摘要
Hybrid Transactional and Analytical Processing (HTAP) databases require processing transactional and analytical queries in isolation to remove the interference between them.
(问题,要为AP和TP维护不同的副本)To achieve this, it is necessary to maintain different replicas of data specified for the two types of queries.
(挑战,副本间一致性,AP副本的fresh) However, it is challenging to provide a consistent view for distributed replicas within a storage system, where analytical requests can efficiently read consistent and fresh data from transactional workloads at scale and with high availability.
(Ideal)To meet this challenge, we propose extending replicated state machine-based consensus algorithms to provide consistent replicas for HTAP workloads.
(基于Ideal提出系统 )Based on this novel idea, we present a Raftbased HTAP database: TiDB. In the database, we design a multi-Raft storage system which consists of a row store and a column store.
The row store is built based on the Raft algorithm. It is scalable to materialize updates from transactional requests with high availability.
In particular, it asynchronously replicates Raft logs to learners which transform row format to column format for tuples, forming a real-time updatable column store.
This column store allows analytical queries to efficiently read fresh and consistent data with strong isolation from transactions on the row store.
(辅助的features)Based on this storage system, we build an SQL engine to process large-scale distributed transactions and expensive analytical queries. The SQL engine optimally accesses row-format and column-format replicas of data.
We also include a powerful analysis engine, TiSpark, to help TiDB connect to the Hadoop ecosystem.
(实验)Comprehensive experiments show that TiDB achieves isolated high performance under CH-benCHmark, a benchmark focusing on HTAP workloads.
Introduction
(趋势和现状)Relational database management systems (RDBMS) are popular with their relational model, strong transactional guarantees, and SQL interface. They are widely adopted in traditional applications, like business systems. However, old RDBMSs do not provide scalability and high availability.
(从RDBMS,NoSQL,NewSQL,AP谈现状)Therefore, at the beginning of the 2000s [11], internet applications preferred NoSQL systems like Google Bigtable [12] and DynamoDB [36].
NoSQL systems loosen the consistency requirements and provide high scalability and alternative data models, like key-value pairs, graphs, and documents.
However, many applications also need strong transactions, data consistency, and an SQL interface, so NewSQL systems appeared.
NewSQL systems like CockroachDB [38] and Google Spanner [14] provide the high scalability of NoSQL for Online Transactional Processing (OLTP) read/write workloads and still maintain ACID guarantees for transactions [32].
In addition, SQLbased Online Analytical Processing (OLAP) systems are being developed quickly, like many SQL-on-Hadoop systems [16].
These systems follow the “one size does not fit all” paradigm [37], using different data models and technologies for the different purposes of OLAP and OLTP.
However, multiple systems are very expensive to develop, deploy, and maintain. In addition, analyzing the latest version of data in real time is compelling.
(总结现状的问题,one size does not fit all,提出HTAP产生的原因,要大一统)This has given rise to hybrid OLTP and OLAP (HTAP) systems in industry and academia [30].
HTAP systems should implement scalability, high availability, and transnational consistency like NewSQL systems.
(什么是HTAP,需求是什么)Besides, HTAP systems need to efficiently read the latest data to guarantee the throughput and latency for OLTP and OLAP requests under two additional requirements: freshness and isolation.
(分析需求,Freshness,AP的副本如何读到最新数据)Freshness means how recent data is processed by the analytical queries [34]. Analyzing the latest data in real time has great business value.
But it is not guaranteed in some HTAP solutions, such as those based on an Extraction-Transformation-Loading (ETL) processing. Through the ETL process, OLTP systems periodically refresh a batch of the latest data to OLAP systems.
The ETL costs several hours or days, so it cannot offer real-time analysis. The ETL phase can be replaced by streaming the latest updates to OLAP systems to reduce synchronization time.
However, because these two approaches lack a global data governance model, it is more complex to consider consistency semantics. Interfacing with multiple systems introduces additional overhead.
(分析需求,Isolation,TP和AP的负载如何互不干扰)Isolation refers to guaranteeing isolated performance for separate OLTP and OLAP queries. Some in-memory databases (such as HyPer [18]) enable analytical queries to read the latest version of data from transactional processing on the same server.
Although this approach provides fresh data, it cannot achieve high performance for both OLTP and OLAP. This is due to data synchronization penalties and workload interference. This effect is studied in [34] by running CH-benCHmark [13], an HTAP benchmark on Hy-Per and SAP HANA.
The study found that when a system co-runs analytical queries, its maximum attainable OLTP throughput is significantly reduced. SAP HANA [22] throughput was reduced by at least three times, and HyPer by at least five times. Similar results are confirmed in MemSQL [24].
Furthermore, in-memory databases cannot provide high availability and scalability if they are only deployed on a single server.
