李宏毅深度学习
https://www.bilibili.com/video/av9770302/?p=8
Generation
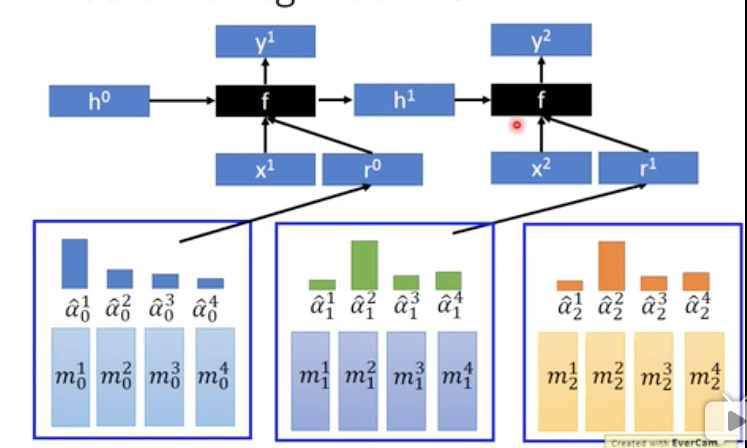
生成模型基本结构是这样的,
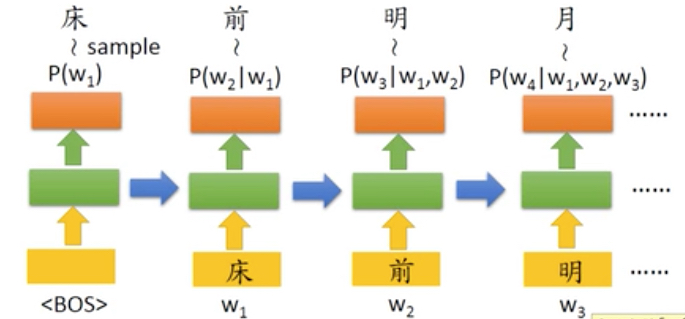
这个生成模型有个问题是我不能干预数据生成,这里是随机的,
Conditional Generation
这里我们通过初始输入来增加条件,
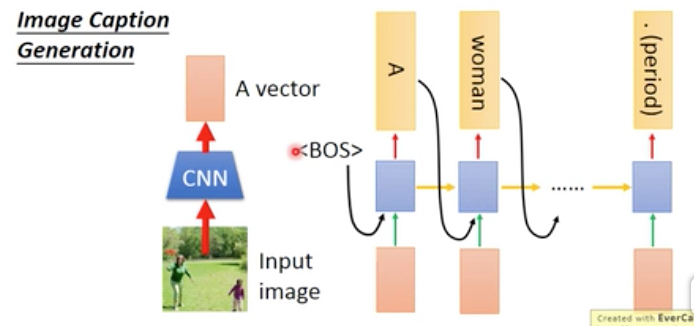
比如要根据图片来深层文字,这里以image作为输入
当然首先要用cnn将图片生成embeding
为了防止RNN在进行的过程中forget这个输入,可以把图片作为每一步的输入传给网络
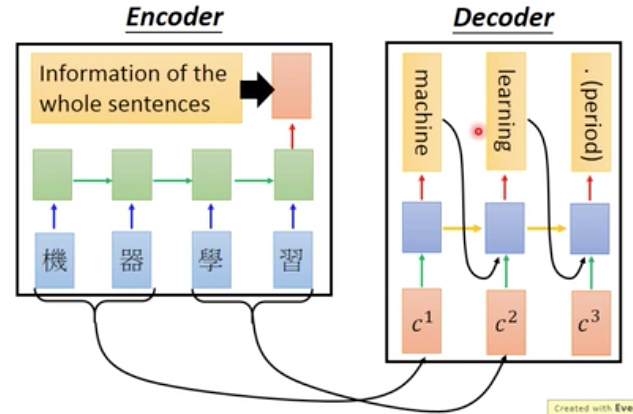
在NLP中,就是Sequence to Sequence模型,
seq2seq可以用作机器翻译或chatbot应用,
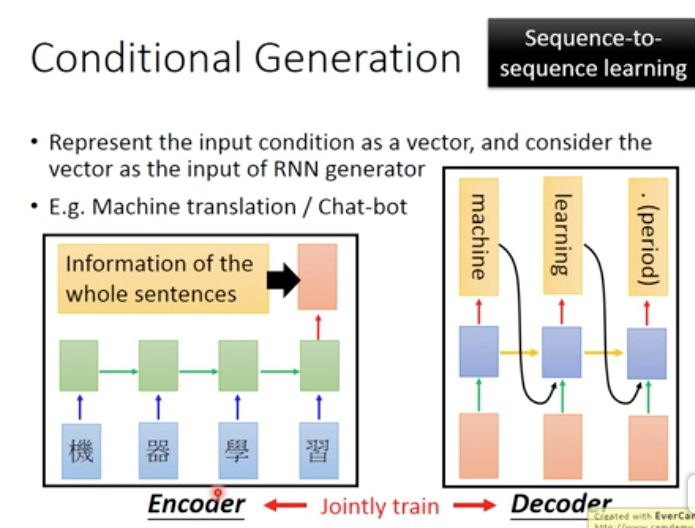
和上面的image case不同在于,
