转 http://www.cnblogs.com/yanxinjiang/p/8288925.html
linux运维、架构之路-MHA高可用方案
一、软件介绍
MHA(master high availability)目前是MySQL高可用方面是一个相对成熟的解决方案。在切换过程中,mha能做到0-30s内自动完成数据库的切换,并且在切换过程中最大的保持数据的一致性,以达到真正意义上的高可用
|
1
|
<strong>https://github.com/yotoobo/linux/tree/master/mha #学习资料</strong> |
1、MHA的组成:
MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上,管理多个集群,也可以部署在从从库上。
当Master出现故障的时候,它可以自动将最新的数据的Slave提升为新的Master,然后将所有的Slave重新指向新的Master,整个故障转移过程是完全透明的

2、软件包工具介绍:
manager工具包包括:
- masterha_check_ssh #检查MHA的SSH状况
- masterha_check_repl #检查MySQL复制状况
- masterha_manger #启动MHA
- masterha_check_status #检测当前MHA运行状态
- masterha_master_monitor #检测master是否宕机
- masterha_master_switch #控制故障转移(自动或者手动)
- masterha_conf_host #添加或删除配置的server信息
- masterha_seconder_check #视图建立TCP连接从远程服务器
- masterha_stop #停止MHA
node工具包(由manager自动调用执行):
- save_binary_logs #保存和复制master的二进制日志
- apply_diff_relay_logs #识别差异的中继日志事件并将其差异的事件应用于其他的slave
- filter_mysqlbinlog #去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
- purge_relay_logs #清除中继日志(不会阻塞SQL线程)
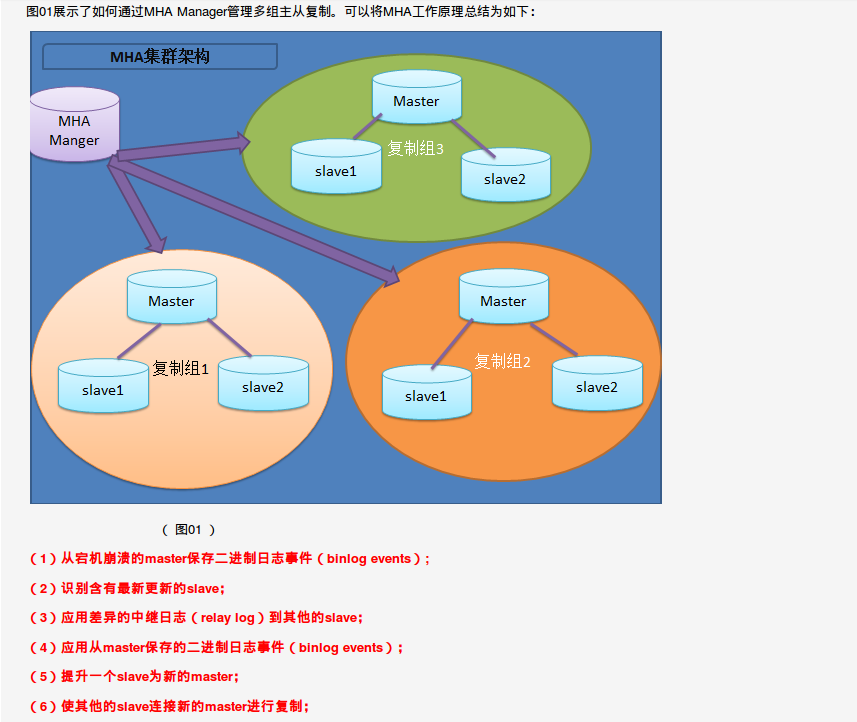
3、工作原理:
- 从宕机崩溃的master保存二进制日志事件;
- 识别含有最新的slave;
- 应用差异的中继日志(relay log)到其他的slave;
- 应用从master保存的二进制日志事件;
- 提升一个slave为新的master;
- 使其他的slave连接新的master进行复制
二、MHA方案部署
1、环境
db01

[root@db01 ~]# cat /etc/redhat-release CentOS release 6.9 (Final) [root@db01 ~]# uname -r 2.6.32-696.el6.x86_64 [root@db01 ~]# /etc/init.d/iptables status iptables: Firewall is not running. [root@db01 ~]# getenforce Disabled [root@db01 ~]# hostname -I 172.19.5.51 [root@db01 ~]# ll /application/ total 4 lrwxrwxrwx 1 root root 26 2018-01-15 11:59 mysql -> /application/mysql-5.6.36/ drwxr-xr-x 14 mysql mysql 4096 2018-01-15 12:00 mysql-5.6.36 #使用MySQL5.6.36版本
db02、db03除IP地址不一样,其它环境统一
[root@db02 ~]# hostname -I 172.19.5.52 [root@db03 ~]# hostname -I 172.19.5.53
2、配置主从(使用Gtid)
①db01(master)配置
[root@db01 ~]# cat /etc/my.cnf [client] user=root password=123456 [mysqld] log_bin=mysql-bin#开启log_bin server_id = 1 #三台MySQL的server_id不同 gtid_mode = ON #开启gtid功能 enforce_gtid_consistency log-slave-updates relay_log_purge = 0#关闭自动删除relay功能
②db02(slave)配置
[root@db02 ~]# cat /etc/my.cnf [client] user=root password=123456 [mysqld] log_bin=mysql-bin server_id = 2 gtid_mode = ON enforce_gtid_consistency log-slave-updates relay_log_purge = 0
③db03(slave)配置
[root@db03 ~]# cat /etc/my.cnf [client] user=root password=123456 [mysqld] log_bin=mysql-bin server_id = 3 gtid_mode = ON enforce_gtid_consistency log-slave-updates relay_log_purge = 0
④重启db01、db02、db03,所有库执行授权主从复制用户
grant replication slave on *.* to rep@'172.19.5.%' identified by '123456';