To guarantee isolated performance, it is necessary to run OLTP and OLAP requests on different hardware resources. The essential difficulty is to maintain up-to-date replicas for OLAP requests from OLTP workloads within a single system.
Besides, the system needs to maintain data consistency among more replicates. Note that maintaining consistent replicas is also required for availability [29]. High availability can be achieved using well-known consensus algorithms, such as Paxos [20] and Raft [29].
They are based on replicated state machines to synchronize replicas. It is possible to extend these consensus algorithms to provide consistent replicas for HTAP workloads. To the best of our knowledge, this idea has not been studied before.
(基于分析提出方案,在RAFT中增加一个角色,Learner,不参加选举和决策,只是异步的同步数据,并且会把数据转化成利于查询的列存格式)
Following this idea, we propose a Raft-based HTAP database: TiDB.
It introduces dedicated nodes (called learners) to the Raft consensus algorithm. The learners asynchronously replicate transactional logs from leader nodes to construct new replicas for OLAP queries.
In particular, the learners transform the row-format tuples in the logs into column format so that the replicas are better-suited to analytical queries. Such log replication incurs little overhead on transactional queries running on leader nodes.
Moreover, the latency of such replication is so short that it can guarantee data freshness for OLAP. We use different data replicas to separately process OLAP and OLTP requests to avoid interference between them.
We can also optimize HTAP requests based on both row-format and column-format data replicas.
Based on the Raft protocol, TiDB provides high availability, scalability, and data consistency.
(提出contributions)We conclude our contributions as follows.
- We propose building an HTAP system based on consensus algorithms and have implemented a Raft-based HTAP database, TiDB. It is an open-source project [7] that provides high availability, consistency, scalability, data freshness, and isolation for HTAP workloads.
- We introduce the learner role to the Raft algorithm to generate a columnar store for real-time OLAP queries.
- We implement a multi-Raft storage system and optimize its read sand writes so that the system offers high performance when scaling to more nodes.
- We tailor an SQL engine for large-scale HTAP queries. The engine can optimally choose to use a row-based store and a columnar store.
- We conduct comprehensive experiments to evaluate TiDB’s performance about OLTP, OLAP, and HTAP using CH-benCHmark, an HTAP benchmark.
The remainder of this paper is organized as follows. We describe the main idea, Raft-based HTAP, in Section 2, and illustrate the architecture of TiDB in Section 3.
TiDB’s multi-Raft storage and HTAP engines are elaborated upon in Sections 4 and 5. Experimental evaluation is presented in Section 6. We summarize related work in Section 7.
Finally, we conclude our paper in Section 8.
RAFT-BASED HTAP
(详细描述Ideal,强调创新性是用一致性算法来构建HTAP数据库)Consensus algorithms such as Raft and Paxos are the foundation of building consistent, scalable, and highly-available distributed systems.
Their strength is that data is reliably replicated among servers in real time using the replicated state machine.
We adapt this function to replicate data to different servers for different HTAP workloads.
In this way, we guarantee that OLTP and OLAP workloads are isolated from each other, but also that OLAP requests have a fresh and consistent view of the data.
To the best of our knowledge, there is no previous work to use these consensus algorithms to build an HTAP database.
Since the Raft algorithm is designed to be easy to understand and implement, we focus on our Raft extension on implementing a production-ready HTAP database.
As illustrated in Figure 1, at a high level, our ideas are as follows:

(描述Learner)Data is stored in multiple Raft groups using row format to serve transactional queries.
Each group is composed of a leader and followers. We add a learner role for each group to asynchronously replicate data from the leader.
This approach is low-overhead and maintains data consistency. Data replicated to learners are transformed to column-based format.
Query optimizer is extended to explore physical plans accessing both the row-based and column-based replicas.
In a standard Raft group, each follower can become the leader to serve read and write requests.
Simply adding more followers, therefore, will not isolate resources.
Moreover, adding more followers will impact the performance of the group because the leader must wait for responses from a larger quorum of nodes before responding to clients.
Therefore, we introduced a learner role to the Raft consensus algorithm. A learner does not participate in leader elections, nor is it part of a quorum for log replication.
Log replication from the leader to a learner is asynchronous; the leader does not need to wait for success before responding to the client. The strong consistency between the leader and the learner is enforced during the read time.
By design, the log replication lag between the leader and learners is low, as demonstrated in the evaluation section.
(行存和列存的分析,提出行列混存的方案)Transactional queries require efficient data updates, while analytical queries such as join or aggregation require reading a subset of columns, but a large number of rows for those columns.
Row-based format can leverage indexes to efficiently serve transactional queries. Column-based format can leverage data compression and vectorized processing efficiently.
