作业一:
1)UniversitiesRanking实验:
import requests
from bs4 import BeautifulSoup
t = requests.get("http://www.shanghairanking.cn/rankings/bcur/2020")
t.encoding = 'utf-8' # 以'utf-8'编码
soup = BeautifulSoup(t.text, "html.parser")
print("{0:^4}{1:{5}^16}{2:^6}{3:^8}{4:^9}".format('排名', '学校名称', '省份', '学校类型', '总分',
chr(12288)))
# chr(12288):中文空格,{x:^6}:参数x在6个长度中居中对齐,最长的学校名长度为13,于是设置第二项长度为16
for i in soup.find("tbody").children: # 查找tbody的下一级子节点
line = i.find_all(
"td")
'''i是标签,为网页中表格的一行,line是查找到该行的所有单元格,line[0]为排名,line[1]为学校名称,line[2]为省份,
line[3]为学校类型,line[4]为总分'''
print("{0:^6}{1:{5}^16}{2:^6}{3:^8}{4:^9}".format(line[0].text.strip(), line[1].text.strip(),
line[2].text.strip(), line[3].text.strip(),
line[4].text.strip(), chr(12288)))
学校排名的表格在tbody标签中

...


2)心得体会:
本次实验中体会对html的编码读取,beautifulsoup中对html的节点查找,以及对html子节点的相关操作,注意网页节点规划的特点,在本次实验中,排名表格的内容都在tbody下,整个网页也只有一个tbody标签,因此遍历tbody下的内容,对其包含的表格进行读取并print出来
作业二:
1)GoodPrice实验:
import re
import requests
import bs4
def get_html(url):
# 使用自己的cookie模仿个人访问网站
a = {
'cookie': 'hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; '
'enc=OKoR22O6wnUkrK%2B2KQ85C6uN921B3BjCy2jM7rIAgmfDNt0Y8CZjNGdYoCGbAA9yDJfCdlOXksVX6XrxFXc3Ag%3D%3D'
'; t=57dff2bbd10073249db2a33942981f45; _m_h5_tk=f16cdb464113f733659a47165e532890_1600609442057; '
'_m_h5_tk_enc=d5b5c5ec9fc4d4d54957007ec52215bb; cookie2=2a39cc31318294aa2c2df033a22542db; '
'_tb_token_=eb33e5fe5eede; xlly_s=1; _samesite_flag_=true; alitrackid=www.taobao.com; '
