1.图:.在计算机程序设计中,图是最常用的数据结构之一。对于存储一般的数据问题,一般用不到图。但对于某些(特别是一些有趣的问题),图是必不可少的。图是一种与树有些相像的数据结构,从数学意义上来讲,树是图的一种。而在计算机程序设计中,图的应用方式与树不同。图通常有一个固定的形状,这是由物理或抽象的问题所决定的。例如图中节点表示城市,而边可能表示城市间的班机航线。当讨论图时,节点通常叫做顶点,
2.一些概念:
图: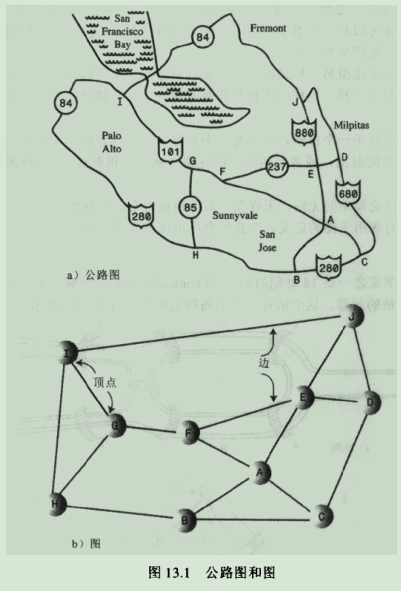
说明:为引入概念,我们用图13.1a来表示美国某处的简化高速公路网,图13.1b来表示模拟这些告诉公路的图。在图中,圆圈代表高速公路的交汇点,连接圆圈的直线代表告诉公路段,圆圈是顶点,线是边。顶点通常用一些方法来标识----正如图中表示的那样,用字母表中的字母来表示。每条边由两个顶点作为两边。图并不是要试图反映地图上的地理位置。它只是反映了顶点和边的关系----即那些边连接着哪些顶点。它本身不涉及物理的远近和方向。而且一条边可能表示几条可能的公路。两个交叉点之间的连通性(或不连通性)是重要的,而实际的路线并不重要。
a.邻接:如果两个顶点被同一条边连接,就称这两个顶点是邻接的。图13.1中,顶点I 和G是邻接的,但I 和 F 就不是。和某个指定顶点邻接的顶点有时叫它的邻居。如G 的邻居是I,H和F.
b.路径:路径是边的序列,图13.1显示了一条从顶点B到顶点J的路径,这条路径通过了A,E,这条路径称作BAEJ。这两个顶点之间还有其他路径,如BCDJ.
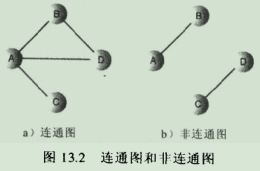
c.连通图:如果至少有一条路径,可以连接起所有的顶点,那么这个图被称作连通的,如图13.2a。如果不能从这里到那里,那么这个图就是非连通的。如13.2b。非连通图包含几个连通子图。在图13.2b中,A和B是一个连通子图,C和D也是一个连通子图。
d.有向图和带权图:图13.1和图13.2中的图是无向图,这说明图中的边没有方向----可以从任意一边到另为一边。所以可以从顶点A到顶点B,或者从顶点B到顶点A。两者是等价的(无向图很好的反映了高速公路网,因为在一条公路上可以按两个方向行驶),然而图还经常被用来模拟另一种情况,即只能沿着边向一个方向行驶。这样的图被称作是有向的。允许移动的方向通常是用一端带有箭头的方向表示。在某些图中,边被赋予一个权值,权值是一个数字,他能代表两个顶点间的物理距离,或从一个顶点到另一个顶点的时间,或者是两点间的花费(如飞机航班),这样的图称为带权图。
3.程序中如何表示图:
3.1.顶点:在非常抽象的图的问题中,知识简单的把顶点编号,从0->n-1,不需要任何变量类型来存储顶点,因为他们的用处来自于他们之间的相互关系,但大多数情况下,顶点表示某个真实世界的对象。顶点对象能放在数组中,然后用下标指示。
3.2.边:图并不像树,拥有几种固定的结构,二叉树中顶点最多有两个子节点,但图的每个顶点可以与任意多个顶点相连。为此,一般用两个方法表示图,邻接矩阵和邻接表。(如果一条边连接两个顶点,那么这两个顶点就是邻接的)
3.2.1.邻接矩阵:它是一个二维数组,数据项表示两点间是否存在边,如果图有N个顶点,邻接矩阵就是N * N 的数组。表13.1显示了图13.1a中图的邻接矩阵。
图: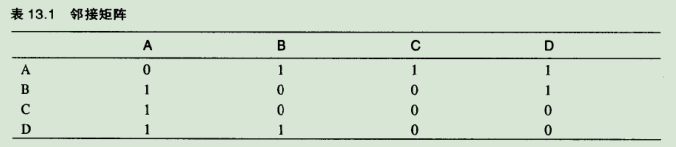
说明:顶点被用作行和列的标题,这两个顶点间右边则标识为1,无边则标识为0.(也可用boolean值表示),如图所示,顶点A 和另为3个顶点邻接,B和A,D邻接,C只与A邻接。而D与A和B邻接。从A-A到D-D称为主对角线,顶点和自身的连接设为0。也可设为1.
