(本博文参考了JustNo、小菜鸟成长之路和Thewillman的博文:博客01 ;博客02;博客03 )
1. Iris数据集已与常见的机器学习工具集成,请查阅资料找出MATLAB平台或Python平台加载内置Iris数据集方法,并简要描述该数据集结构。
通过下载数据集可以看出,数据集共150行,数据结构可以看出是一个字典结构:
{
DESCR:...
data:... #数据有四个维度,即四个特征
feature_name:... #四个维度的含义
target:... #分类后的标签,用数值代替,做聚类时可以假设标签未知,然后用聚类后的结果与此比较,评判模型是否优秀。
target_name:... #数值分类后的标签的含义
}
核心代码如下:
from sklearn import datasets
import seaborn as sns
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from scipy.stats import multivariate_normal as gaussian_cal
Iris = datasets.load_iris()
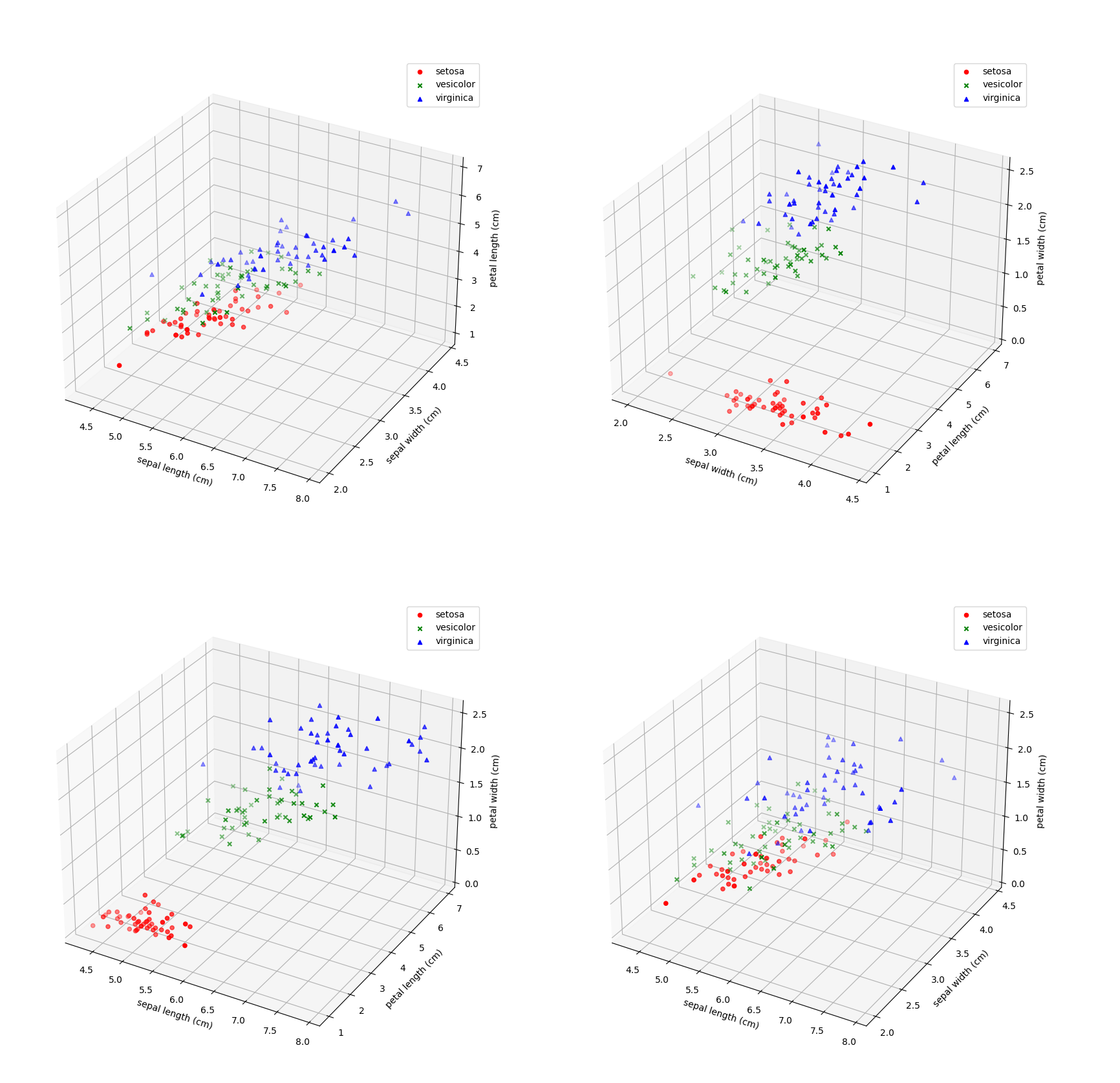
2. Iris数据集中有一个种类与另外两个类是线性可分的,其余两个类是线性不可分的。请你通过数据可视化的方法找出该线性可分类并给出判断依据。
很明显可以发现三种鸢尾花的花萼片是不一样的,先依据花萼片对其进行分类如下:
其中紫色代表setosa,相对比较特征区别更加明显,所以初步判定setosa是可以与另外两类线性可分的。

核心代码为:
def kz(iris_1, iris_2, iris_3):
m = 0
for i in range(10):
iris1_train, iris1_test = split(iris_1, i)
iris2_train, iris2_test = split(iris_2, i)
iris3_train, iris3_test = split(iris_3, i)
x, y = feature(iris_1, iris_2, iris_3)
p1_11, p2_11, p3_11, p1_10, p2_10, p3_10, p1_01, p2_01, p3_01, p1_00, p2_00, p3_00 = train(iris1_train,iris2_train,iris3_train, x, y)
n = test(iris1_test, iris2_test, iris3_test, x, y, p1_11, p2_11, p3_11, p1_10, p2_10, p3_10, p1_01, p2_01,p3_01, p1_00, p2_00, p3_00)
m = m + n
m = m / 10
p = m / 30
return p
iris_1 = iris.data[0:50, :]
iris_2 = iris.data[50:100, :]
iris_3 = iris.data[100:150, :]
p = kz(iris_1, iris_2, iris_3)
print(p)
另外可以通过具体的3D数据可视化呈现如下:可以明显看出setosa相较于versicolor,virgincia是可以线性可分的。
核心代码实现:
from sklearn import datasets
from matplotlib import pyplot as plt
def not_alike(data,iris_type):
xx = [[0, 1, 2], [1, 2, 3], [0, 2, 3], [0, 1, 3]]
fig = plt.figure(figsize=(20, 20))
feature = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
for i in range(4):
ax = fig.add_subplot(221 + i, projection="3d")
ax.scatter(data[iris_type == 0, xx[i][0]], data[iris_type == 0, xx[i][1]], data[iris_type == 0, xx[i][2]],
c='r', marker='o', label='setosa')
ax.scatter(data[iris_type == 1, xx[i][0]], data[iris_type == 1, xx[i][1]], data[iris_type == 1, xx[i][2]],
c='g', marker='x',
label='vesicolor')
