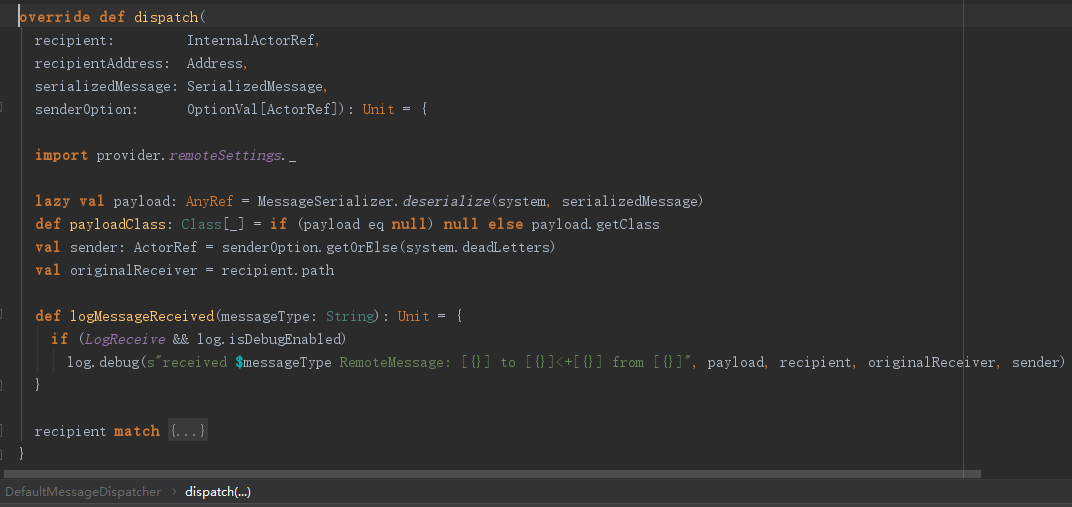
很显然,用户消息最终调用了MessageSerializer.deserialize进行反序列化。
/**
* Uses Akka Serialization for the specified ActorSystem to transform the given MessageProtocol to a message
*/
def deserialize(system: ExtendedActorSystem, messageProtocol: SerializedMessage): AnyRef = {
SerializationExtension(system).deserialize(
messageProtocol.getMessage.toByteArray,
messageProtocol.getSerializerId,
if (messageProtocol.hasMessageManifest) messageProtocol.getMessageManifest.toStringUtf8 else "").get
}
它还是通过SerializationExtension这个扩展来反序列化的。同样有三个参数:message,serializerID,Manifest。
/**
* Deserializes the given array of bytes using the specified serializer id,
* using the optional type hint to the Serializer.
* Returns either the resulting object or an Exception if one was thrown.
*/
def deserialize(bytes: Array[Byte], serializerId: Int, manifest: String): Try[AnyRef] =
Try {
val serializer = try getSerializerById(serializerId) catch {
case _: NoSuchElementException ⇒ throw new NotSerializableException(
s"Cannot find serializer with id [$serializerId]. The most probable reason is that the configuration entry " +
"akka.actor.serializers is not in synch between the two systems.")
}
deserializeByteArray(bytes, serializer, manifest)
}
首先根据serializerId找到本节点对应的序列化器,这意味着什么呢?这意味着所有的节点,相同的序列化器都必须具有相同的serializerId。这就是serializerId的意义。
private def deserializeByteArray(bytes: Array[Byte], serializer: Serializer, manifest: String): AnyRef = {
@tailrec def updateCache(cache: Map[String, Option[Class[_]]], key: String, value: Option[Class[_]]): Boolean = {
manifestCache.compareAndSet(cache, cache.updated(key, value)) ||
updateCache(manifestCache.get, key, value) // recursive, try again
}
withTransportInformation { () ⇒
serializer match {
case s2: SerializerWithStringManifest ⇒ s2.fromBinary(bytes, manifest)
case s1 ⇒
if (manifest == "")
s1.fromBinary(bytes, None)
else {
val cache = manifestCache.get
cache.get(manifest) match {
case Some(cachedClassManifest) ⇒ s1.fromBinary(bytes, cachedClassManifest)
case None ⇒
system.dynamicAccess.getClassFor[AnyRef](manifest) match {
case Success(classManifest) ⇒
val classManifestOption: Option[Class[_]] = Some(classManifest)
updateCache(cache, manifest, classManifestOption)
s1.fromBinary(bytes, classManifestOption)
case Failure(e) ⇒
throw new NotSerializableException(
s"Cannot find manifest class [$manifest] for serializer with id [${serializer.identifier}].")
}
}
}
}
}
}
很明显,首先判断Serializer是不是SerializerWithStringManifest,如果是就传入发送过来的manifest;如果不是且manifest是空字符串,则调用fromBinary时,第二个参数为空(也就是manifest);如果manifest不为空,则从manifestCache中找到对应的manifest信息,传入fromBinary;如果manifestCache没找到,则动态加载manifest信息,更新manifestCache后再传入fromBinary。
至此,反序列化过程结束。

上面是我们总结的akka的序列化框架。消息的序列化可以分为三层:用户消息、用户消息序列化后对应的SerializedMessage、SerializedMessage对应的AckAndEnvelopeContainer。其中AckAndEnvelopeContainer的序列化是系统提供的,用户无法自定义;SerializedMessage是系统序列化和用户自定义序列化的中间层,提供一个适配的功能,比如提供序列化器的ID以及消息的声明信息;用户消息是基础层,可以使用自定义序列化器进行序列化。在反序列化时先反序列化城AckAndEnvelopeContainer,进行一些系统级的操作,然后根据SerializedMessage的序列化器ID查找对应的序列化器,反序列化用户消息。至此一个通用的序列化、反序列化流程设计完毕,而且还很通用的额。其实简单来说就是,解耦了“变”和“不变”。“变”是指用户的序列化器可能不变通,而且支持自定义;“不变”是指系统级消息的序列化过程不变,所有节点都一样。
怎么样,你对akka设计的这个通用的序列化框架怎么看?是不是觉得挺好用的?我觉得这个分层设计的概念大家应该学会,这有助于我们照葫芦画瓢也设计一个类似的序列化框架。啥?你的序列化不需要通用?那你总会遇到schema变迁、升级的问题的。