首先sentence的编码需要用rnn,而不是cnn,并且这里encoder和decoder是可以jointly train的,即同时train出encoder和decoder的参数
如果做的是chatbot,那么会有下面的问题,
会出现Hi,Hi,Hi........的对话
因为在没有上下文的情况下,对Hi的回答会一直是Hi
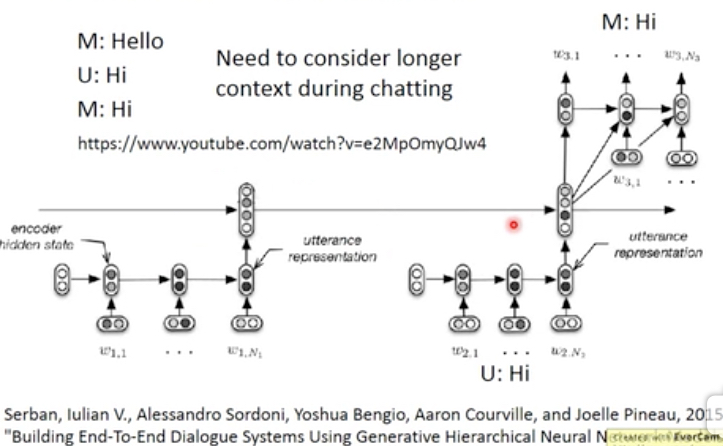
直觉的解法,要让网络知道上下文,就把历史encoder的结果级联起来,输出给decoder,让他知道之前说过什么
Attention
attention模型如其名,就是注意力模型
传统的情况,会把整个数据,比如整张图片,或者整段话,作为输入给网络
但这样也许是不合理的,比如下面的例子,在翻译machine的时候,我只需要看机器两个字就好,这样可以更加专注
那么怎么达到这个效果了
对于网络的设计而言,直觉上,我们可以通过一组参数来选择输入中的那一部分对网络可见
这组参数可称为attention,如何产生这些参数,
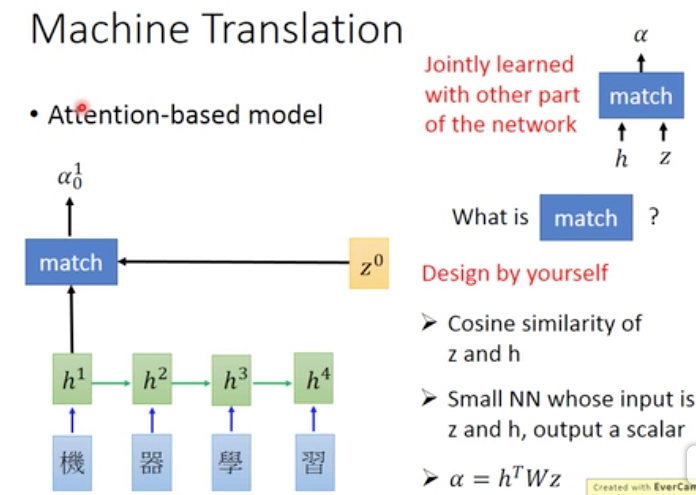
可以看到,我们可以用decode的输出z0和每个输入,用match function算一个attention
match function,这里给出多种选择
Attention模型的整个过程如下,