'lastalitrackid=www.taobao.com; mt=ci=0_0; JSESSIONID=6CCF0A80A9AF49EAF03D3A83B5C6CE4E; '
'cna=H/+XF0R3j2MCAXAx1E/hmp3S; '
'l=eBPpMlD4OLJ3gBcoBO5ahurza77TqQdffsPzaNbMiInca6KPTFg1uNQ4qDZ97dtjgt5bShtrb3kJjReXPqaU'
'-K1Hrt7APlUOrbvpJe1..; isg=BC4udjUl_X5-hgnsmUYtSOhAf4TwL_IpUz-lxVj0VDHsO8mV1LtsOAM586fX4-pB; '
'tfstk=clX1BAtOXV01A3NqQGZeuwEY8jvcZCmWc5TGf1_MZQus1OI1igHyPHoGiqHpwH1..; '
'sgcookie'
'=E100pz0cuVRkvVWabrl7HUvaJqbCXdomMEEfdcT1OntyWxRSKwvQRYISESfvxrHyGkFCYGTwjLec2vzfzDN2zOYjHA%3D%3D; '
'unb=2708419240; uc1=existShop=false&cookie14=Uoe0bU5UsGiZVQ%3D%3D&cookie15=WqG3DMC9VAQiUQ%3D%3D'
'&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D&pas=0&cookie21=VT5L2FSpccLuJBreK%2BBd; '
'uc3=lg2=W5iHLLyFOGW7aA%3D%3D&id2=UU8INKoJ6JFAjw%3D%3D&nk2=CdC%2F4kd9RFo%3D&vt3=F8dCufeJMxET3BlgYEE'
'%3D; csg=4deab7b1; lgc=jchxchhh; cookie17=UU8INKoJ6JFAjw%3D%3D; dnk=jchxchhh; '
'skt=5c3397abba15da67; existShop=MTYwMDYwNDkwMg%3D%3D; '
'uc4=nk4=0%40C%2B8F3HpVSiLdC4JSbXQh9mqW9A%3D%3D&id4=0%40U22PEY5jIHEY3Ju8b5OmbkYXErKM; '
'tracknick=jchxchhh; _cc_=W5iHLLyFfA%3D%3D; _l_g_=Ug%3D%3D; sg=h0d; _nk_=jchxchhh; '
'cookie1=BxuR43Et4NErOE2h%2F3c%2F4Cr5mTfpzhK18%2FNI%2FUtmJcw%3D',
'user-agent': 'Mozilla/5,0'}
try:
t = requests.get(url, headers=a)
t.encoding = 'utf-8'
return t.text
except:
print("网站访问失败")
def get_info(html):
try:
s = []
price_list = re.findall(r'"view_price":"[d.]*"', html) # 在html文本中匹配价格的正则
good_list = re.findall(r'"raw_title":".*?"', html) # 在html文本中匹配商品名的所有字符
for i in range(len(price_list)):
