从CSDN来博客园开个博
Cao, W., Gao, Y., Lin, B., Feng, X., Xie, Y., Lou, X., & Wang, P. (2018, May). Tcprt: Instrument and diagnostic analysis system for service quality of cloud databases at massive scale in real-time. In Proceedings of the 2018 International Conference on Management of Data (pp. 615-627).
Zhang, J., Wu, S., Tan, Z., Chen, G., Cheng, Z., Cao, W., ... & Feng, X. (2019). S3: a scalable in-memory skip-list index for key-value store. Proceedings of the VLDB Endowment, 12(12), 2183-2194.
Cao, W., Gao, Y., Li, F., Wang, S., Lin, B., Xu, K., ... & Zhang, G. (2020, June). Timon: A Timestamped Event Database for Efficient Telemetry Data Processing and Analytics. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (pp. 739-753).
Chen, W., Chen, L., Xie, Y., Cao, W., Gao, Y., & Feng, X. (2020, April). Multi-range attentive bicomponent graph convolutional network for traffic forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 04, pp. 3529-3536).
Cao, W., Feng, X., Liang, B., Zhang, T., Gao, Y., Zhang, Y., & Li, F. (2021, June). LogStore: A Cloud-Native and Multi-Tenant Log Database. In Proceedings of the 2021 International Conference on Management of Data (pp. 2464-2476).
Yishan Managing large-scale cloud database instances via machine learning
Timon
Blind Write VS. Read-Modify-Write
out-of-order events不用进行RMW,直接blind write
幂等保证Exactly Once
对于At-least Once的系统Kafka,记录每个Partition的latest offset,避免重复存储
数据模型
如图,
一组一同采集的metric,metricSet,具有一个时间戳,等同于row
一个metricSet的collection,称为StreamSet ,具有一个uuid,比如对于某一个主机发送的指标组,就用一个uuid标识
以uuid为标准,匹配一组TagSet,即一个StreamSet可以附加一组特殊的属性
TagSet单独存储,作为元数据,存储在本地的rocksDB中

SEDA (Staged Event Driven Architecture)
Windows聚合和Late数据的处理
首先,数据写入时,有两个MemTable,其中一个是为了late数据的
为何要单独分出一个late的,因为late的会破坏连续性,不便于后续用数组来存储数据
这里之所以有late的说法,就需要参考dataflow里面对于窗口的解释
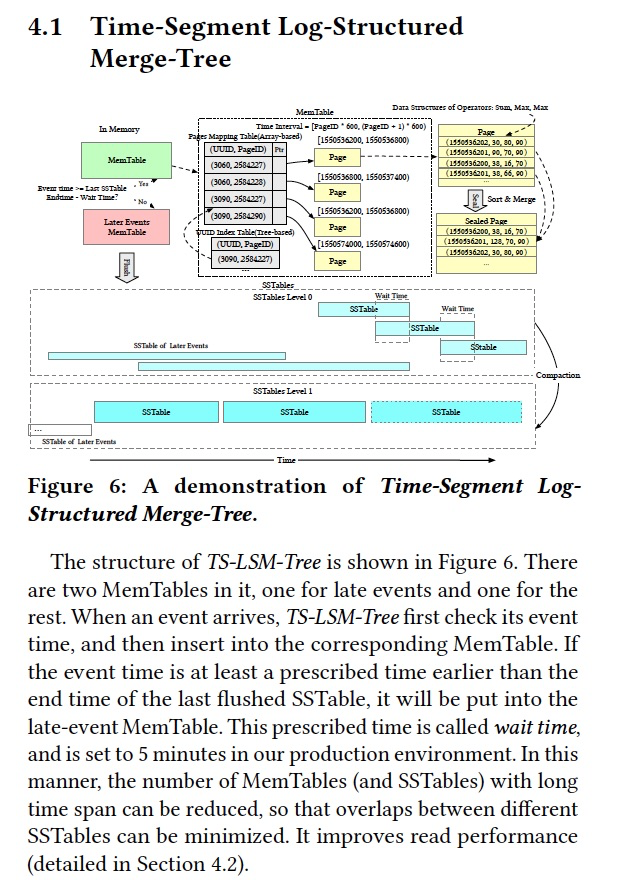
然后提出一个page的概念,600条records,一个UUID至少对应于一个page,一个page中的数据属于一个UUID,因为后面以page为维度要聚合
一个page写满,就会排序并聚合,这个取决于时间戳的精度,如果是秒级精度就按秒级聚合,聚合的算子定义的时候可以指定
这里sealed page的实现用数组,这样避免search的代价,因为根据数组的下标就可以直接找到相应的时间,
所以这里甚至不用事先排序,直接乱序插入即可,插入的过程本身就是排序的过程
有个问题是如果这里的时间是sparse的,那么数组中就会有很多的空洞,下面也说如果太过sparse那么就暂时不seal,多等一会,但这毕竟不是根本的解决方法。
这也是为何还需要一个late的内存表,
这里又有一个假设,就是写入的数据是在时间上dense的,这个对于监控数据而言是成立的

SSTable的存储结构
内存中的数据会定期的flush成SSTable,内存中的page对应于block
一个SSTable中包含很多block,按时间戳排序,并且没有overlap,这样可以精准查询,因为late单独存,所以没有overlap
这里在一个SSTable中,对每一个UUID会建立一个时间的线段树索引,即按时间维度聚合,便于long time span的查询

SSTable由如下组成,
首先是MetaZone,元数据,比如时间戳范围,这个meta非常小,所以可以将所有的meta都放在内存中
再者是所谓的bucket和collision,其实就是一个序列化的hash table,记录每个UUID的数据的时间戳范围和offset;
这个hash table也是用array来实现的,避免二分search;用uuid的hash找到index,如果冲突则使用64byte指向其他collided的UUID
最后是DataZone,这个是按UUID分开的,先存一个时间的线段树索引,接着是一堆的blocks


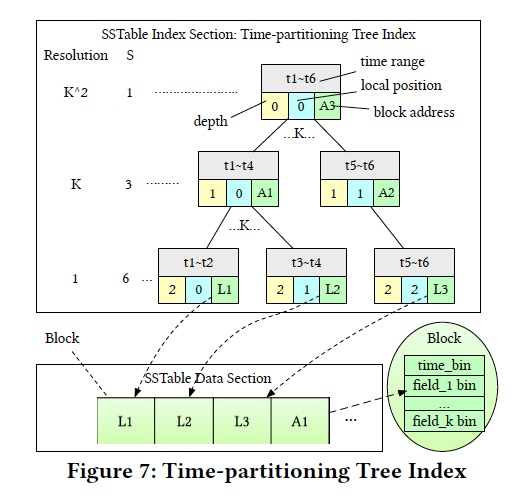
时间线段树
可以记录不同时间粒度的聚合数据,
这里做的优化是,这个线段树是用数组存储的,知道depth和local position,就可以计算出在数组的中的index