⑤从库db02、db03执行change master
change master to master_host='172.19.5.51',master_user='rep',master_password='123456',master_auto_position=1;start slave;show slave statusG#查看主从复制状态
主从复制配置完毕
3、安装MHA(所有节点都执行)
①安装依赖
rpm -ivh http://mirrors.yun-idc.com/epel/6/x86_64/epel-release-6-8.noarch.rpm yum install perl-DBD-MySQL -y yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
②授权MHA管理用户
grant all privileges on *.* to mha@'172.19.5.%' identified by 'mha';
③安装MHA节点包
cd /server/tools/ #上传mha4mysql-node-0.56-0.el6.noarch.rpm rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
④创建命令软链接(mha调用mysql命令默认在/usr/bin下面,不做此步mha会报错)
ln -s /application/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog ln -s /application/mysql/bin/mysql /usr/bin/mysql
挑选一台节点安装MHA管理端,这里选择db03
[root@db03 tools]# rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm #只在db03上面安装管理端 Preparing... ########################################### [100%] 1:mha4mysql-manager ########################################### [100%]
4、配置MHA(只在管理端执行db03)
①创建MHA配置文件、日志存放目录
[root@db03 ~]# mkdir /etc/mha -p [root@db03 ~]# mkdir /var/log/mha/app1 -p
②创建MHA配置文件
[root@db03 ~]# cat /etc/mha/app1.cnf [server default] manager_log=/var/log/mha/app1/manager manager_workdir=/var/log/mha/app1 master_binlog_dir=/application/mysql/data user=mha password=mha ping_interval=2 repl_password=123456 repl_user=rep ssh_user=root [server1] hostname=172.19.5.51 port=3306 [server2] hostname=172.19.5.52 port=3306 [server3] hostname=172.19.5.53 port=3306
③配置文件说明
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
[server default]#设置manager的工作目录manager_workdir=/var/log/masterha/app1#设置manager的日志manager_log=/var/log/masterha/app1/manager.log#设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录master_binlog_dir=/data/mysql#设置自动failover时候的切换脚本master_ip_failover_script= /usr/local/bin/master_ip_failover#设置手动切换时候的切换脚本master_ip_online_change_script= /usr/local/bin/master_ip_online_change#设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码password=123456#设置监控用户rootuser=root#设置监控主库,发送ping包的时间间隔,尝试三次没有回应的时候自动进行failoverping_interval=1#设置远端mysql在发生切换时binlog的保存位置remote_workdir=/tmp#设置复制用户的密码repl_password=123456#设置复制环境中的复制用户名repl_user=rep#设置发生切换后发送的报警的脚本report_script=/usr/local/send_report#一旦MHA到server02的监控之间出现问题,MHA Manager将会尝试从server03登录到server02secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02 --user=root --master_host=server02 --master_ip=192.168.0.50 --master_port=3306#设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用)shutdown_script=""#设置ssh的登录用户名ssh_user=root [server1]hostname=172.19.5.51port=3306 [server2]hostname=172.19.5.52port=3306#设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slavecandidate_master=1#默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的mastercheck_repl_delay=0 |