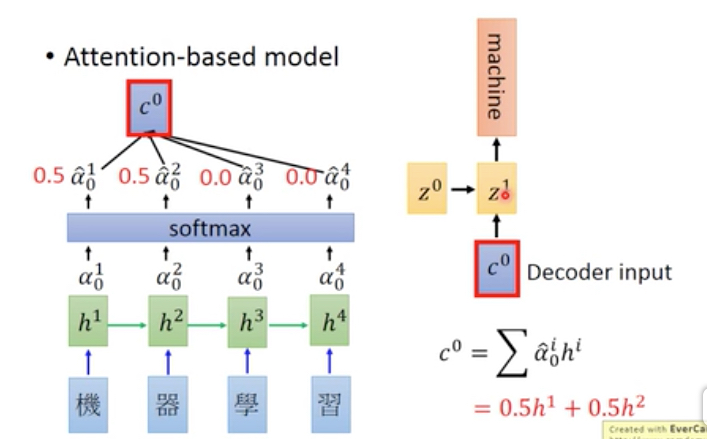
算出一组attention向量a,然后这里加上一个softmax是为了normalization,让向量的和为1
然后用attention和输入笛卡尔积,得到c0,把c0作为输入给到decoder
可以看到这里,c0是根据attention产生的,这里只包含‘机器’
然后这个过程可以这么一直做下去,
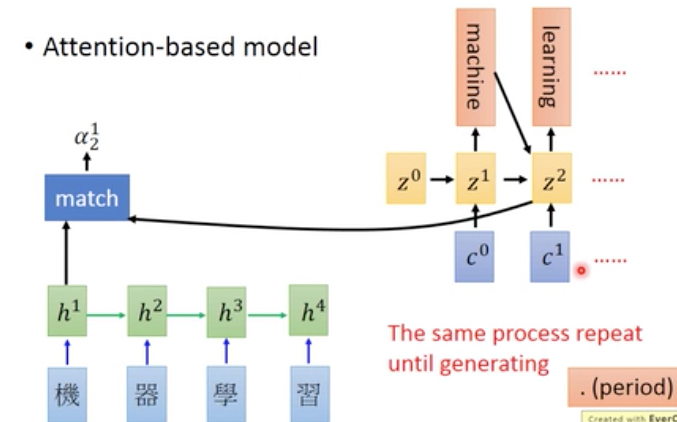
同样对于图片,我们也可以用attention模型,

用attention去选择每次激活哪些filter
最终得到效果如下,高亮部分表示下面划线的词,所attention的部分

Memory Network
个人理解,这个是attention network的一种,
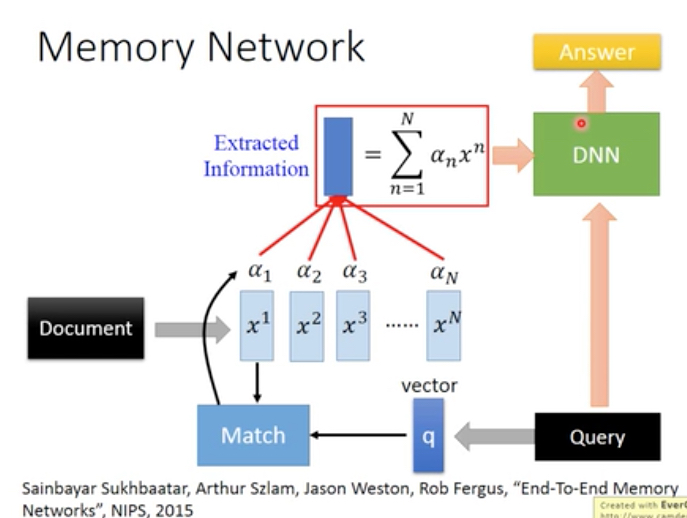
比如下面的例子,是一个智能问答系统,
通过query和document来计算attention,从而选择相应的文档子集,传给深度网络,得到answer
这个模型是可以整个joinit训练的,包含document产生embedding的参数,query embedding的参数,Match的参数等
