https://zhuanlan.zhihu.com/p/40208895 Mysql的MVCC实现
https://severalnines.com/database-blog/comparing-data-stores-postgresql-mvcc-vs-innodb
第一种实现方式是将数据记录的多个版本保存在数据库中,当这些不同版本数据不再需要时,垃圾收集器回收这些记录。这个方式被PostgreSQL和Firebird/Interbase采用,SQL Server使用的类似机制,所不同的是旧版本数据不是保存在数据库中,而保存在不同于主数据库的另外一个数据库tempdb中
第二种实现方式只在数据库保存最新版本的数据,但是会在使用undo时动态重构旧版本数据,这种方式被Oracle和MySQL/InnoDB使用。
参考,An Empirical Evaluation of In-Memory Multi-Version Concurrency Control
Andy号称是关于MVCC最好的paper
MVCC也是一个很老的技术,
主要目的,就是让读写互不干扰,这样读写之间不用加锁,可以简单的增大并发
使用MVCC达到的隔离级别,是Snapshot Isolation,SI,如果要实现serializable,需要额外做一些事情



虽然各个数据库当前都采用MVCC,但具体设计和实现却各不相同
MVCC设计和实现要考虑的点主要如下四点,
Concurrency Control Protocol
Version Storage
Garbage Collection
Index Management
Concurrency Control Protocol
并发控制方法,主要如下3种,

为了支持MVCC,Tuple的格式如下,
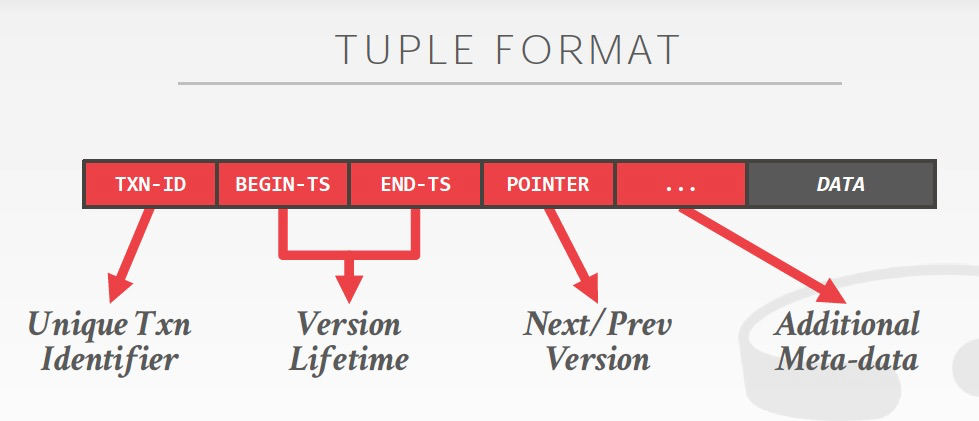
先看MVTO,
对于MVTO,关键的meta是Read-Ts,用于表示最新一次读取的id
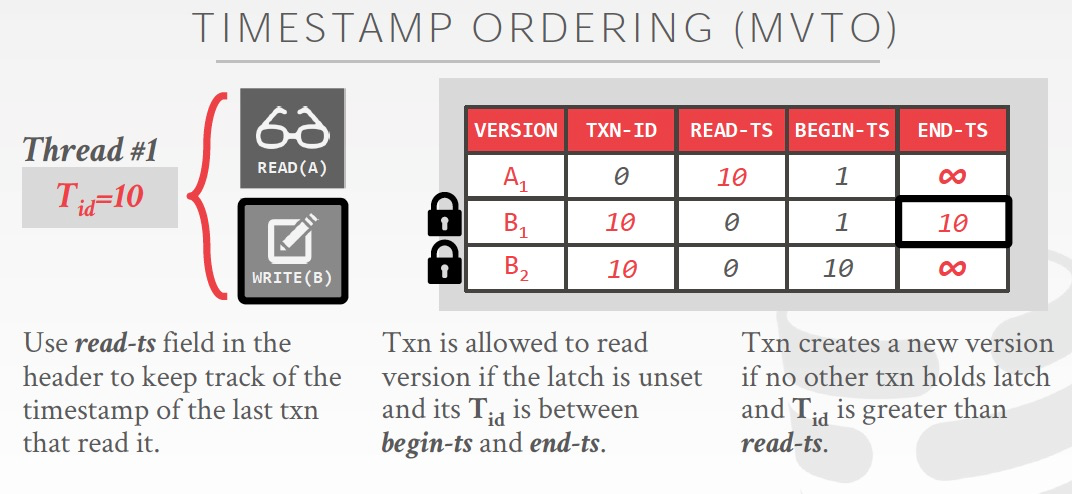
读写的过程如下,
读的时候,需要更新read-ts到10,那么小于10的write不能更新
写的时候,首先Txn-id,用于write lock,mvcc对于ww冲突仍然是要避免的,所以tx更新时,先把tuple的Txn-id设为当前id,10,tx commit后,txn-id会置0
生成B2版本,B1的end-ts更新为10,表示B1的生命周期从1到10