5、配置MHA节点间的免ssh认证
①db01、db02、db03都执行
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.19.5.51 ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.19.5.52 ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.19.5.53
②db03上面测试ssh连通性
masterha_check_ssh --conf=/etc/mha/app1.cnf Mon Jan 15 15:38:01 2018 - [debug] Connecting via SSH from root@172.19.5.53(172.19.5.53:22) to root@172.19.5.51(172.19.5.51:22).. Mon Jan 15 15:38:01 2018 - [debug] ok. Mon Jan 15 15:38:01 2018 - [debug] Connecting via SSH from root@172.19.5.53(172.19.5.53:22) to root@172.19.5.52(172.19.5.52:22).. Mon Jan 15 15:38:01 2018 - [debug] ok. Mon Jan 15 15:38:02 2018 - [info] All SSH connection tests passed successfully.
③db03检查主从复制状态
masterha_check_repl --conf=/etc/mha/app1.cnf Mon Jan 15 15:39:51 2018 - [info] Checking replication health on 172.19.5.52.. Mon Jan 15 15:39:51 2018 - [info] ok. Mon Jan 15 15:39:51 2018 - [info] Checking replication health on 172.19.5.53.. Mon Jan 15 15:39:51 2018 - [info] ok. Mon Jan 15 15:39:51 2018 - [warning] master_ip_failover_script is not defined. Mon Jan 15 15:39:51 2018 - [warning] shutdown_script is not defined. Mon Jan 15 15:39:51 2018 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.
6、启动MHA
①启动MHA服务
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
②查看MHA进程
[root@db03 ~]# ps -ef|grep mha root 9305 1003 0 15:41 pts/0 00:00:00 perl /usr/bin/masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover
③MHA日志文件
[root@db03 ~]# tail -f /var/log/mha/app1/manager 172.19.5.51(172.19.5.51:3306) (current master) +--172.19.5.52(172.19.5.52:3306) +--172.19.5.53(172.19.5.53:3306) Mon Jan 15 15:41:09 2018 - [warning] master_ip_failover_script is not defined. Mon Jan 15 15:41:09 2018 - [warning] shutdown_script is not defined. Mon Jan 15 15:41:09 2018 - [info] Set master ping interval 2 seconds. Mon Jan 15 15:41:09 2018 - [warning] secondary_check_script is not defined. It is highly recommended setting it to check master reachability from two or more routes. Mon Jan 15 15:41:09 2018 - [info] Starting ping health check on 172.19.5.51(172.19.5.51:3306).. Mon Jan 15 15:41:09 2018 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
7、模拟主库db01宕机进行测试
①关闭主库db01
[root@db01 ~]# /etc/init.d/mysqld stop Shutting down MySQL...... SUCCESS!