ax.scatter(data[iris_type == 2, xx[i][0]], data[iris_type == 2, xx[i][1]], data[iris_type == 2, xx[i][2]],
c='b', marker='^',
label='virginica')
yy = [feature[xx[i][2]],feature[xx[i][0]],feature[xx[i][1]]]
ax.set_zlabel(yy[0])
ax.set_xlabel(yy[1])
ax.set_ylabel(yy[2])
plt.legend(loc=0)
plt.show()
if __name__ == "__main__":
not_alike(data, iris_type)
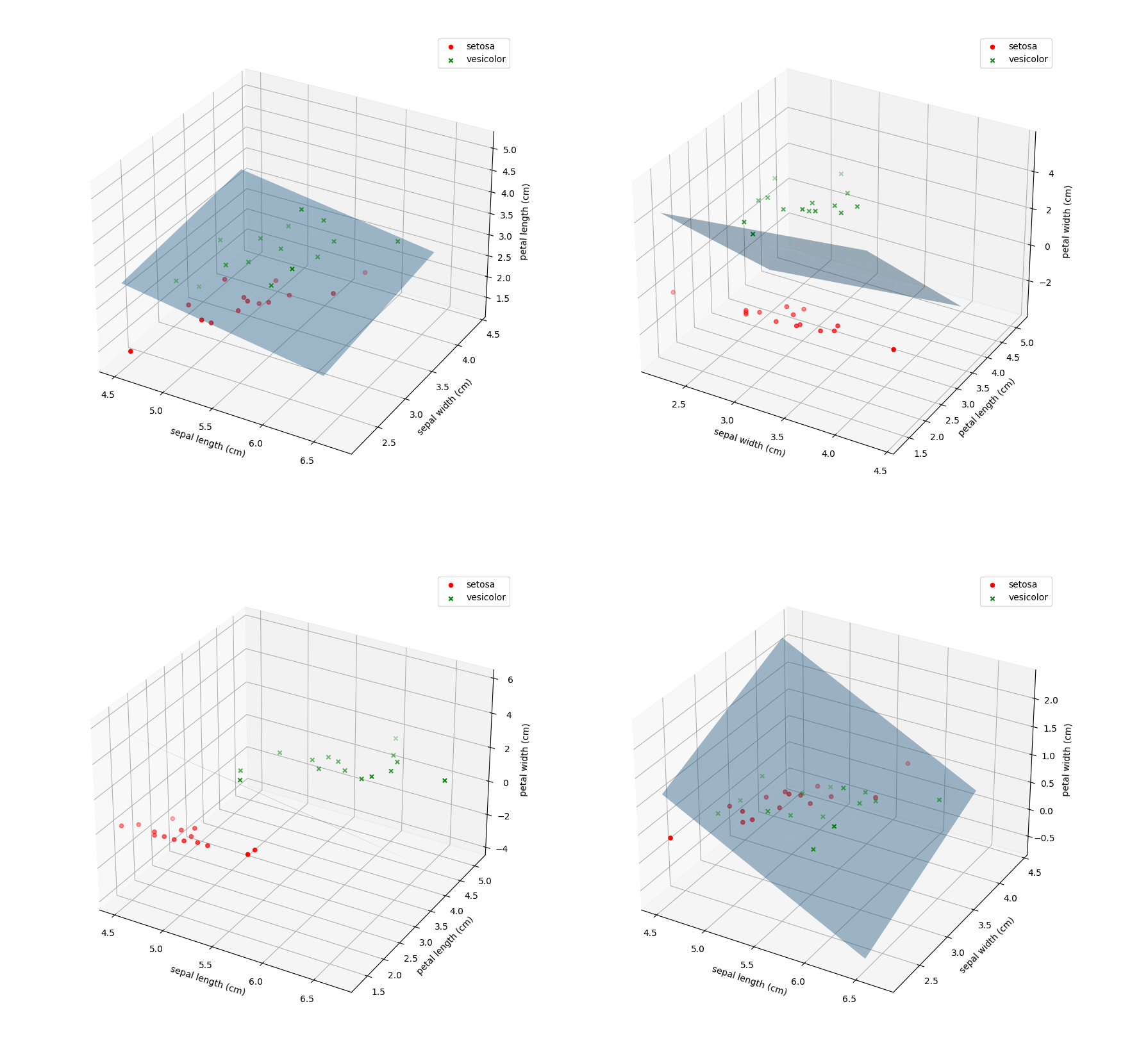
3. 去除Iris数据集中线性不可分的类中最后一个,余下的两个线性可分的类构成的数据集命令为Iris_linear,请使用留出法将Iris_linear数据集按7:3分为训练集与测试集,并使用训练集训练一个MED分类器,在测试集上测试训练好的分类器的性能,给出《模式识别与机器学习-评估方法与性能指标》中所有量化指标并可视化分类结果。
3.1 训练出的MED分类器:
核心代码:
def MED_classification(data,iris_type,t,f,flag):
data_linear,iris_type_linear=getIrisLinear(data,iris_type,flag)
train_data,train_type,test_data,test_type = hold_out_way(data_linear,iris_type_linear)
c1 = []
c2 = []
n1=0
n2=0
for i in range(len(train_data)): #均值
if train_type[i] == 1:
n1+=1
c1.append(train_data[i])
else:
n2+=1
c2.append(train_data[i])
c1 = np.asarray(c1)
c2 = np.asarray(c2)
z1 = c1.sum(axis=0)/n1
z2 = c2.sum(axis=0)/n2
test_result = []
for i in range(len(test_data)):
result = np.dot(z2-z1,test_data[i]-(z1+z2)/2)
test_result.append(np.sign(result))
test_result = np.array(test_result)
TP = 0
FN = 0
TN = 0
FP = 0
for i in range(len(test_result)):
if(test_result[i]>=0 and test_type[i]==t):
TP+=1
elif(test_result[i]>=0 and test_type[i]==f):
FN+=1
elif(test_result[i]<0 and test_type[i]==t):
FP+=1
elif(test_result[i]<0 and test_type[i]==f):
TN+=1
Recall = TP/(TP+FN)
Precision = TP/(TP+FP)
print("Recall= %f"% Recall)
print("Specify= %f"% (TN/(TN+FP)))
print("Precision= %f"% Precision)
print("F1 Score= %f"% (2*Recall*Precision/(Recall+Precision)))
#绘图
xx = [[0, 1, 2], [1, 2, 3], [0, 2, 3], [0, 1, 3]]
iris_name =['setosa','vesicolor','virginica']
iris_color = ['r','g','b']
iris_icon = ['o','x','^']
fig = plt.figure(figsize=(20, 20))
feature = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
for i in range(4):
ax = fig.add_subplot(221 + i, projection="3d")
X = np.arange(test_data.min(axis=0)[xx[i][0]],test_data.max(axis=0)[xx[i][0]],1)
Y = np.arange(test_data.min(axis=0)[xx[i][1]],test_data.max(axis=0)[xx[i][1]],1)