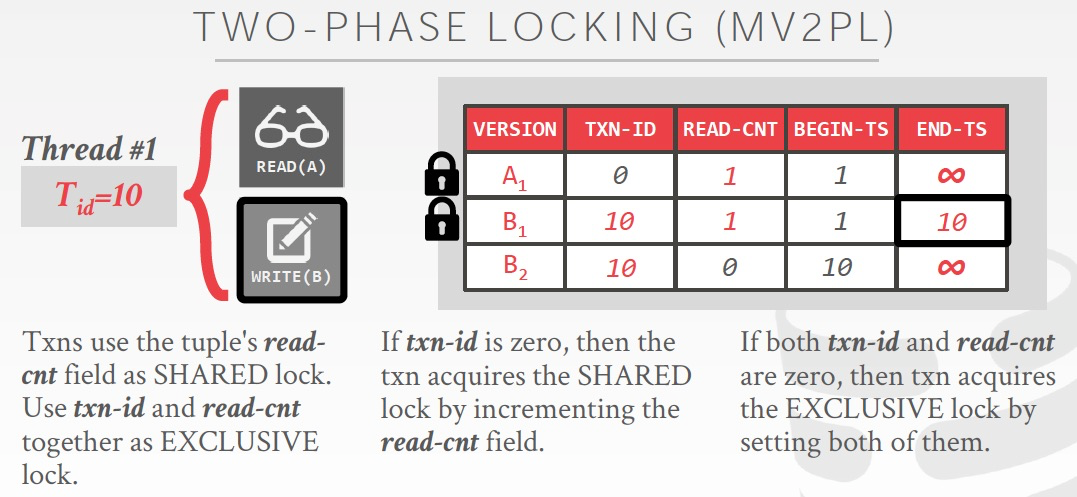
再看下,MV2PL,不同的meta是Read-cnt
read-cnt,表示多少tx在读,作为shared lock
txn-id和read-cnt,作为exclusive lock

读,首先txn-id为0,表示没有txn在写,然后read-cnt需要加1
写,首先txn-id和read-cnt都为0,表示没有读写,然后同时把两个给设置成10,加1