3.2.2.邻接表:表指的是链表,实际上,邻接表是一个链表数组。每个单独的链表表示了有哪些顶点和当前顶点邻接。表13.2显示了13.2a中图的邻接表。
图:
说明:本表中符号-->表示链表中的一个节点,链表中每个节点都是一个顶点,链表中的每个节点都是一个顶点,在这里的每个链表中,顶点按字母顺序排列,不过这并不是必须的。不要把邻接表的内容与路径混淆,邻接表表示了当前节点与那些节点相连------即,两个节点间存在边,而不是表示顶点间的路径。
4.图的搜素:图中实现的最基本的操作之一就是搜索从一个指定顶点可以到达那些顶点。有两种常用的方法来搜索树,深度优先搜索(DFS)和广度优先搜索(BFS),他们最终都会到达所有连通的顶点,深度优先搜索通过栈来实现,而广度优先搜索通过队列来实现。
4.1.深度优先搜索:找到一个起始点---本例为顶点A,需要做三件事情,首先访问该节点,然后把该点放入栈中,以便记住它,最后标记该点,这样就不会再访问它了。
4.1.1.图解: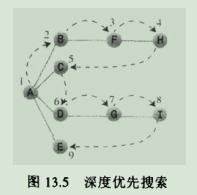
4.1.2.主要规则:
4.1.2.1.规则1:如果可能,访问一个邻接的未访问顶点,标记它,并把他放入栈中。
4.1.2.2.规则2:当不能执行规则1时,如果栈非空,就从栈中弹出一个顶点。
4.1.2.3.规则3:如果不能执行规则1和规则2,就完成了整个搜索过程。
4.2.广度优先搜索:首先访问起始顶点的所有邻接点,然后再访问较远的区域,用队列来实现它。(A是起始点,所以访问它,并标记为当前顶点,然后应用规则)
4.2.1图解: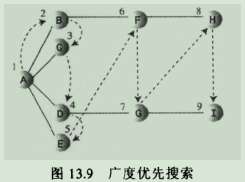
4.2.2.主要规则:
4.2.2.1.规则1:访问下一个问来访问的邻接点(如果存在),这个顶点必须是当前顶点的邻接点,标记它,并把它插入到队列中。
4.2.2.2.规则2:如果因为已经没有未访问顶点而不能执行规则1,那么从队列头取一个顶点(如果存在),并使其成为当前顶点。
4.2.2.3.规则3:如果因为队列为空而不能执行规则2,则搜索结束。
5.深度优先搜索实现:
5.1.StackX.java


1 package com.cn.graph; 2 /** 3 * 图的深度优先搜索底层---栈类 4 * @author Administrator 5 * 6 */ 7 public class StackX { 8 private final int SIZE = 20; 9 private int[] st; 10 private int top; 11 public StackX(){ 12 st = new int[SIZE]; 13 top = -1; 14 } 15 public void push(int j){ 16 st[++ top] = j; 17 } 18 public int pop(){ 19 return st[top --]; 20 } 21 public int peek(){ 22 return st[top]; 23 } 24 public boolean isEmpty(){ 25 return top == -1; 26 } 27 }
5.2.Vertex.java
1 package com.cn.graph; 2 /** 3 * 图的顶点类 4 * @author Administrator 5 * 6 */ 7 public class Vertex { 8 public char lable; 9 public boolean wasvisited; 10 public Vertex(char lab){ 11 lable = lab; 12 wasvisited = false; 13 } 14 }
5.3.Graph.java
1 package com.cn.graph; 2 /** 3 * 深度优先实现的图 4 * @author Administrator 5 * 6 */ 7 public class Graph { 8 private final int MAX_VERTS = 20; 9 private Vertex[] vertexList; 10 private int adjMat[][]; 11 public int nVerts; 12 private StackX theStack; 13 public Graph(){ 14 vertexList = new Vertex[MAX_VERTS]; 15 adjMat = new int[MAX_VERTS][MAX_VERTS]; 16 nVerts = 0; 17 for (int i = 0; i < MAX_VERTS; i++) { 18 for (int j = 0; j < MAX_VERTS; j++) { 19 adjMat[i][j] = 0; 20 } 21 } 22 theStack = new StackX(); 23 } 24 public void addVertex(char lab){ 25 vertexList[nVerts ++] = new Vertex(lab); 26 } 27 public void addEdage(int start,int end){ 28 adjMat[start][end] = 1; 29 adjMat[end][start] = 1; 30 } 31 public void displayVertex(int v){ 32 