Andrew Ng机器学习课程笔记(三)之正则化
版权声明:本文为博主原创文章,转载请指明转载地址
http://www.cnblogs.com/fydeblog/p/7365475.html
前言
学习了Andrew Ng课程,开始写了一些笔记,现在写完第5章了,先把这5章的内容放在博客中,后面的内容会陆续更新!
这篇博客主要记录Andrew Ng课程第三章正则化,主要介绍了线性回归和逻辑回归中,怎样去解决欠拟合和过拟合的问题
简要介绍:在进行线性回归或逻辑回归时,常常会出现以下三种情况
回归问题:
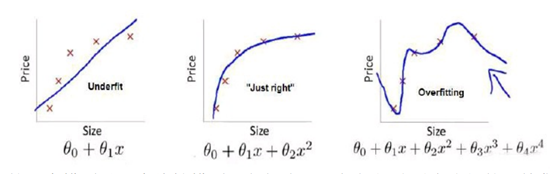
第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练中;第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出, 若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
分类问题也一样:
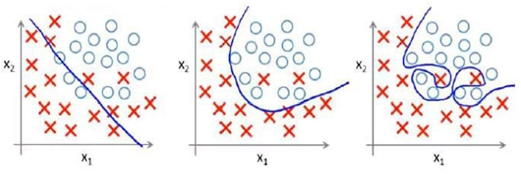
问题来了,那么解决方案也出现了,那就是正则化。
1. 改造代价函数
上面出现的过拟合是因为那些高次项导致了它们的产生,所以如果我们能让这些高次项的系数接近于0的话,我们就能很好的拟合了。
试想一下,将上面的代价函数改动如下,增加了关于和两项
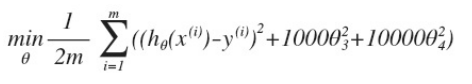
这样做的话,我们在尝试最小化代价时也需要将这个表达式纳入考虑中,并最终导致选择较小一些的θ3和θ4,那样就从过拟合过渡到拟合状态。
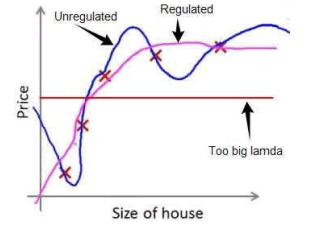
经过正则化处理的模型与原模型的可能对比如下图所示:
2. 正则化线性回归
(1)基于梯度下降
正则化线性回归的代价函数为:
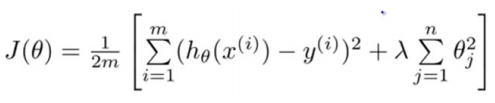
如果我们要使用梯度下降法令这个代价函数最小化,因为我们未对θ0进行正则化,所以梯度下降算法将分两种情形:
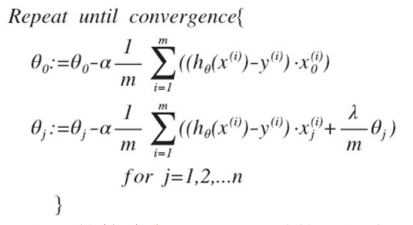
转换一下,可以写为
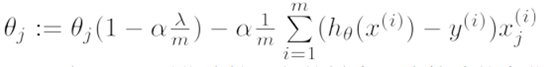
可见,正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令θ值减少了一个额外的值。
(2) 正规方程
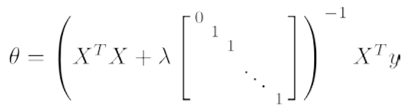
3. 正则化逻辑回归
相应的代价函数:
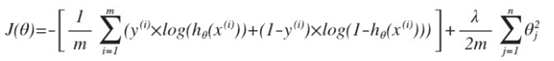
梯度下降算法:

虽然正则化的逻辑回归中的梯度下降和正则化的线性回归中的表达式看起来一样,但由于两者的h(x)不同所以还是有很大差别。