X,Y = np.meshgrid(X,Y)
m1 = [z1[xx[i][0]],z1[xx[i][1]],z1[xx[i][2]]]
m2 = [z2[xx[i][0]], z2[xx[i][1]], z2[xx[i][2]]]
m1 = np.array(m1)
m2 = np.array(m2)
m = m2-m1
#将公式进行化简
Z = (np.dot(m,(m1+m2)/2)-m[0]*X-m[1]*Y)/m[2]
ax.scatter(test_data[test_result >= 0, xx[i][0]], test_data[test_result>=0, xx[i][1]], test_data[test_result >= 0, xx[i][2]],
c=iris_color[t], marker=iris_icon[t], label=iris_name[t])
ax.scatter(test_data[test_result < 0, xx[i][0]], test_data[test_result < 0, xx[i][1]],
test_data[test_result < 0, xx[i][2]],
c=iris_color[f], marker=iris_icon[f], label=iris_name[f])
ax.set_zlabel(feature[xx[i][2]])
ax.set_xlabel(feature[xx[i][0]])
ax.set_ylabel(feature[xx[i][1]])
ax.plot_surface(X,Y,Z,alpha=0.4)
plt.legend(loc=0)
plt.show()
3.2 量化指标(线性可分)
Recall= 1.000000
Specify= 1.000000
Precision= 1.000000
F1_Score= 1.000000
核心代码:
def getIrisLinear(data,iris_type,flag):
data_linear = [data[i] for i in range(len(data)) if iris_type[i]!=flag]
iris_type_linear = [iris_type[i] for i in range(len(iris_type)) if iris_type[i]!=flag]
return np.asarray(data_linear,dtype="float64"),np.asarray(iris_type_linear,dtype="float64")
# 留出法
def hold_out_way(data_linear,iris_type_linear):
import random
train_data = []
train_type = []
test_data = []
test_type = []
first_cur = []
second_cur = []
for i in range(len(data_linear)):
if iris_type_linear[i] == 0:
first_cur.append(i)
else:
second_cur.append(i)
k = len(first_cur)-1
#七三开训练集和测试集
train_size = int(len(first_cur) * 7 / 10)
test_size = int(len(first_cur) * 3 / 10)
for i in range(0,train_size):
cur = random.randint(0,k)
train_data.append(data_linear[first_cur[cur]])
train_type.append(iris_type_linear[first_cur[cur]])
k = k - 1
first_cur.remove(first_cur[cur])
for i in range(len(first_cur)):
test_data.append(data_linear[first_cur[i]])
test_type.append(iris_type_linear[first_cur[i]])
k = len(second_cur)-1
train_size = int(len(second_cur) * 7 / 10)
test_size = int(len(second_cur) * 3 / 10)
for i in range(0, train_size):
cur = random.randint(0, k)
train_data.append(data_linear[second_cur[cur]])
train_type.append(iris_type_linear[second_cur[cur]])