System.out.print(vertexList[v].lable+" "); 33 } 34 public void dfs(){ 35 vertexList[0].wasvisited = true; 36 displayVertex(0); 37 theStack.push(0); 38 while (! theStack.isEmpty()){ 39 int v = getAdjUnvisitedVertex(theStack.peek()); 40 if (v == -1) 41 theStack.pop(); 42 else{ 43 vertexList[v].wasvisited = true; 44 displayVertex(v); 45 theStack.push(v); 46 } 47 } 48 for (int i = 0; i < nVerts; i++) 49 vertexList[i].wasvisited = false; 50 } 51 public int getAdjUnvisitedVertex(int v){ 52 for (int i = 0; i < nVerts; i++) 53 if (adjMat[v][i] == 1 && vertexList[i].wasvisited == false) 54 return i; 55 return -1; 56 } 57 }
5.4.GTest.java
1 package com.cn.graph; 2 /** 3 * 深度优先搜索测试类 4 * @author Administrator 5 * 6 */ 7 public class GTest { 8 public static void main(String[] args) { 9 Graph g = new Graph(); 10 g.addVertex('A'); 11 g.addVertex('B'); 12 g.addVertex('C'); 13 g.addVertex('D'); 14 g.addEdage(0, 1); 15 g.addEdage(2, 1); 16 g.addEdage(2, 3); 17 // g.displayVertex(0); 18 g.dfs(); 19 } 20 }
6.广度优先搜索实现:
6.1.Queue.java
1 package com.cn.graph; 2 /** 3 * 图的广度优先搜索---队列类 4 * @author Administrator 5 * 6 */ 7 public class Queue { 8 private final int SIZE = 20; 9 private int queueArray[]; 10 private int front; 11 private int rear; 12 public Queue(){ 13 queueArray = new int[SIZE]; 14 front = 0; 15 rear = -1; 16 } 17 public void insert(int j){ 18 if (rear == SIZE - 1) 19 rear = -1; 20 queueArray[++ rear] = j; 21 } 22 public int remove(){ 23 int temp = queueArray[front ++]; 24 if (front == SIZE) 25 front = 0; 26 return temp; 27 } 28 public boolean isEmpty(){ 29 return (rear + 1 == front || front + SIZE - 1 == rear); 30 } 31 }
6.2.Vertex.java
1 package com.cn.graph; 2 /** 3 * 图的顶点类 4 * @author Administrator 5 * 6 */ 7 public class Vertex { 8 public char lable; 9 public boolean wasvisited; 10 public Vertex(char lab){ 11 lable = lab; 12 wasvisited = false; 13 } 14 }
6.3.QGraph.java
1 package com.cn.graph; 2 /** 3 * 广度优先搜索----队列实现 4 * @author Administrator 5 * 6 */ 7 public class QGraph { 8 final int MAX_VERTS = 20; 9 private Vertex[] vertexList; 10 private int adjMat[][]; 11 public int nVerts; 12 private Queue thequeue; 13 public QGraph(){ 14 vertexList = new Vertex[MAX_VERTS]; 15 adjMat = new int[MAX_VERTS][MAX_VERTS]; 16 nVerts = 0; 17 for (int i = 0; i < MAX_VERTS; i++) 18 for (int j = 0; j < MAX_VERTS; j++) 19 adjMat[i][j] = 0; 20 thequeue = new Queue(); 21 } 22 public void addVertex(char lab){ 23 vertexList[nVerts ++] = new Vertex(lab); 24 } 25 public void addEdage(int start,int end){ 26 adjMat[start][end] = 1; 27 adjMat[end][start] = 1; 28 } 29 public void displayVertex(int v){ 30 System.out.print(vertexList[v].lable+" "); 31 } 32 public void bfs(){ 33 vertexList[0].wasvisited = true; 34 displayVertex(0); 35 thequeue.insert(0); 36 int v2; 37 while (! thequeue.isEmpty()){ 38 int v = thequeue.remove(); 39 while ((v2 = getAdjUnvisitedVertex(v)) != -1){ 40 vertexList[v2].wasvisited = true; 41 displayVertex(v2); 42 thequeue.insert(v2); 43 } 44 } 45 for (int i = 0; i < nVerts; i++) 46 vertexList[i].wasvisited = false; 47 } 48 public int getAdjUnvisitedVertex(int v){ 49 for (int i = 0; i < nVerts; i++) 50 if (adjMat[v][i] == 1 && vertexList[i].wasvisited == false) 51 return i; 52 return -1; 53 } 54 55 }
6.4.QGTest.java
1 package com.cn.graph; 2 /** 3 * 广度优先搜索实现 4 * @author Administrator 5 * 6 */ 7 public class QGTest { 8 public static void main(String[] args) { 9 QGraph q = new QGraph(); 10 q.addVertex('a'); 11 q.addVertex('b'); 12 q.addVertex('c'); 13 q.addVertex('d'); 14 q.addEdage(0, 1); 15 q.addEdage(2, 1); 16 q.addEdage(0, 3); 17 q.bfs(); 18 19 } 20 21 }
7.最小生成树(MST):最小生成树边E的数量总比顶点V 的数量小1。E = V - 1;
8.深度优先实现MST的核心代码:
Graph + .
1 public void mst(){ 2 vertexList[0].wasvisited = true; 3 theStack.push(0); 4 while (! theStack.isEmpty()){ 5 int currentVertex = theStack.peek(); 6 int v = getAdjUnvisitedVertex(currentVertex); 7 if (v == -1) 8 theStack.pop(); 9 else{ 10 vertexList[v].wasvisited = true; 11 theStack.push(v); 12 displayVertex(currentVertex); 13 displayVertex(v); 14 System.out.print(" "); 15 } 16 } 17 for (int i = 0; i < nVerts; i++) { 18 vertexList[i].wasvisited = false; 19 } 20 }
9.有向图的应用场景案例:
9.1.场景图示: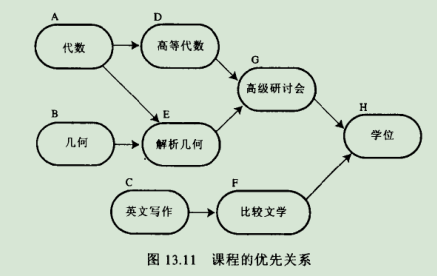
9.1.1.有向图: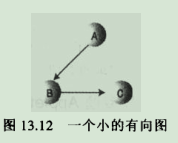
9.1.2.图13.12对应的邻接矩阵: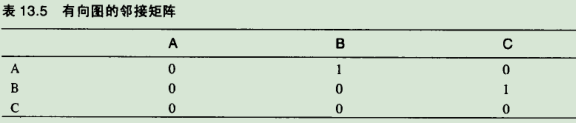
9.1.3.拓扑排序:假设存在一个课程列表,包含了要得到学位必修的所有课程,就像图13.11所示的课程一样,下面按照课程的先后关系排列它们。得到学位是列表的最后一项,这就得到BAEDGCFH的序列。这种方式的排列叫做为图进行拓扑排序。同样,CFBAEDGH也满足优先关系。当使用算法生成一个拓扑序列时,使用的方法和代码细节决定了生成那种拓扑序列。
9.1.4.拓扑排序算法的核心步骤:a.找到一个没有后继的节点。b.从图中删除这个顶点,在列表的前面插入顶点的标记。重复步骤a,b 直到所有顶点都从图中删除。这时列表显示的顶点顺序就是拓扑排序结果。拓扑排序可以用于连通图也可以用于非连通图。
10.wallshall算法:需要很快找到是否一个顶点可以从其他顶点到达。可以构建一个表,这个表以O(1)的时间复杂度告知一个顶点到另一个顶点是否可达,这样的表可以通过修改图的邻接矩阵实现。wallshall算法的核心思想:如果能从顶点L到达M,并且能从顶点M到达N,那么可以从L 到 N.