Therefore, when replicating to Raft learners, data is transformed from row-based format to column-based format.
Moreover, learners can be deployed in separate physical resources. As a result, transaction queries and analytical queries are processed in isolated resources.
Our design also provides new optimization opportunities. Because data is kept consistent between both the row-based format and column-based format, our query optimizer can produce physical plans which access either or both stores.
We have presented our ideas of extending Raft to satisfy the freshness and isolation requirements of an HTAP database.
(实现这个ideal,面临的工程上的挑战)
To make an HTAP database production ready, we have overcome many engineering challenges, mainly including:
(1) (如果满足高并发读写)How to build a scalable Raft storage system to support highly concurrent read/write?
If the amount of data exceeds the available space on each node managed by the Raft algorithm, we need a partition strategy to distribute data on servers.
Besides, in the basic Raft process, requests are processed sequentially, and any request must be approved by the quorum of Raft nodes before responding to clients.
This process involves network and disk operations, and thus is time-consuming. This overhead makes the leader become a bottleneck to processing requests, especially on large datasets
(2) (如何保证同步低延迟)How to synchronize logs into learners with low latency to keep data fresh? Undergoing transactions can generate some very large logs.
These logs need to be quickly replayed and materialized in learners so that the fresh data can be read. Transforming log data into column format may encounter errors due to mismatched schemas.
This may delay log synchronization.
(3) (如何有效执行TP和AP)How to efficiently process both transactional and analytical queries with guaranteed performance?
Large transactional queries need to read and write huge amounts of data distributed in multiple servers.
Analytical queries also consume intensive resources and should not impact online transactions.
To reduce execution overhead, they also need to choose optimal plans on both a row-format store and a column-format store.
在下面的章节,主要围绕这几个工程的问题进行阐述
In the following sections, we will elaborate the design and implementation of TiDB to address these challenges.
ARCHITECTURE
In this section, we describe the high-level structure of TiDB, which is illustrated in Figure 2.

TiDB supports the MySQL protocol and is accessible by MySQL-compatible clients.
It has three core components: a distributed storage layer, a Placement Driver (PD), and a computation engine layer.
(存储层,TiKV和TiFlash)The distributed storage layer consists of a row store (TiKV) and a columnar store (TiFlash). Logically, the data stored in TiKV is an ordered key-value map.
Each tuple is mapped into a key-value pair. The key is composed of its table ID and row ID, and the value is the actual row data, where the table ID and row ID are unique integers, and the row ID would be from a primary key column.
For example, a tuple with four columns is encoded as:
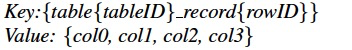
To scale out, we take a range partition strategy to split the large keyvalue map into many contiguous ranges, each of which is called a Region(分区).
Each Region has multiple replicas for high availability. The Raft consensus algorithm is used to maintain consistency among replicas for each Region, forming a Raft group.
The leaders of different Raft groups asynchronously replicate data from TiKV to TiFlash. TiKV and TiFlash can be deployed in separate physical resources and thus offer isolation when processing transactional and analytical queries.
(管控层,由于要支持事务,负责提供全局时间戳,保序) Placement Driver (PD) is responsible for managing Regions, including supplying each key’s Region and physical location, and automatically moving Regions to balance workloads.
PD is also our timestamp oracle, providing strictly increasing and globally unique timestamps. These timestamps also serve as our transaction IDs.
PD may contain multiple PD members for robustness and performance. PD has no persistent state, and on startup a PD member gathers all necessary data from other members and TiKV nodes.
(计算层)The computation engine layer is stateless and is scalable. Our tailored SQL engine has a cost-based query optimizer and a distributed query executor.
TiDB implements a two-phase commit (2PC) protocol based on Percolator [33] to support transactional processing.
The query optimizer can optimally select to read from TiKV and TiFlash based on the query.
(架构总结)The architecture of TiDB meets the requirement of an HTAP database.
Each component of TiDB is designed to have high availability and scalability.
The storage layer uses the Raft algorithm to achieve consistency between data replicas. The low latency replication between the TiKV and TiFlash makes fresh data available to analytical queries.
The query optimizer, together with the strongly consistent data between TiKV and TiFlash, offers fast analytical query processing with little impact on transactional processing.
Besides the components mentioned above, TiDB also integrates with Spark, which is helpful to integrate data stored in TiDB and the Hadoop Distributed File System (HDFS).
TiDB has a rich set of ecosystem tools to import data to and export data from TiDB and migrate data from other databases to TiDB.
In the following sections, we will do a deep dive on the distributed storage layer, the SQL engine, and TiSpark to demonstrate the capability of TiDB, a production-ready HTAP database.