k = k - 1
second_cur.remove(second_cur[cur])
for i in range(len(second_cur)):
test_data.append(data_linear[second_cur[i]])
test_type.append(iris_type_linear[second_cur[i]])
return np.asarray(train_data,dtype="float64"),np.asarray(train_type,dtype="int16"),np.asarray(test_data,dtype="float64"),np.asarray(test_type,dtype="int16")
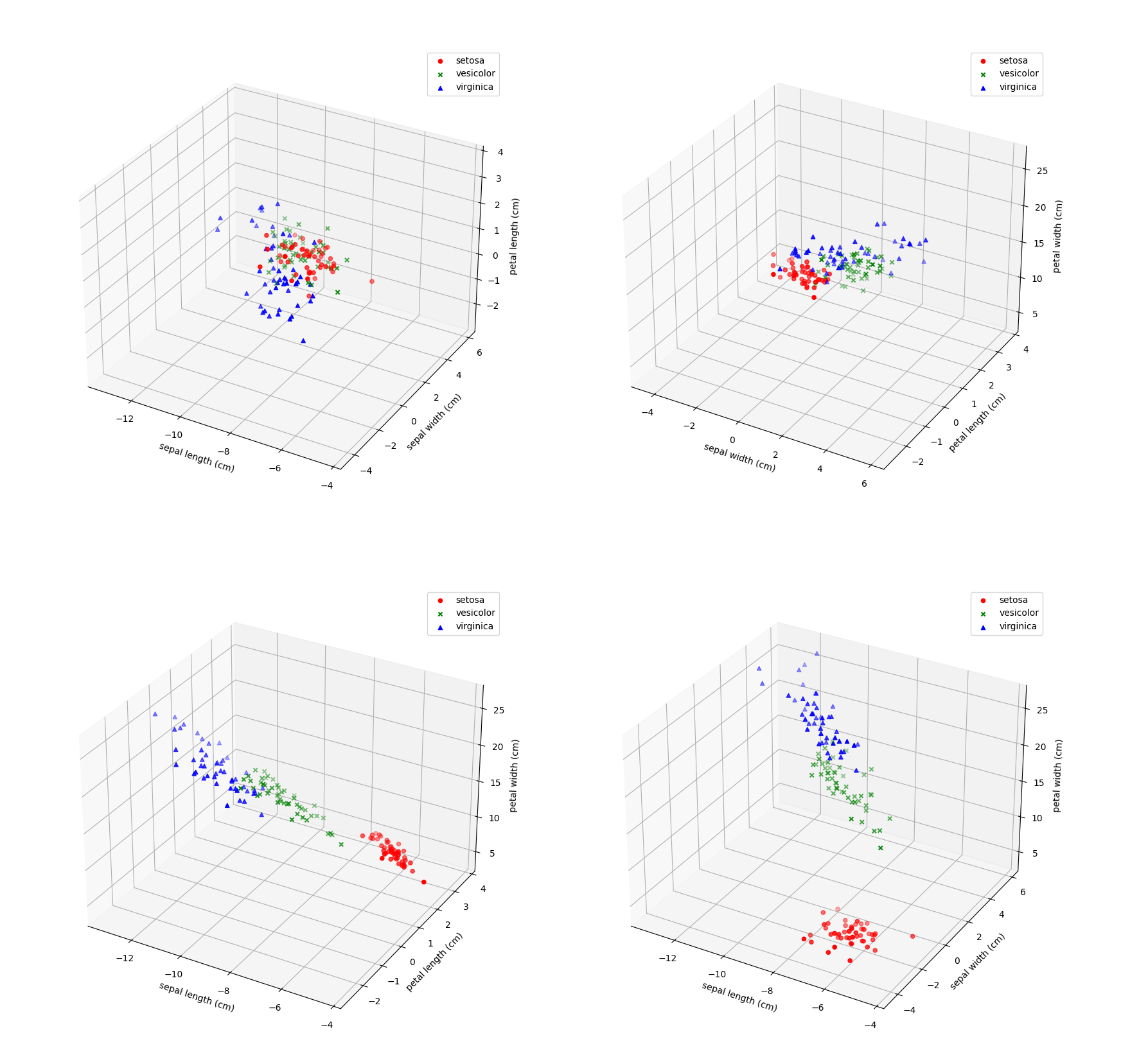
4. 将Iris数据集白化,可视化白化结果并于原始可视化结果比较,讨论白化的作用。
白话之后数据在某些维度上更容易区分
核心代码:
def to_whiten(data):
Ex = np.cov(data,rowvar=False)#这个一定要加……因为我们计算的是特征的协方差
a,w1 = np.linalg.eig(Ex)
w1 = np.real(w1)
module = []
for i in range(w1.shape[1]):
sum = 0
for j in range(w1.shape[0]):
sum += w1[i][j]**2
module.append(sum**0.5)
module = np.asarray(module,dtype="float64")
w1 = w1/module
a = np.real(a)
a=a**(-0.5)
w2 = np.diag(a)
w = np.dot(w2,w1.transpose())
for i in range(w.shape[0]):
for j in range(w.shape[1]):
if np.isnan(w[i][j]):
w[i][j]=0
#print(w)
return np.dot(data,w)
def show_whiten(data,iris_type):
whiten_array = to_whiten(data)
show_out_3D(whiten_array,iris_type)
def show_out_3D(data,iris_type):
xx = [[0, 1, 2], [1, 2, 3], [0, 2, 3], [0, 1, 3]]
fig = plt.figure(figsize=(20, 20))
feature = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
for i in range(4):
ax = fig.add_subplot(221 + i, projection="3d")
ax.scatter(data[iris_type == 0, xx[i][0]], data[iris_type == 0, xx[i][1]], data[iris_type == 0, xx[i][2]],
c='r', marker='o', label='setosa')
ax.scatter(data[iris_type == 1, xx[i][0]], data[iris_type == 1, xx[i][1]], data[iris_type == 1, xx[i][2]],
c='g', marker='x',
label='vesicolor')
ax.scatter(data[iris_type == 2, xx[i][0]], data[iris_type == 2, xx[i][1]], data[iris_type == 2, xx[i][2]],
c='b', marker='^',
label='virginica')
yy = [feature[xx[i][2]],feature[xx[i][0]],feature[xx[i][1]]]
ax.set_zlabel(yy[0])
ax.set_xlabel(yy[1])
ax.set_ylabel(yy[2])
plt.legend(loc=0)
plt.show()
5. 去除Iris数据集中线性可分的类,余下的两个线性不可分的类构成的数据集命令为Iris_nonlinear,请使用留出法将Iris_nonlinear数据集按7:3分为训练集与测试集,并使用训练集训练一个MED分类器,在测试集上测试训练好的分类器的性能,给出《模式识别与机器学习-评估方法与性能指标》中所有量化指标并可视化分类结果。讨论本题结果与3题结果的差异。
