开篇说的是,Shared-nothing当前已经是主流的架构,需要用自身的local disks来存储数据,Tables被水平划分到各个partitions上
这种架构,比较适合star-schema,即事实表外只有一层维表,这样join会比较简单,可以把维表广播,避免大量的数据传输
这个架构的主要问题就是,计算和存储没有分离
带来的问题,他说了几点,我的理解主要是,
首先资源利用会不合理,因为存储和计算任意资源不足,都需要增加节点,而且各个节点上很容易产生热点,热点打散比较麻烦,因为需要分割数据
最关键的是,这个架构在每个node上都有状态,存在本地磁盘,需要保证一致性
扩缩容非常的麻烦,有可能需要迁移数据和分割数据,这个成本非常的高

这篇文章的主要的思想,就是做了计算和存储分离
数据直接放到S3上,
那么本地磁盘仅仅用于cache

Snowflake整体的架构分3层,

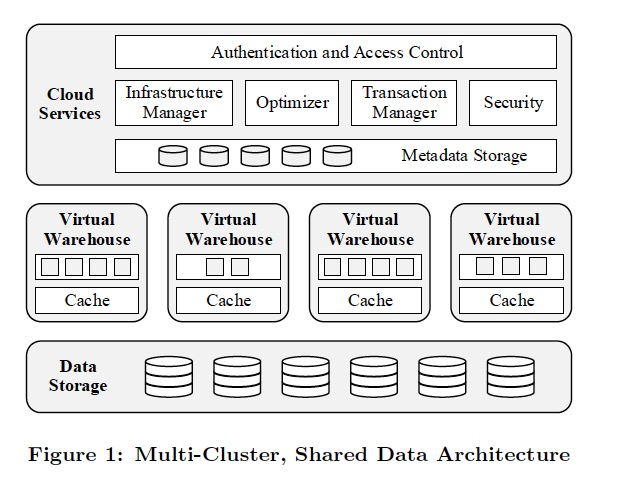
Data Strorage
数据主存储用的是S3,会有更高的延迟,更大cpu消耗,尤其是用https的时候
而且S3是对象存储,无法append,当然读的时候是可以读部分数据
Compared to local storage, S3 naturally has a much higher access latency and there is a higher CPU overhead associated with every single I/O request, especially if HTTPS connections are used.
But more importantly, S3 is a blob store with a relatively simple HTTP(S)-based PUT/GET/DELETE interface. Objects i.e. les can only be (over-)written in full. It is not even possible to append data to the end of a le.
In fact, the exact size of a le needs to be announced up-front in the PUT request. S3 does, however, support GET requests for parts (ranges) of a le.
Snowflake把table分成large immutable files,列存格式,高压缩,有header
但没解释如何解决append的问题,高延迟的问题
S3还会作为临时存储放中间结果
Meta是放在KV里面,这部分属于管控

Virtual Warehouses
计算节点,因为存储分离出去了,所以这里纯粹的计算节点
用EC2组成cluster,作为一个VW,用户只能感知到VW,不知道底下有多少ec2的worker node
这里为了便于用户理解,规格直接用类似T-shirt的,X,XXL,很形象

VM是无状态的,纯计算资源
所以这样设计就很简单了,快速扩缩容,failover
用户可以有多个VM,但是底下针对一个相同的存储,VM之间资源是隔离的,所以可以做到不同的query间不干扰
Worker只有在真正查询的时候,才会启动查询进程

为了降低读取S3的延时,在本地磁盘对读取过的文件做了cache,会cache header和读取过的column的数据,这里就采用的比较简单LRU策略
为了让cache更有效,要保证需要读取相同数据的query被分发到相同的worker node,所以这里采用一致性hash来分发query
这里一致性hash是lazy的,意思就是不会搬数据,因为本身cache,所以无所谓,变了就重新建cache,老的等LRU过期
由于Worker是纯计算节点,数据都在S3,所以他处理skew,数据倾斜问题就非常简单,我做完了,可以帮peer做他没有做完的;如果是share-nothing就比较麻烦了,数据倾斜是很讨厌的问题

ExecutionEngine
高效的执行引擎,
基于Columnar,可以更好的利用CPU和SIMD
向量化,不会物化中间结果,采用pipiline的方式,参考MonetDB的设计
Push,operator间通过push,streaming的方式

Cloud Services
管控服务,
多租户共用,每个service都是长生命周期和shared,保证高可用和可扩展

查询管理和优化
所有查询都需要通过CloudService,并会在这完成parsing,optimization的阶段
这里优化用的是Top-down Cascades的方式
由于Snowflake没有index,而且把一些优化放到了执行阶段,比如join数据的分布,所以搜索空间大大降低,同时提升了优化的稳定性
其实说白了,弱化了查询优化部分,把部分工作放到执行引擎中
然后后面就是典型的MPP的过程,把执行计划下发到各个workers,并监控和统计执行状况

并发控制
通过Snapshot Isolation来实现事务机制
这里SI是通过MVCC实现的,这是一个自然的选择,对于S3只能整个替换files,每个table version对应于哪些file,由在kv中的metadata管理

传统的数据库,通过索引来检索数据,这里说索引的问题,比如随机读写,overload重,需要显式创建
所以对于AP场景,一般不会选择建B tree这样的索引,而选择顺序扫描数据,所以才有pruning的问题
如果要高效的pruning,需要知道这块数据到底需不需要扫描,是否可以跳过,所以会在header中加上很多的统计,min,max等

4. Feature Highlights
Pure Software-as-a-Service Experience
Continuous Availability,存储和计算分离后,数据的一致性交给S3来保证,只需要保证无状态的计算节点的高可用,没有什么好说的
Semi-Structured and Schema-Less Data
Time Travel and Cloning,由于mvcc,旧版本不删除,自然就支持Time Travel
Security
这篇论文,除了给出计算和存储分离的架构,没有特别的创新的地方,其他的技术都是common sense,在计算和存储分离部分的细节也没有详细描述