②MHA管理端查看日志
[root@db03 ~]# tail -f /var/log/mha/app1/manager Master 172.19.5.51(172.19.5.51:3306) is down! Check MHA Manager logs at db03:/var/log/mha/app1/manager for details. Started automated(non-interactive) failover. Selected 172.19.5.52(172.19.5.52:3306) as a new master. 172.19.5.52(172.19.5.52:3306): OK: Applying all logs succeeded. 172.19.5.53(172.19.5.53:3306): OK: Slave started, replicating from 172.19.5.52(172.19.5.52:3306) 172.19.5.52(172.19.5.52:3306): Resetting slave info succeeded. Master failover to 172.19.5.52(172.19.5.52:3306) completed successfully.#提示已经切换到172.19.5.52这台机子上面了
③登录db03查看主从复制状态
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.19.5.52
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 1351
Relay_Log_File: db03-relay-bin.000002
Relay_Log_Pos: 960
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
到此,数据库故障切换成功,当数据库宕机后,MHA的配置文件中会自动把宕掉的这台数据库server标签去掉,故障恢复后需要手动再次做主从
[root@db03 ~]# grep -i "change master " /var/log/mha/app1/manager #这里可以快速找到主从复制命令 CHANGE MASTER TO MASTER_HOST='172.19.5.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rep', MASTER_PASSWORD='xxx';
④启动db01,手动做主从
[root@db01 ~]# /etc/init.d/mysqld start Starting MySQL.. SUCCESS!
登录数据库
CHANGE MASTER TO MASTER_HOST='172.19.5.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rep', MASTER_PASSWORD='123456';
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.19.5.52
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 1351
Relay_Log_File: db01-relay-bin.000002
Relay_Log_Pos: 960
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
******MHA切换是从所有从库中找一台binlog最新的提升为主库
如果想指定某一台配置好的服务器为主的话,可以在MHA配置文件里增加参数,这样会导致数据丢失
|
1
2
3
4
5
6
7
|
/etc/mha/app1.cnf......[server3]candidate_master=1 #优先提升为主库check_repl_delay=0 #忽略复制延迟hostname=172.19.5.53port=3306 |
8、配置binlog-server
如果主从还没有完成binlog的传输就宕机了,那么有一部分数据就可能丢失,开启MHA备份binlog功能
①修改配置文件
[root@db03 ~]# cat /etc/mha/app1.cnf [server default] manager_log=/var/log/mha/app1/manager manager_workdir=/var/log/mha/app1 master_binlog_dir=/application/mysql/data password=mha ping_interval=2 repl_password=123456 repl_user=rep ssh_user=root user=mha [server1] hostname=172.19.5.51 port=3306 [server2] hostname=172.19.5.52 port=3306 [server3] hostname=172.19.5.53 port=3306 #增加如下参数# [binlog1] no_master=1 hostname=172.19.5.53 master_binlog_dir=/data/mysql/binlog/
②创建存放binlog的目录
[root@db03 ~]# mkdir /data/mysql/binlog/ -p [root@db03 ~]# cd /data/mysql/binlog/ [root@db03 binlog]# mysqlbinlog -R --host=172.19.5.52 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
#这里--host是主库的ip地址,mysql-bin.000001是MHA配置文件中定义的binlog文件名
[root@db03 binlog]# ll total 4 -rw-rw---- 1 root root 1148 2018-01-15 16:22 mysql-bin.000001
③在主库db02上面刷新binlog
[root@db02 ~]# mysqladmin flush-logs #db03上面再次查看 [root@db03 binlog]# ll total 8 -rw-rw---- 1 root root 1398 2018-01-15 16:29 mysql-bin.000001 -rw-rw---- 1 root root 120 2018-01-15 16:29 mysql-bin.000002
三、配置主库VIP漂移
1、准备脚本
[root@db03 ~]# vim /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '172.19.5.55/24';#高可用VIP
#此处配置在eth0:1上面,如果是其它请自行修改配置文件
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
GetOptions(
'command=s' => $command,
'ssh_user=s' => $ssh_user,
'orig_master_host=s' => $orig_master_host,
'orig_master_ip=s' => $orig_master_ip,
'orig_master_port=i' => $orig_master_port,
'new_master_host=s' => $new_master_host,
'new_master_ip=s' => $new_master_ip,
'new_master_port=i' => $new_master_port,
);
exit &main();
sub main {
print "
IN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===
";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host
";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@
";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host
";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK
";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user@$new_master_host " $ssh_start_vip "`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user@$orig_master_host " $ssh_stop_vip "`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port
";
}
2、将上述脚本加入到MHA配置文件中
[root@db03 ~]# cat /etc/mha/app1.cnf [server default] manager_log=/var/log/mha/app1/manager manager_workdir=/var/log/mha/app1 master_binlog_dir=/application/mysql/data master_ip_failover_script=/usr/local/bin/master_ip_failover #此处为增加参数内容 password=mha ping_interval=2 repl_password=123456 repl_user=rep ssh_user=root user=mha #……省略若干行……#
为脚本增加执行权限
chmod +x /usr/local/bin/master_ip_failover
3、主库db02手工绑定VIP
[root@db02 ~]# ifconfig eth0:1 172.19.5.55/24
[root@db02 ~]# ip a|grep 172.19
inet 172.19.5.52/24 brd 172.19.5.255 scope global eth0
inet 172.19.5.55/24 scope global secondary eth0
4、重启MHA管理端
①停止MHA
[root@db03 ~]# masterha_stop --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1
②启动MHA
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
③模拟主库db02宕机
[root@db02 ~]# /etc/init.d/mysqld stop Shutting down MySQL...... SUCCESS!