MULTI-RAFT STORAGE
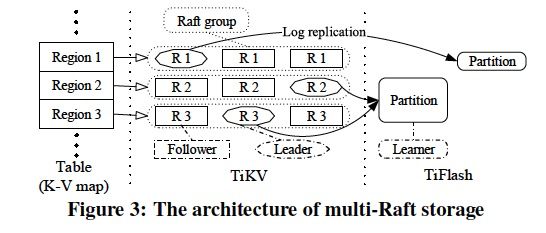
(存储层概述)Figure 3 shows the architecture of the distributed storage layer in TiDB, where the objects with the same shape play the same role.
The storage layer consists of a row-based store, TiKV, and a column-based store, TiFlash.
The storage maps a large table into a big key-value map which is split into many Regions stored in TiKV.
Each Region uses the Raft consensus algorithm to maintain the consistency among replicas to achieve high availability.
Multiple Regions can be merged into one partition when data is replicated to TiFlash to facilitate table scan. (Partition指的是TIFlash中的分区,对应于一个或多个Regions,便于scan)
The data between TiKV and TiFlash is kept consistent through asynchronous log replication.
Since multiple Raft groups manage data in the distributed storage layer, we call it multi-Raft storage. (有点强行multi)
In the following sections, we describe TiKV and TiFlash in detail, focusing on optimizations to make TiDB a production-ready HTAP database.
Rowbased Storage (TiKV)
(TiKV底层重用了RocksDB,Region固定大小96M)A TiKV deployment consists of many TiKV servers. Regions are replicated between TiKV servers using Raft.
Each TiKV server can be either a Raft leader or follower for different Regions.
On each TiKV server, data and metadata are persisted to RocksDB, an embeddable, persistent, key-value store [5].
Each Region has a configurable max size, which is 96 MB by default. The TiKV server for a Raft leader handles read/write requests for the corresponding Region.
(RAFT标准流程,串行提交,吞吐受限)When the Raft algorithm responds to read and write requests, the basic Raft process is executed between a leader and its followers:
(1) A Region leader receives a request from the SQL engine layer.
(2) The leader appends the request to its log.
(3) The leader sends the new log entries to its followers, which in turn append the entries to their logs.
(4) The leader waits for its followers to respond. If a quorum of nodes respond successfully, then the leader commits the request and applies it locally.
(5) The leader sends the result to the client and continues to process incoming requests.
This process ensures data consistency and high availability.
However, it does not provide efficient performance because the steps happen sequentially, and may incur large I/O overheads (both diskand network).
The following sections describe how we have optimized this process to achieve high read/write throughput, i.e., solving the first challenge described in Section 2.
Optimization between Leaders and Followers
In the process described above,
(2,3步并行,写盘的时候,同时发给followers)the second and third steps can happen in parallel because there is no dependency between them. Therefore, the leader appends logs locally and sends logs to followers at the same time.
If appending logs fails on the leader but a quorum of the followers successfully append the logs, the logs can still be committed.
(3步,buffer并且batch同步)In the third step, when sending logs to followers, the leader buffers log entries and sends them to its followers in batches.
(不等followers返回,默认成功,继续发送)After sending the logs, the leader does not have to wait for the followers to respond. Instead, it can assume success and send further logs with the predicted log index.
If errors occur, the leader adjusts the log index and resends the replication requests.
(异步apply)In the fourth step, the leader applying committed log entries can be handled asynchronously by a different thread because at this stage there is no risk to consistency.
Based on the optimizations above, the Raft process is updated as follows:
(1) A leader receives requests from the SQL engine layer.
(2) The leader sends corresponding logs to followers and appends logs locally in parallel.
(3) The leader continues to receive requests from clients and repeats step (2).
(4) The leader commits the logs and sends them to another thread to be applied.
(5) After applying the logs, the leader returns the results to the client.
In this optimal process, any request from a client still runs all the Raft steps, but requests from multiple clients are run in parallel, so the overall throughput increases.
Accelerating Read Requests from Clients
Reading data from TiKV leaders is provided with linearizable semantics.
This means when a value is read at time t from a Region leader, the leader must not return a previous version of the value for read requests after t.
This can be achieved by using Raft as described above:
issuing a log entry for every read request and waiting for that entry to be committed before returning.
However, this process is expensive because the log must be replicated across the majority of nodes in a Raft group, incurring the overhead of network I/O.
To improve performance, we can avoid the log synchronization phase.
Raft guarantees that once the leader successfully writes its data, the leader can respond to any read requests without synchronizing logs across servers.
However, after a leader election, the leader role may be moved between servers in a Raft group. To achieve reading from leaders, TiKV implements the following read optimizations as described in [29].
The first approach is called read index.