由于数据集不同,但是源代码相同,数据由原来的线性可分变成了线性不可分,量化也指标发生变化:`MED_classification(data, iris_type, 1, 2, 0)`量化指标:
Recall= 0.055556
Specify= 0.000000
Precision= 0.076923
F1_Score= 0.064516

6. 请使用5折交叉验证为Iris数据集训练一个多分类的贝叶斯分类器。给出平均Accuracy,并可视化实验结果。与第3题和第5题结果做比较,讨论贝叶斯分类器的优劣。

[[0.13907051 0.10769231 0.01535256 0.00964744]
[0.10769231 0.15035897 0.00846154 0.00774359]
[0.01535256 0.00846154 0.03266026 0.00592949]
[0.00964744 0.00774359 0.00592949 0.01178846]]
[[0.2515641 0.06255128 0.17673077 0.0455 ]
[0.06255128 0.08558333 0.07016026 0.03346795]
[0.17673077 0.07016026 0.22394231 0.06740385]
[0.0455 0.03346795 0.06740385 0.03404487]]
[[0.39997436 0.07634615 0.30252564 0.05411538]
[0.07634615 0.09573718 0.05016026 0.04580128]
[0.30252564 0.05016026 0.3148141 0.05450641]
[0.05411538 0.04580128 0.05450641 0.07973718]]
[[0.10342949 0.09647436 0.00407051 0.00778846]
[0.09647436 0.15587179 0.00919231 0.00888462]
[0.00407051 0.00919231 0.02173718 0.00601923]
[0.00778846 0.00888462 0.00601923 0.01225 ]]
[[0.26845513 0.0858141 0.19914103 0.06292308]
[0.0858141 0.09866026 0.0880641 0.04415385]
[0.19914103 0.0880641 0.25412821 0.084 ]
[0.06292308 0.04415385 0.084 0.04348718]]
[[0.43053846 0.12929487 0.31044872 0.05714103]
[0.12929487 0.12189103 0.10003205 0.05804487]
[0.31044872 0.10003205 0.29137821 0.04592949]
[0.05714103 0.05804487 0.04592949 0.07460897]]
[[0.104 0.07333333 0.03030769 0.01323077]
[0.07333333 0.11214744 0.02080128 0.01176282]
[0.03030769 0.02080128 0.03404487 0.00739103]
[0.01323077 0.01176282 0.00739103 0.01230128]]
[[0.29625 0.09996795 0.18679487 0.05833333]
[0.09996795 0.10225 0.10064103 0.05058974]
[0.18679487 0.10064103 0.20410256 0.07153846]
[0.05833333 0.05058974 0.07153846 0.04092308]]
[[0.32173718 0.07046154 0.26635256 0.03742308]
[0.07046154 0.09425641 0.05712821 0.0485641 ]
[0.26635256 0.05712821 0.28994231 0.04716667]
[0.03742308 0.0485641 0.04716667 0.08130769]]
[[0.13805128 0.10230769 0.01479487 0.01235897]
[0.10230769 0.13064103 0.00467949 0.00871795]
[0.01479487 0.00467949 0.02871154 0.00502564]
[0.01235897 0.00871795 0.00502564 0.00912821]]
[[0.26410256 0.08948718 0.18384615 0.05666667]