这有个问题,ts会到上限,需要wrapRound
解决的方法,用flag标识frozen,新的txn id总是比frozen版本更新


Occ这里没有介绍,后面会详细介绍
Version Storage
多版本,是用version chain来存储,存储的方式分为3种


既然是用chain来存储,就会有顺序,
O2N,如果查询新的很麻烦,需要遍历,一般都是查询Newest比较多
N2O,每次都需要改head

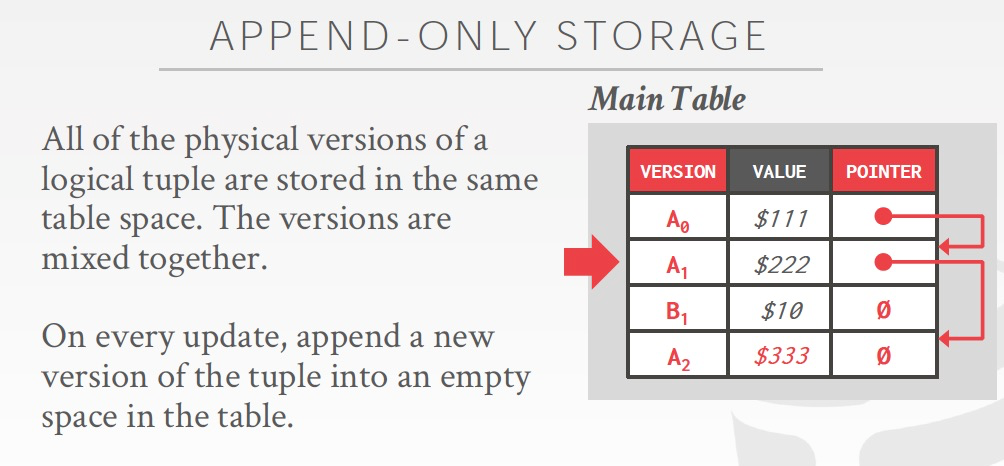
Append-only,多版本都放在Main Table里面,比较简单,版本之间通过point关联
问题是,如果version多了,主表膨胀太快,不好维护
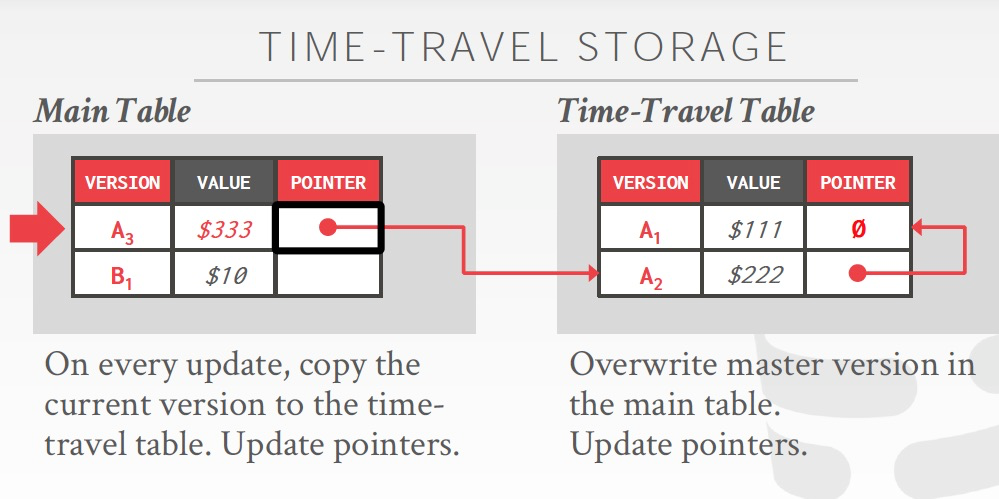
