1、虚拟机的组成部分及作用
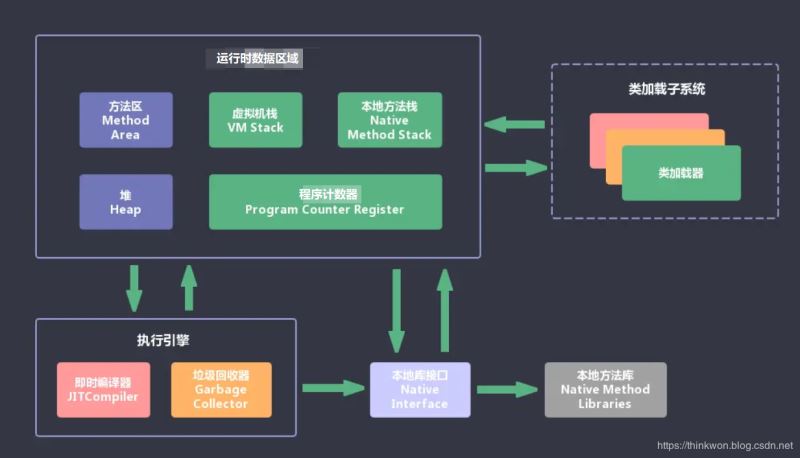
1.1、类加载器(ClassLoader)
根据给定的全限定类名加载Java代码,转化为字节码,传递给运行时数据内存区
1.2、运行时数据内存区(Runtime data area)
1.2.1、程序计数器(Program Counter Register)
* 线程私有
* 小块内容空间,不存在溢出情况
* 用来确定指令位置
1.2.2、虚拟机栈(VM Stack)
* 线程私有
* 描述的是Java方法执行的内存模型,方法的调用过程对应着入栈和出栈,栈中保存了局部变量、操作数栈、动态连接、方法出口等信息
* 虚拟机规范中指明了两种内存溢出的场景:超出栈的深度、可变长栈的最大可获取深度被超出
1.2.3、本地方法栈(Native Method Stack)
* 基本上与虚拟机栈一样,Hot-Spot虚拟机两者直接合二为一,这块的规范并无强制规定
* 与虚拟机栈不同的是,这边执行的是本地方法
1.2.4、Java堆(Heap)
* 最大的一块内存
* 线程共享
* 几乎存放对象实例、数组
* 垃圾收集器管理的就是这里,所以也叫GC堆
* 分代收集理论
* 没内存完成实例分配也没办法扩展的时候,内存溢出
1.2.5、方法区
* 线程共享
* 非堆
* 6含之前基本上是永久代的实现方式,后续到8后基本废弃永久代,改为本地内存实现(这里指的是Hot-Spot,因为JRockit和J9本来就是这么做的)
* 内存溢出和堆是一样的
1.2.5.1、运行时常量池
* 字面量和符号的引用
* 常规的是字符串常量池应用
1.2.6、直接内存,与这边的运行时数据内存无关,主要用于IO、NIO,也不受JVM限制,但受本地内存限制,也会有内存溢出
1.3、执行引擎
主要用于转化字节码为机器码,并执行指令
1.4、本地库接口
对接本地方法,比如调用C++语言的本地方法
2、双亲委派模式
指的是ClassLoader逐级往上的加载方式,简单来说,就是如果父类可以加载,就一直往上,可以解决的问题是:2个以上的类加载器会导致加载的类信息存在两个以上,会导致例如静态变量重复初始化的诡异场景
注:Spring Boot的DevTools带的热加载机制,大致也是通过两个ClassLoader的形式来执行,其中一个加载器,加载我们自己写的Java代码,这样可以通过重新加载这部分的类信息,做到热部署的效果。
3、常见的垃圾收集器
3.1、Serial收集器:1.3.1之前新生代收集器唯一选择。
串行单线程收集器,垃圾收集时候必须stop the world,暂停其他所有工作
新生代-复制算法,老年代:标记-整理算法
3.2、ParNew收集器:JDK7之前的首选新生代收集器
* Serial收集器的多线程并行版本
* -XX:ParalleGCThreads 限制垃圾收集线程数
* 1.7之后已经算是退出历史舞台了,G1垃圾收集器是面向全堆的
3.3、CMS(Concurrent Mark SWEEP):并发的低延迟收集器
* CPU敏感型,是老年代的收集器,默认与ParNew收集器共用
* 真正意义上第一台支持并发的牢记收集器
3.4、Parallel Scavenge:1.4新生代收集器,并无法和CMS一起使用
3.5、G1:Java7之后的主流垃圾收集器,在Java8之后相对比较成熟了,Java9之后作为默认的垃圾收集器选择(Oracle现在对Java版本的长期支持是隔三代,目前是8、11、14,记得应该是维护三年,由于Spring框架目前仅支持Java8,所以现在用的最多的应该是Java8)
* 面向全堆的垃圾收集器(不再是新生代一个收集器,老年代一个收集器)
* 废弃了永久代的实现,改为和j9和JRocket一样的元数据空间实现;