[0.08948718 0.10253846 0.07412821 0.03551282]
[0.18384615 0.07412821 0.21433333 0.06782051]
[0.05666667 0.03551282 0.06782051 0.03423077]]
[[0.42819872 0.10735897 0.30711538 0.04527564]
[0.10735897 0.11189744 0.08461538 0.04202564]
[0.30711538 0.08461538 0.29833333 0.05275641]
[0.04527564 0.04202564 0.05275641 0.07096795]]
[[0.13374359 0.11269231 0.01810256 0.00915385]
[0.11269231 0.16599359 0.01641026 0.01028846]
[0.01810256 0.01641026 0.03425641 0.00594872]
[0.00915385 0.01028846 0.00594872 0.00994231]]
[[0.25617949 0.08978205 0.17337179 0.05791026]
[0.08978205 0.10486538 0.08230128 0.04385256]
[0.17337179 0.08230128 0.21255769 0.07641667]
[0.05791026 0.04385256 0.07641667 0.04332692]]
[[0.44112821 0.08148718 0.32705128 0.04997436]
[0.08148718 0.09271795 0.06 0.04174359]
[0.32705128 0.06 0.32342949 0.04214744]
[0.04997436 0.04174359 0.04214744 0.07071154]]
[[0.13907051 0.10769231]
[0.10769231 0.15035897]]
[[0.2515641 0.06255128]
[0.06255128 0.08558333]]
[[0.39997436 0.07634615]
[0.07634615 0.09573718]]
[[0.13907051 0.01535256]
[0.01535256 0.03266026]]
[[0.2515641 0.17673077]
[0.17673077 0.22394231]]
[[0.39997436 0.30252564]
[0.30252564 0.3148141 ]]
[[0.13907051 0.00964744]
[0.00964744 0.01178846]]
[[0.2515641 0.0455 ]
[0.0455 0.03404487]]
[[0.39997436 0.05411538]
[0.05411538 0.07973718]]
[[0.15035897 0.00846154]
[0.00846154 0.03266026]]
[[0.08558333 0.07016026]
[0.07016026 0.22394231]]
[[0.09573718 0.05016026]
[0.05016026 0.3148141 ]]
[[0.15035897 0.00774359]
[0.00774359 0.01178846]]
[[0.08558333 0.03346795]
[0.03346795 0.03404487]]
[[0.09573718 0.04580128]
[0.04580128 0.07973718]]
[[0.03266026 0.00592949]
[0.00592949 0.01178846]]
[[0.22394231 0.06740385]
[0.06740385 0.03404487]]
[[0.3148141 0.05450641]
[0.05450641 0.07973718]]
0.9666666666666666
核心代码:
def k_split(data,iris_type,num):
import random
testSet = []
testType = []
first_cur = []
second_cur = []
third_cur = []
for i in range(len(iris_type)):
if iris_type[i] == 0:
first_cur.append(i)
elif iris_type[i] == 1:
second_cur.append(i)
else:
third_cur.append(i)
match_size = int(len(first_cur)/num)
size = len(first_cur)-1