Time-Travel Storage
把old version放到一个临时表,以tuple为单位
这样主表只有最新版本
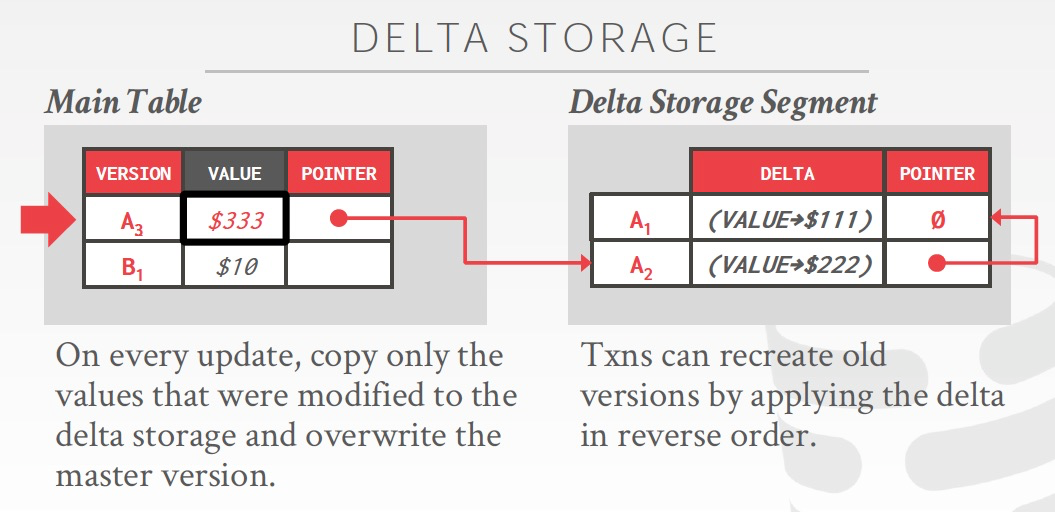
在临时表中,只会记录Delta,改了一个attribute就记录这个attribute的delta,tuple中没有改的部分不用记录
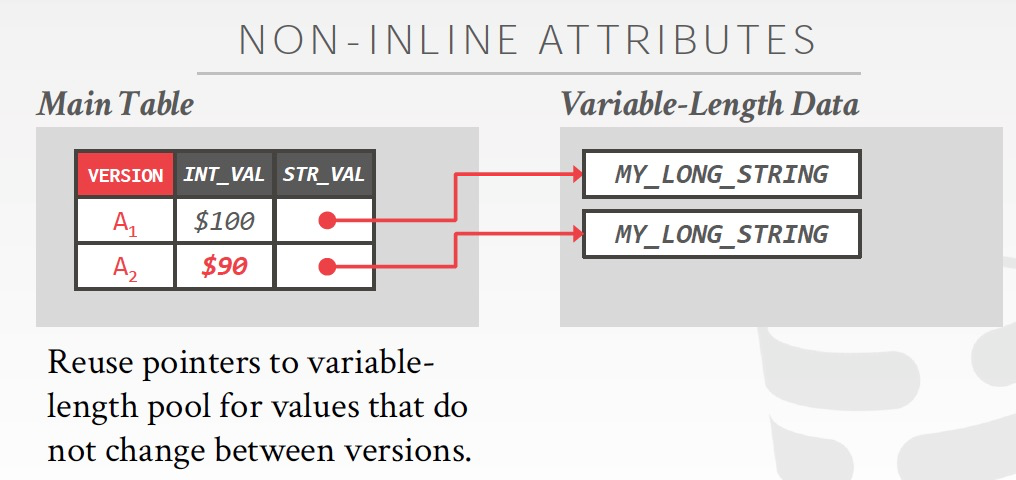
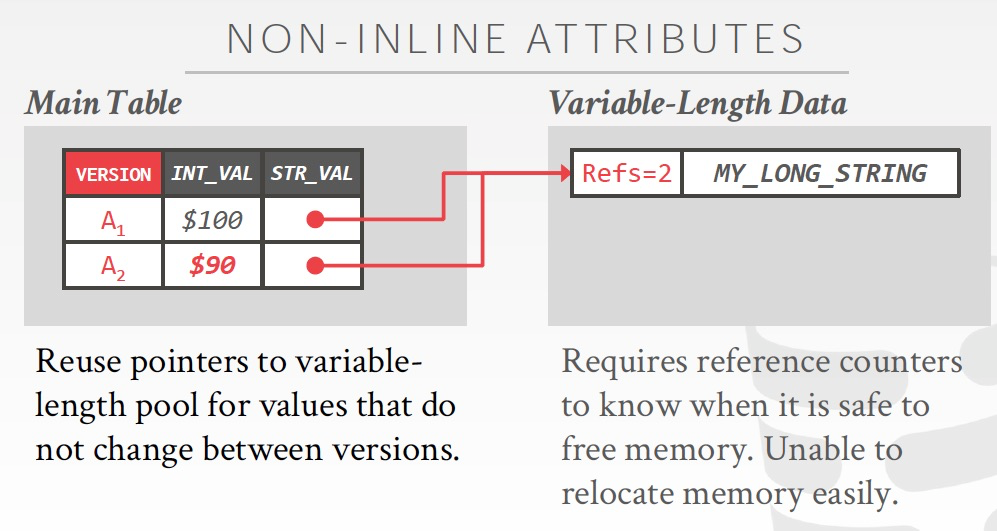
Non-inline的value,在多版本的时候如何处理,肯定不能存多份,用Ref,并且用ref counters来记录引用次数
Garbage Collection
GC分为两个粒度,Tuple或是Transaction