-XX:PermSize 和 -XX:MaxPermSize都将被忽略
-XX:MetaspaceSize 初始化元空间的大小(默认12Mbytes在32bit client VM and 16Mbytes 在32bit server VM,在64bit VM上会更大些)
-XX:MaxMetaspaceSize 最大元空间的大小(默认本地内存)
-XX:MinMetaspaceFreeRatio 扩大空间的最小比率,当GC后,内存占用超过这一比率,就会扩大空间
-XX:MaxMetaspaceFreeRatio 缩小空间的最小比率,当GC后,内存占用低于这一比率,就会缩小空间
* 由于官方倾向G1的完全替换,所以取消了ParNew+Serial Old以及Serial+CMS的支持,ParNew只能和CMS配合使用
| 新生代 | 老年代 | |
| Serial | 是 | 否 |
| Serial Old | 否 | 是 |
| ParNew | 是 | 否 |
| Parallel Old | 否 | 是 |
| Parallel Scavenge | 是 | 否 |
| CMS(Concurrent Mark Sweep) | 否 | 是 |
| G1(Garbage First) | 是 | 是 |
垃圾收集器对应新生代和老年代
| 目标|优点 | 缺点 | |
| Serial | 单线程,极限性能,一定程度上适用于微服务的架构 | 糟糕的Stop the World体验 |
| Serial Old | 同上 | 同上 |
| ParNew | Serial的多线程版本 | 单核性能不占优 |
| Parallel Scavenge | 以吞吐量为维度,旨在保证较高的吞吐量比例 | 用户体验(因侧重点在于有效利用CPU,会忽视响应速度的问题) |
| Parallel Old | 同上 | 同上 |
| CMS(Concurrent Mark Sweep) | 并发、低延迟,关注服务的响应速度 | 1、CPU敏感; 2、无法处理浮动垃圾导致Full GC,浮动垃圾大致是指在标记过程中会产生新的垃圾对象,这部分无法被识别,应是并发模式导致; 3、由于采用标记-清除算法,所以有内存碎片的问题,可能因此提前触发Full GC |
| G1(Garbage First) | 1、面向全堆,而不再只是新生代或老年代 2、软实时垃圾收集器目标 3、Mixed GC模式:不再区分新老年代,而是以回收哪块内存收益最大为维度(Region堆内存布局)- 堆内存化整为零 |
由于使用了Region内存布局,所以需要更多的堆内存来做卡表记录 |
4、常见的垃圾回收算法:
4.1、复制算法
- 常见于新生代,原来是1:1内存分配两块内存区,GC的时候通过将存活对象复制到另一块内存,然后清除旧的内存区
- 但实际上由于新生代对象的存活周期短,一般采用的8:1:1的 Eden(伊甸园):SurvivorRatio)(幸存者)*2;再通过老年代来做担保(因为使用的内存是8+1,存活的内存可能大于1,所以需要老年代来做保证有地方放溢出的存活对象)
4.2、标记-清除算法
- 常见于老年代,通过标记存活对象,来确定要GC的对象
- 缺点是:内存碎片,且由于内存碎片的存在可能导致提前Full GC
4.3、标记-整理算法
- 常见于老年代,也用于G1中Region;通过将存活的内存整理到同一个区域;再将边界之外的内存进行清理
- 缺点是:必须要移动内存
5、三项垃圾收集器的重要指标
- 内存占用(Footprint)
- 吞吐量(Throughput)
- 延迟(Latency)
6、Minor GC(新生代)、Major GC(老年代)、Full GC(全代)