④查看MHA管理端日志
[root@db03 ~]# tail -f /var/log/mha/app1/manager Check MHA Manager logs at db03:/var/log/mha/app1/manager for details. Started automated(non-interactive) failover. Invalidated master IP address on 172.19.5.52(172.19.5.52:3306) Selected 172.19.5.51(172.19.5.51:3306) as a new master. 172.19.5.51(172.19.5.51:3306): OK: Applying all logs succeeded. 172.19.5.51(172.19.5.51:3306): OK: Activated master IP address. 172.19.5.53(172.19.5.53:3306): OK: Slave started, replicating from 172.19.5.51(172.19.5.51:3306) 172.19.5.51(172.19.5.51:3306): Resetting slave info succeeded. Master failover to 172.19.5.51(172.19.5.51:3306) completed successfully. #主库又切换到了172.19.5.51上面,也就是db01
登录数据库查看主从状态
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.19.5.51
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 696
Relay_Log_File: db03-relay-bin.000002
Relay_Log_Pos: 408
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
⑤db01上面查看vip
[root@db01 ~]# ip a|grep 172.19.5.55
inet 172.19.5.55/24 brd 172.19.5.255 scope global secondary eth0:1
四、MySQL读写分离Atlas
1、Atlas优点
①将主流程中的所有Lua代码用C重写,Lua仅用于管理接口;
②重写网络模型,线程模型;
③实现了真正意义上的连接池;
④优化了锁机制,性能提高了数十倍
|
1
|
<strong>https://github.com/Qihoo360/Atlas/releases #学习资料</strong> |
2、部署Atlas
atlas部署在mha的管理节点db03上面,这样可以部署高可用防止单点故障
①部署环境
172.19.5.51 db01#主库 172.19.5.52 db02#从库 172.19.5.53 db03#从库-MHA管理端
②安装
[root@db03 tools]# cd /server/tools/ [root@db03 tools]# rpm -ivh Atlas-2.2.1.el6.x86_64.rpm Preparing... ########################################### [100%] 1:Atlas ########################################### [100%]
③安装目录文件说明
[root@db03 ~]# ll /usr/local/mysql-proxy/ total 16 drwxr-xr-x 2 root root 4096 2018-01-16 10:15 bin #可执行文件 drwxr-xr-x 2 root root 4096 2018-01-16 10:32 conf #代理配置文件,test.cnf drwxr-xr-x 3 root root 4096 2018-01-16 10:15 lib #Atlas依赖库 drwxr-xr-x 2 root root 4096 2018-01-16 10:34 log #日志文件目录
bin目录下文件
[root@db03 ~]# ls /usr/local/mysql-proxy/bin/ total 44 encrypt #生成MySQL密码加密时使用 mysql-proxy #MySQL自己开发出来的读写分离代理 mysql-proxyd #360开发出来的,控制服务的启动、重启、停止,以及执行配置文件conf/test.cnf
④创建加密密码
[root@db03 ~]# /usr/local/mysql-proxy/bin/encrypt 123456 /iZxz+0GRoA=
⑤Atlas代理配置文件
[root@db03 ~]# cat /usr/local/mysql-proxy/conf/test.cnf [mysql-proxy] admin-username = altas admin-password = 123456 proxy-backend-addresses = 172.19.5.55:3306 proxy-read-only-backend-addresses = 172.19.5.52:3306,172.19.5.53:3306 pwds = atlas:/iZxz+0GRoA= daemon = true keepalive = true event-threads = 8 log-level = message log-path = /usr/local/mysql-proxy/log sql-log = REALTIME proxy-address = 0.0.0.0:1234 admin-address = 0.0.0.0:2345 charset = utf8
配置文件说明