When a leader responds to a read request, it records the current commit index as a local read index, and then sends heartbeat messages to followers to confirm its leader role.
If it is indeed the leader, it can return the value once its applied index is greater than or equal to the read index.
This approach improves read performance, though it causes a little network overhead.
Another approach is lease read, which reduces the network overhead of heartbeats caused by the read index.
The leader and followers agree on a lease period, during which followers do not issue election requests so that the leader is not changed.
During the lease period, the leader can respond to any read request without connecting to its followers.
This approach works well if the CPU clock on each node does not differ very much.
In addition to the leader, followers can also respond to read requests from clients, which is called follower read.
After a follower receives a read request, it asks the leader for the newest read index.
If the locally-applied index is equal to or greater than the read index, the follower can return the value to the client; otherwise, it has to wait for the log to be applied.
Follower read can alleviate the pressure on the leader of a hot Region, thus improving read performance.
Read performance can then be further improved by adding more followers.
Managing Massive Regions
Massive Regions are distributed on a cluster of servers.
The servers and data size are dynamically changing, and Regions may cluster in some servers, especially leader replicas.
This causes some servers’ disks to become overused, while others are free. In addition, servers may be added to or moved from the cluster.
To balance Regions across servers, the Plancement Driver (PD) schedules Regions with constraints on the number and location of replicas.
One critical constraint is to place at least three replicas of a Region on different TiKV instances to ensure high availability.
PD is initialized by collecting specific information from servers through heartbeats. It also monitors the workloads of each server and migrates hot Regions to different servers without impacting applications.
On the other hand, maintaining massive Regions involves sending heartbeats and managing metadata, which can cause a lot of network and storage overhead.
However, if a Raft group does not have any workloads, the heartbeat is unnecessary.
Depending on how busy the Regions’ the workloads are, we can adjust the frequency of sending heartbeats.
This reduces the likelihood of running into issues like network latency or overloaded nodes.
Dynamic Region Split and Merge
(描述Region Split和Merge的过程,也是作为command由raft进行同步)
A large Region may become too hot to be read or written in a reasonable time.
Hot or large Regions should be split into smaller ones to better distribute workload. On the other hand, it is possible that many Regions are small and seldom accessed;
however, the system still needs to maintain the heartbeat and metadata. In some cases, maintaining these small Regions incurs significant network and CPU overhead.
Therefore, it is necessary to merge smaller Regions. Note that to maintain the order between Regions, we only merge adjacent Regions in the key space.
Based on observed workloads, PD dynamically sends split and merge commands to TiKV.
A split operation divides a Region into several new, smaller Regions, each of which covers a continuous range of keys in the original Region.
The Region that covers the rightmost range reuses the Raft group of the original Region. Other Regions use new Raft groups.
The split process is similar to a normal update request in the Raft process:
(1) PD issues a split command to the leader of a Region.
(2) After receiving the split command, the leader transforms the command into a log and replicates the log to all its follower nodes. The log only includes a split command, instead of modifying actual data.
(3) Once a quorum replicates the log, the leader commits the split command, and the command is applied to all the nodes in the Raft group.
The apply process involves updating the original Region’s range and epoch metadata, and creating new Regions to cover the remaining range. Note that the command is applied atomically and synced to disk.
(4) For each replica of a split Region, a Raft state machine is created and starts to work, forming a new Raft group. The leader of the original Region reports the split result to PD. The split process completes.
Note that the split process succeeds when a majority of nodes commit the split log. Similar to committing other Raft logs, rather than requiring all nodes to finish splitting the Region.
After the split, if the network is partitioned, the group of nodes with the most recent epoch wins.
The overhead of region split is low as only metadata change is needed. After a split command finishes, the newly split Regions may be moved across servers due to PD’s regular load balancing.
Merging two adjacent Regions is the opposite of splitting one.
PD moves replicas of the two Regions to colocate them on separate servers.
Then, the colocated replicas of the two Regions are merged locally on each server through a two-phase operation; that is, stopping the service of one Region and merging it with another one.
This approach is different from splitting a Region, because it cannot use the log replication process between two Raft groups to agree on merging them.
Column-based Storage (TiFlash)
Even though we optimize reading data from TiKV as described above, the row-format data in TiKV is not well-suited for fast analysis.
Therefore, we incorporate a column store (TiFlash) into TiDB. TiFlash is composed of learner nodes, which just receive Raft logs from Raft groups and transform row-format tuples into columnar data.
They do not participate in the Raft protocols to commit logs or elect leaders so they induce little overhead on TiKV.
A user can set up a column-format replica for a table using an SQL statement:
ALTER TABLE x SET TiFLASH REPLICA n;
where x is the name of the table and n is the number of replicas. The default value is 1.