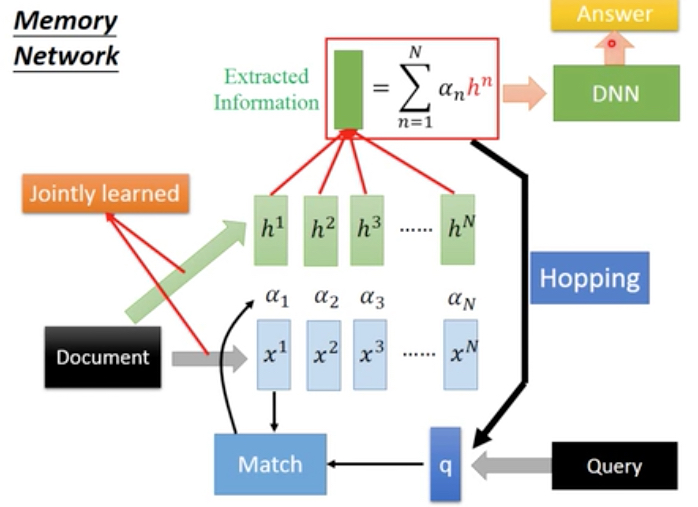
更复杂的模型,
这里产生attention和抽象文档内容,分别使用不同的embedding,这样就需要把document做两次encoding,参数会比较多
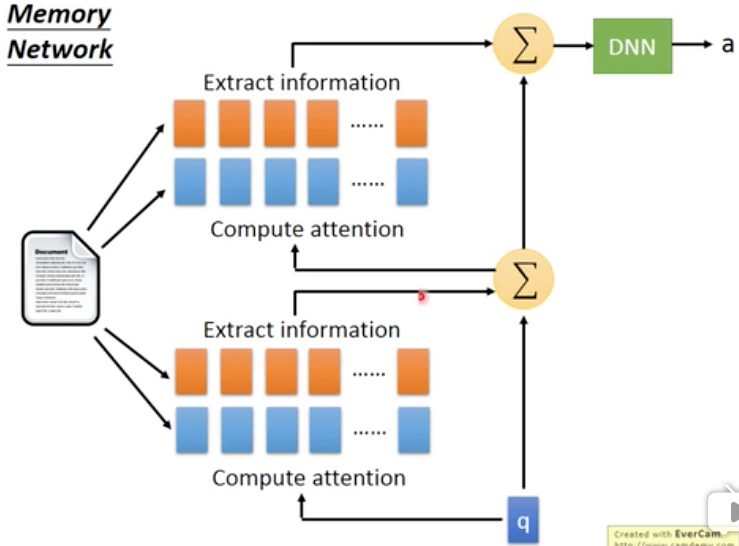
还加上Hopping过程,即得到Extracted Informatica后,不立刻传给DNN做为输入
而是循环做多次,attention生成和内容抽取的工作,过程如下,
Nenual Turing Machine
这种网络的区别在于,前面的attention网络都是在不断的变化attention,但是不会修改内容
这种网络每次会去改变memory本身的内容
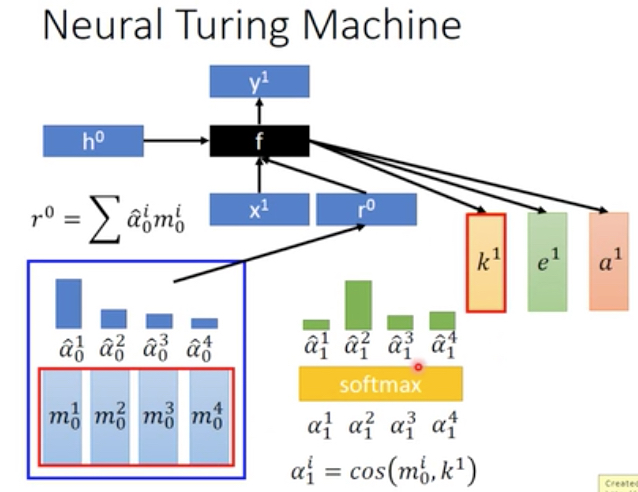
这一部分和attention一样,先更加memory和attention生成抽样内容r0,将r0输入网络后,产生3个输出,k,e,a
这里k是用来更新attention的,和之前一样,
而e和a是用来改变内容的,e用于清空内容,a用于填充内容,具体公式如下,
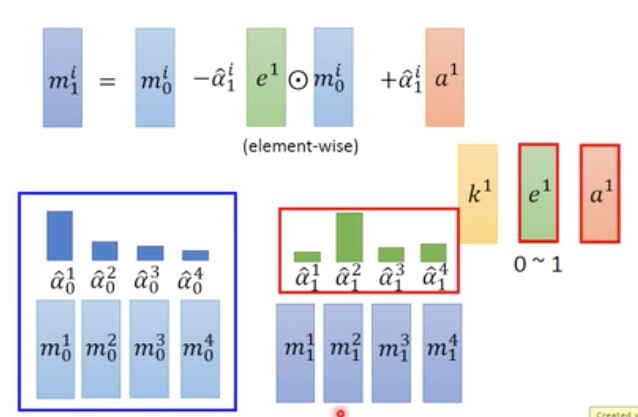
级联起来就是这样,