train_data = []
train_type = []
for i in range(num):
k = match_size
train_data = []
train_type = []
for j in range(match_size):
cur = random.randint(0, size)
train_data.append(data[first_cur[cur]])
train_type.append(iris_type[first_cur[cur]])
first_cur.remove(first_cur[cur])
cur = random.randint(0, size)
train_data.append(data[second_cur[cur]])
train_type.append(iris_type[second_cur[cur]])
second_cur.remove(second_cur[cur])
cur = random.randint(0, size)
train_data.append(data[third_cur[cur]])
train_type.append(iris_type[third_cur[cur]])
third_cur.remove(third_cur[cur])
size = size-1
testSet.append(train_data)
testType.append(train_type)
return np.asarray(testSet),np.asarray(testType)
class Bayes_Parameter():
def __init__(self,mean,cov,type):
self.mean = mean
self.cov = cov
self.type = type
class Bayes_Classifier():
#必须存入k-1个训练集的每个高斯分布
def __init__(self):
self.parameters=[]
def train(self,data,iris_type):
for type in set(iris_type):
selected = iris_type==type
select_data = data[selected]
mean = np.mean(select_data,axis=0)
cov = np.cov(select_data.transpose())
print(cov)
self.parameters.append(Bayes_Parameter(mean,cov,type))
def predict(self,data):
result = -1
probability = 0
for parameter in self.parameters:
temp = gaussian_cal.pdf(data,parameter.mean,parameter.cov)
if temp > probability:
probability = temp
result = parameter.type
return result
def Bayes_Classification_K_split(data,iris_type,num):
train_dataset,train_typeset = k_split(data,iris_type,num)
accuracy = 0
best_result = []
best_train_data = []
best_train_type = []
best_test_data = []
best_test_type = []
max_accuracy = 0
for i in range(num):
data_num = 0
type_num = 0
train_data = []
train_type = []
for j in range(num):
if i != j:
if data_num*type_num == 0:
train_data = train_dataset[j]
train_type = train_typeset[j]
data_num+=1
type_num+=1
else:
train_data = np.concatenate((train_data,train_dataset[j]),axis=0)
train_type = np.concatenate((train_type,train_typeset[j]),axis=0)
Bayes_classifier = Bayes_Classifier()
Bayes_classifier.train(train_data,train_type)
predict_result = [Bayes_classifier.predict(x) for x in train_dataset[i]]