Adding a column replica resembles adding an asynchronous columnar index to a table.
Each table in TiFlash is divided into many partitions, each of which covers a contiguous range of tuples, in accordance with several continuous Regions from TiKV.
The larger partition facilitates range scan.
When initializing a TiFlash instance, the Raft leaders of the relevant Regions begin to replicate their data to the new learners.
If there is too much data for fast synchronization, the leader sends a snapshot of its data.
Once initialization is complete, the TiFlash instance begins listening for updates from the Raft groups.
After a learner node receives a package of logs, it applies the logs to the local state machine, including replaying the logs, transforming the data format, and updating the referred values in local storage.
In the following sections, we illustrate how TiFlash efficiently applies logs and maintains a consistent view with TiKV.
This meets the second challenge we described in Section 2.
Log Replayer
(Replay的过程,分为Compact,Decode,Columnar三步)In accordance with the Raft algorithm, the logs received by learner nodes are linearizable.
To keep the linearizable semantics of committed data, they are replayed according to a first-in, first-out (FIFO) strategy. The log replay has three steps:
(1) Compacting logs: According to the transaction model described in later Section 5.1, the transactional logs are classified into three statuses: prewritten, committed, or rollbacked.
The data in the rollbacked logs does not need to be written to disks, so a compact process deletes invalid prewritten logs according to rollbacked logs and puts valid logs into a buffer.
(2) Decoding tuples: The logs in the buffer are decoded into rowformat tuples, removing redundant information about transactions. Then, the decoded tuples are put into a row buffer.
(3) Transforming data format: If the data size in the row buffer exceeds a size limit or its time duration exceeds a time interval limit,
these row-format tuples are transformed to columnar data and are written to a local partition data pool.
Transformation refers to local cached schemas, which are periodically synchronized with TiKV as described later.
To illustrate the details of the log replay process, consider the following example.
We abstract each Raft log item as transaction ID-operation type[transaction status][@start ts][#commit ts]operation data.
According to typical DMLs, the operation type includes inserting, updating, and deleting tuples.
Transactional status may be prewritten, committed, or rollbacked. Operation data may be a specifically-inserted or updated tuple, or a deleted key.

In our example shown in Table 1, the raw logs contain eight items which attempt to insert two tuples, update one tuple, and delete one tuple.
But inserting k1 is rolled back, so only six of the eight raw log items are preserved, from which three tuples are decoded.
Finally, the three decoded tuples are transformed into five columns: operation types, commit timestamps, keys, and two columns of data.
These columns are appended to the DeltaTree.
Columnar Delta Tree
(总体思路和LSM-tree差不多,实现有所不同,为了检索Delta加了B-tree索引,merge没有分level,直接merge到chunk上,chunk等同于row group)
To efficiently write and read the columnar data with high throughput, we design a new columnar storage engine, DeltaTree, which appends delta updates immediately and later merges them with the previously stable version for each partition.
The delta updates and the stable data are stored separately in the DeltaTree, as shown in Figure 4.
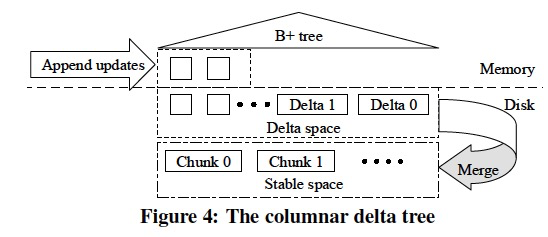
In the stable space, partition data is stored as chunks, and each of them covers a smaller range of the partition’s tuples.
Moreover, these row-format tuples are stored column by column. In contrast, deltas are directly appended into the delta space in the order TiKV generates them.
The store format of columnar data in TiFlash is similar to Parquet [4]. It also stores row groups into columnar chunks.
Differently, TiFlash stores column data of a row group and its metadata to different files to concurrently update files, instead of only one file in Parquet.
TiFlash just compresses data files using the common LZ4 [2] compression to save their disk size.
New incoming deltas are an atomic batch of inserted data or a deleted range. These deltas are cached into memory and materialized into disks.
They are stored in order, so they achieve the function of a write-ahead log (WAL). These deltas are usually stored in many small files and therefore induce large IO overhead when read.
To reduce cost, we periodically compact these small deltas into a larger one, then flush the larger deltas to disks and replace the previously materialized small deltas.
The in-memory copy of incoming deltas facilitates reading the latest data, and if the old deltas reach a limited size, they are removed.
When reading the latest data of some specific tuples, it is necessary to merge all delta files with their stable tuples (i.e., read amplification),
because where the related deltas distribute is not known in advance. Such a process is expensive due to reading a lot of files.