price = eval(price_list[i].split(":")[1]) # 去除冒号后字符串分隔为两个,选择后面项的值
good = eval(good_list[i].split(":")[1])
s.append([price, good])
return s
except:
print("获取商品信息失败")
return ""
def print_good(good):
print(" {0:^4}{1:^8} {2:^32}".format('序号', '价格', '商品名'))
count = 1
for a in good:
print(" {0:{3}^4}{1:{3}^8} {2:{3}^32}".format(count, a[0], a[1],chr(12288)))
count = count + 1
keyword='辣条'#检索的关键词
url = 'https://s.taobao.com/search?spm=a21bo.2017.201867-links-7.2.5af911d9sRcfoN&q='+keyword
html = get_html(url)
good = get_info(html)
print_good(good)
商品,价格字段:

cookie查看:


2)心得体会:
本次作业在尝试多次爬取时会只返回空值,询问同学后找到了解决办法,利用自己的cookie访问,来模仿个人游览网页。本次实验主要在商品和价格的正则查找,同时额外补充匹配任意字符的正则方法用来匹配双引号中商品名称。
作业二:
1)JPG实验:
import requests
import urllib
import re
from bs4 import BeautifulSoup
res = requests.get('http://xcb.fzu.edu.cn/')
soup = BeautifulSoup(res.text, 'html.parser')
s = []
it_list = re.findall(r'src="(.*?.jpg)"', str(soup))#正则匹配jpg格式的图片,括号内为返回的内容
print(it_list)#图片地址打印
for it in it_list:
if it[0] == '/':
it = 'http://xcb.fzu.edu.cn' + it#对网页本地服务器索引的图片添加该网址
s.append(it)
s1 = set(s)
for url in s1:
r = requests.get(url)
with open('./picture/' + url.rsplit('/', 1)[-1], 'wb') as f:#url.rsplit('/', 1)[-1]返回网址的最后一级内容
f.write(r.content)
print("成功下载:" + url.rsplit('/', 1)[-1])
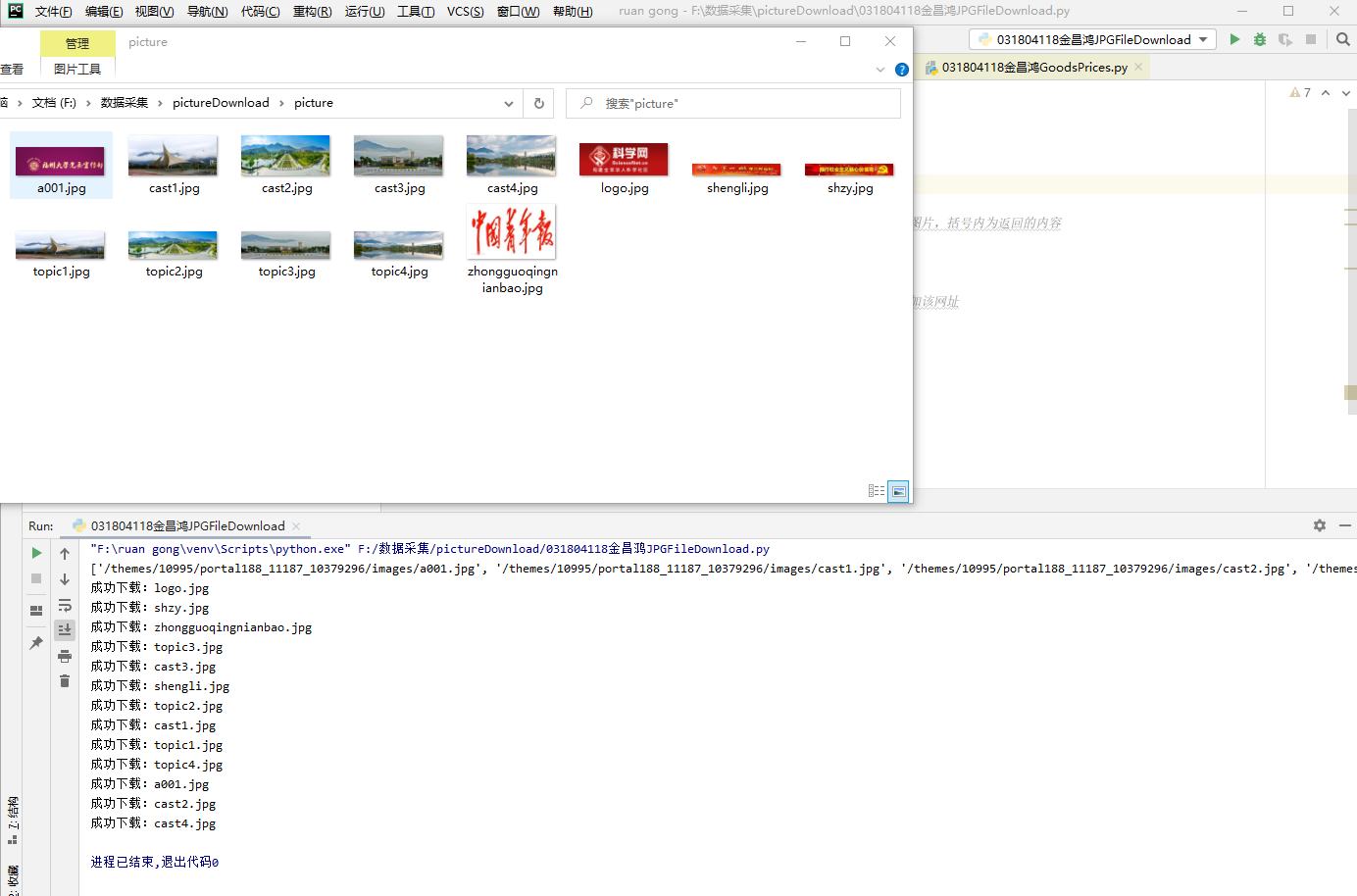
2)心得体会:
本次实验要求下载JPG格式的图片,而jpg图片的地址在标签中,因此直接将爬取到的源码信息转化为文本,对文本进行正则匹配,同时注意到部分重复的图片地址,对爬取到的网址放入set集合中去除重复内容。同时有一些图片网址是对原网站进行检索获取的,需要对其网址补充,最后通过这些图片的链接地址进行下载。