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[mysql-proxy]admin-username = user #管理端用户名admin-password = pwd #管理端密码proxy-backend-addresses = 172.19.5.51:3306 #主库,这里优于之前的数据库配置到了3306,这里如果修改的话,工作量大,工作这里一般不配置3306,要把3306让给atlas使用proxy-read-only-backend-addresses = 172.19.5.52:3306,172.19.5.53:3306 #从库,可以写多个pwds = atlas:/iZxz+0GRoA= #管理数据的用户名和密码,也可配置多个daemon = truekeepalive = trueevent-threads = 32log-level = messagelog-path = /usr/local/mysql-proxy/logsql-log = trueproxy-address = 0.0.0.0:3305 #这里应该是3306,为了程序方便,直连3306,让atlas连接3307,生产环境可以替换admin-address = 0.0.0.0:2345 #管理员端charset = utf8 |
⑥启动Atlas服务
[root@db03 mysql-proxy]# /usr/local/mysql-proxy/bin/mysql-proxyd test start OK: MySQL-Proxy of test is started
⑦db01、db02、db03都执行授权MHA
grant all privileges on *.* to mha@'%' identified by '123456';
⑧管理端db03登录
[root@db03 ~]# mysql -ualtas -p123456 -h 127.0.0.1 -P2345 mysql> select * from backends; +-------------+------------------+-------+------+ | backend_ndx | address | state | type | +-------------+------------------+-------+------+ | 1 | 172.19.5.51:3306 | up | rw | | 2 | 172.19.5.52:3306 | up | ro | | 3 | 172.19.5.53:3306 | up | ro | +-------------+------------------+-------+------+ 3 rows in set (0.00 sec)
3、宕机故障分析
①主库宕机后,需要执行脚本从连接池拆除主库
[root@db03 ~]# cat /usr/local/bin/remove_master.sh
#!/bin/bash
MysqlLogin="mysql -uatlas -p123456 -h127.0.0.1 -P2345"
NEW_MASTER_HOST=`ssh 172.19.5.53 tail -1 /var/log/mha/app1/manager|awk -F "[ (]" '{print $11}'` &>/dev/null
RO_NUM=`$MysqlLogin -e 'SELECT * FROM backends' |grep "$NEW_MASTER_HOST" |awk '{print $1}'` &>/dev/null
$MysqlLogin -e "REMOVE BACKEND $RO_NUM" &>/dev/null
$MysqlLogin -e 'SAVE CONFIG' &>/dev/null
echo "`date +%F_%T` $NEW_MASTER_HOST is become master, remove it in atlas." &>>/var/log/remove_ro.log
②/usr/local/bin/remove_master.sh脚本中套用拆除脚本
......
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host
";
&start_vip();
`/bin/sh /usr/local/bin/remove_master.sh`; #新插入的一行
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
......
③模拟主库db01宕机,在管理端查看日志分析
[root@db01 ~]# /etc/init.d/mysqld stop Shutting down MySQL..... SUCCESS!
[root@db03 ~]# tail -F /var/log/remove_ro.log tail: cannot open `/var/log/remove_ro.log' for reading: No such file or directory tail: `/var/log/remove_ro.log' has become accessible 2018-01-16_11:45:22 172.19.5.52 is become master, remove it in atlas.#从连接池移除掉了主库db01
④管理端db03登录查看
[root@db03 ~]# mysql -ualtas -p123456 -h 127.0.0.1 -P2345 mysql> select * from backends; +-------------+------------------+-------+------+ | backend_ndx | address | state | type | +-------------+------------------+-------+------+ | 1 | 172.19.5.52:3306 | up | rw | | 2 | 172.19.5.53:3306 | up | ro | +-------------+------------------+-------+------+