In addition, many delta files may contain useless data (i.e., space amplification) that wastes storage space and slows down merging them with stable tuples.
Therefore, we periodically merge the deltas into the stable space. Each delta file and its related chunks are read into memory and merged. Inserted tuples in deltas are added into the stable, modified tuples replace the original tuples, and deleted tuples are moved.
The merged chunks atomically replace original chunks in disks. Merging deltas is expensive because the related keys are disordered in the delta space.
Such disorder also slows down integrating deltas with stable chunks to return the latest data for read requests.
Therefore, we build a B+ tree index on the top of the delta space.
Each delta item of updates is inserted into the B+ tree ordered by its key and timestamp.
This order priority helps to efficiently locate updates for a range of keys or to look up a single key in the delta space when responding to read requests.
Also, the ordered data in the B+ tree is easy to merge with stable chunks.
We conduct a micro-experiment to compare the DeltaTree’s performance to the log-structured-merge (LSM) tree [28] in TiFlash, where data is read as it is updated according to Raft logs.
We set three TiKV nodes and one TiFlash node, and the hardware configurations are listed in the experimental section.
We run the only write workload of Sysbench [6] on TiKV and run “select count(id), count(k) from sbtest1” on TiFlash.
To avoid the large write amplification of data compaction, we implement the LSM storage engine using a universal compaction, rather than a level style compaction.
This implementation is also adopted in ClickHouse [1], a columnoriented OLAP database.
As shown in Table 2, reading from the delta tree is about two times faster than the LSM tree, regardless of whether there are 100 or 200 million tuples, as well as the transactional workloads.
This is because in the delta tree each read accesses at most one level of delta files that are indexed in a B+ tree, while it accesses more overlapped files in the LSM tree.
The performance remains almost stable under different write workloads because the ratio of delta files is nearly the same. Although the write amplification of DeltaTree (16.11) is greater than the LSM tree (4.74), it is also acceptable.
EXPERIMENTS
(先说下要测哪些)In this section, we first separately evaluate TiDB’s OLTP and OLAP ability.
For OLAP, we investigate the SQL engine’s ability to choose TiKV and TiFlash, and compare TiSpark to other OLAP systems.
Then, we measure TiDB’s HTAP performance, including the log replication delay between TiKV and TiFlash.
Finally, we compare TiDB to MemSQL in terms of isolation.
Experimental Setup
(集群情况)Cluster.
We perform comprehensive experiments on a cluster of six servers; each has 188 GB memory and two Intel R Xeon R CPU E5-2630 v4 processors, i.e., two NUMA nodes.
Each processor has 10 physical cores (20 threads) and a 25 MB shared L3 cache.
The servers run Centos version 7.6.1810 and are connected by a 10 Gbps Ethernet network.
(负载情况)Workload.
Our experiments are conducted under a hybrid OLTP and OLAP workload using CH-benCHmark. Source code is published online [7].
The benchmark is composed of standard OLTP and OLAP benchmarks: TPC-C and TPC-H.
It is built from the unmodified version of the TPC-C benchmark.
The OLAP part contains 22 analytical queries inspired by TPC-H, whose schema is adapted from TPC-H to the CH-benCHmark schema, plus three missing TPC-H relations.
At run time, the two workloads are issued simultaneously by multiple clients; the number of clients is varied in the experiments.
Throughput is measured in queries per second (QPS) or transactions per second (TPS), respectively. The unit of data in CH-benCHmark is called a warehouse, the same with TPC-C. 100 warehouses take about 70 GB of memory.
。。。。。。
RELATED WORK
Common approaches for building HTAP systems are: evolving from an existing database, extending an open source analytical system, or building from scratch.
TiDB is built from scratch and differs from other systems in architecture, data origination, computation engines, and consistency guarantees.
Evolving from an existing database.
Mature databases can provide HTAP solutions based on existing products, and they especially focus on accelerating analytical queries.
They take custom approaches to separately achieve data consistency and high availability.
In contrast, TiDB naturally benefits from the log replication in the Raft to achieve data consistency and high availability.
Oracle [19] introduced the Database In-Memory option in 2014 as the industry’s first dual-format, in-memory RDBMS.
This option aims to break performance barriers in analytic query workloads without compromising (or even improving) performance of regular transactional workloads.
The columnar storage is a readonly snapshot, consistent at a point in time, and it is updated using a fully-online repopulation mechanism.
Oracle’s later work [27] presents the high availability aspects of its distributed architecture and provides fault-tolerant analytical query execution.
SQL Server [21] integrates two specialized storage engines into its core: the Apollo column storage engine for analytical workloads and the Hekaton in-memory engine for transactional workloads.
Data migration tasks periodically copy data from the tail of Hekaton tables into the compressed column store.