right = 0
all = 0
for j in range(len(predict_result)):
if predict_result[j] == train_typeset[i][j]:
right+=1
all+=1
tempaccuracy = right/all
if tempaccuracy > max_accuracy:
max_accuracy = tempaccuracy
best_train_data = train_data
best_train_type = train_type
best_test_data = train_dataset[i]
best_test_type = train_typeset[i]
best_result = np.asarray(predict_result,dtype="int")
accuracy+=tempaccuracy
show_out(best_train_data,best_train_type,best_test_data,best_test_type,best_result)
return accuracy/5
def show_out(train_data,train_type,test_data,test_type,result):
import math
fig = plt.figure(figsize=(10,10))
xx = [[0,1],[0,2],[0,3],[1,2],[1,3],[2,3]]
yy = [["sepal_length (cm)", "sepal_width (cm)"],
["sepal_width (cm)", "petal_length (cm)"],
["sepal_width(cm)", "petal_width(cm)"],
["sepal_length (cm)", "petal_length (cm)"],
["sepal_length (cm)", "petal_width(cm)"],
["sepal_width (cm)", "petal_width(cm)"]]
for i in range(6):
ax = fig.add_subplot(321+i)
x_max,x_min = test_data.max(axis=0)[xx[i][0]]+0.5,test_data.min(axis=0)[xx[i][0]]-0.5
y_max,y_min = test_data.max(axis=0)[xx[i][1]]+0.5,test_data.min(axis=0)[xx[i][1]]-0.5
xlist = np.linspace(x_min, x_max, 100)
ylist = np.linspace(y_min, y_max, 100)
X, Y = np.meshgrid(xlist,ylist)
bc = Bayes_Classifier()
bc.train(train_data[:,xx[i]],train_type)
xy = [np.array([xx,yy]).reshape(1,-1 ) for xx,yy in zip(np.ravel(X),np.ravel(Y))]
zz = np.array([bc.predict(x) for x in xy])
Z = zz.reshape(X.shape)
plt.contourf(X,Y,Z,2,alpha=.1,colors=('blue','red','green'))
ax.scatter(test_data[result==0,xx[i][0]],test_data[result==0,xx[i][1]],c='r',marker='o',label='setosa')
ax.scatter(test_data[result == 1, xx[i][0]], test_data[result == 1, xx[i][1]], c='g', marker='x',
label='versicolor')
ax.scatter(test_data[result == 2, xx[i][0]], test_data[result == 2, xx[i][1]], c='b', marker='^', label='virginica')
ax.set_xlabel(yy[i][0])
ax.set_ylabel(yy[i][1])
ax.legend(loc=0)
plt.show()
if __name__ == "__main__":
Iris = datasets.load_iris()
data,iris_type =Iris.data,Iris.target
print(Bayes_Classification_K_split(data,iris_type,5))