SQL Server uses column store indexes and batch processing to efficiently process analytical queries, utilizing SIMD [15] for data scans.
SAP HANA supports efficiently evaluating separate OLAP and OLTP queries, and uses different data organizations for each.
To scale OLAP performance, it asynchronously copies row-store data to a columnar store distributed on a cluster of servers [22]. This approach provides MVCC data with sub-second visibility.
However, it requires a lot of effort to handle errors and keep data consistent. Importantly, the transactional engine lacks high availability because it is only deployed on a single node.
Transforming an open-source system.
Apache Spark is an open-source framework for data analysis. It needs a transactional module to achieve HTAP.
Many systems listed below follow this idea. TiDB does not deeply depend on Spark, as TiSpark is an extension.
TiDB is an independent HTAP database without TiSpark.
Wildfire [10, 9] builds an HTAP engine based on Spark. It processes both analytical and transactional requests on the same columnar data organization, i.e., Parquet.
It adopts last-write-wins semantics for concurrent updates and snapshot isolation for reads.
For high availability, shard logs are replicated to multiple nodes without help from consensus algorithms. Analytical queries and transactional queries can be processed on separate nodes;
however, there is a noticeable delay in processing the newest updates. Wildfire uses a unified multi-version and multi-zone indexing method for large-scale HTAP workloads [23].
SnappyData [25] presents a unified platform for OLTP, OLAP, and stream analytics.
It integrates a computational engine for high throughput analytics (Spark) with a scale-out, in-memory transactional store (GemFire).
Recent updates are stored in row format, and then age into a columnar format for analytical queries.
Transactions follow a 2PC protocol using GemFire’s Paxos implementation to ensure consensus and a consistent view across the cluster.
Building from scratch.
Many new HTAP systems have investigated different aspects of hybrid workloads, which include utilizing in-memory computing to improve performance, optimal data storage, and availability.
Unlike TiDB, they cannot provide high availability, data consistency, scalability, data freshness, and isolation at the same time.
MemSQL [3] has an engine for both scalable in-memory OLTP and fast analytical queries.
MemSQL can store database tables either in row or column format. It can keep some portion of data in row format and convert it to columnar format for fast analysis when writing data to disks.
It compiles repeat queries into low-level machine code to accelerate analytic queries, and it uses many lockfree structures to aid transactional processing.
However, it cannot provide isolated performance for OLAP and OLTP when running HTAP workloads.
HyPer [18] used the operating system’s fork system call to provide snapshot isolation for analytical workloads.
Its newer versions adopt an MVCC implementation to offer serializability, fast transaction processing, and fast scans.
ScyPer [26] extends HyPer to evaluate analytical queries at scale on remote replicas by propagating updates either using a logical or physical redo log.
BatchDB [24] is an in-memory database engine designed for HTAP workloads. It relies on primary-secondary replication with dedicated replicas, each optimized for a particular workload type (i.e., OLTP or OLAP).
It minimizes load interaction between the transactional and analytical engines, thus enabling real-time analysis over fresh data under tight SLAs for HTAP workloads.
Note that it executes analytical queries on row-format replicas and does not promise high availability.
Lineage-based data store (L-Store) [35] combines real-time analytical and transactional query processing within a single unified engine by introducing an update-friendly, lineage-based storage architecture.
The storage enables a contention-free update mechanism over a native, multi-version columnar storage model in order to lazily and independently stage stable data from a write-optimized columnar format into a read-optimized columnar layout.
Peloton [31] is a self-driving SQL database management system.
It attempts to adapt data origination [8] for HTAP workloads at run time. It uses lock-free, multi-version concurrency control to support real-time analytics.
However, it is a single-node, in-memory database by design.
Cockroach DB [38] is a distributed SQL database which offers high availability, data consistency, scalability, and isolation.
Like TiDB it is built on top of the Raft algorithm and supports distributed transactions. It offers a stronger isolation property: serializability, rather than snapshot isolation.
However, it does not support dedicated OLAP or HTAP functionality.
CONCLUSION
We have presented a production-ready, HTAP database: TiDB.
TiDB is built on top of TiKV, a distributed, row-based store, which uses the Raft algorithm.
We introduce columnar learners for realtime analysis, which asynchronously replicate logs from TiKV, and transform row-format data into column format.
Such log replication between TiKV and TiFlash provides real-time data consistency with little overhead.
TiKV and TiFlash can be deployed on separate physical resources to efficiently process both transactional and analytical queries.
They can be optimally chosen by TiDB to be accessed when scanning tables for both transactional and analytical queries.
Experimental results show TiDB performs well under an HTAP benchmark, CH-benCHmark.
TiDB provides a generic solution to evolve NewSQL systems into HTAP systems.