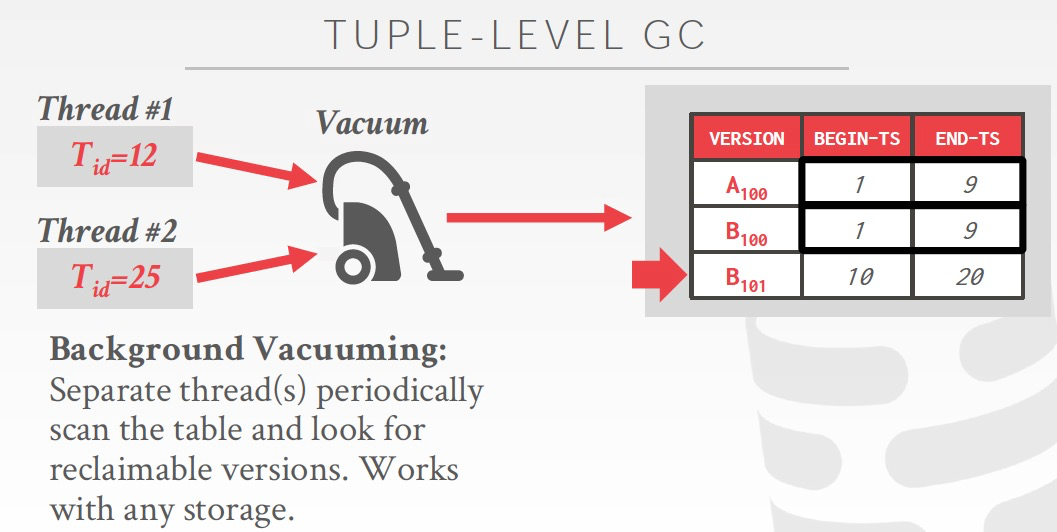
Naive的想法,就是用一个后台的线程,不断的检查每一个tuple,并且把过期的Vacuum
方法的问题是,如果数据量很大,很难完成
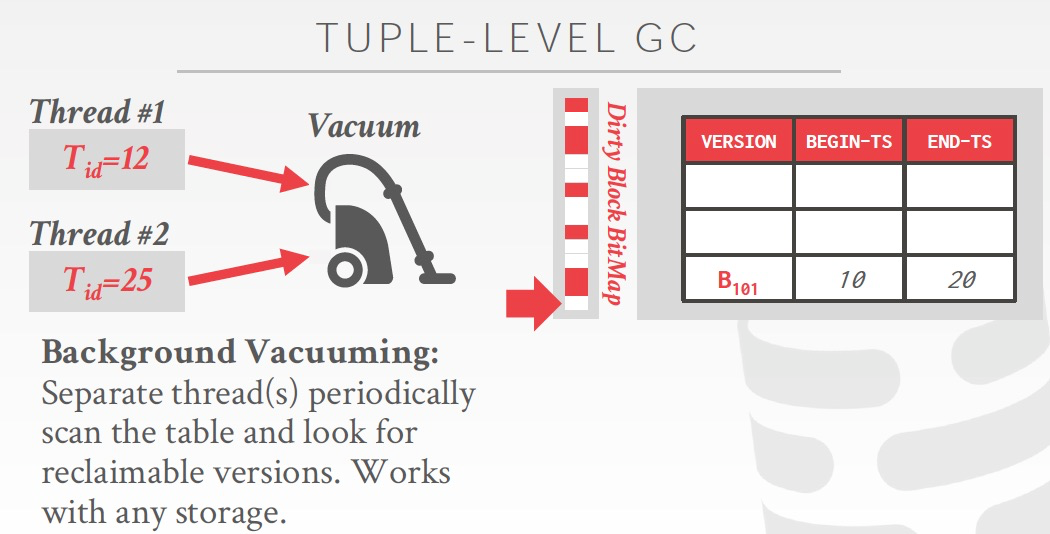
Cooperative cleaning,在查询的时候,要遍历version chain,这个时候顺便把旧的删掉
但是问题是,如果tuple一直没有被查询,就不会被过期,所以还是要辅助用Vacumming的方法

按照Transaction的维度,要求保存下r/w set,这样可以把不用的Transaction所创建的版本都过期掉

Index Management
主键,如果N2O,需要每次更新
二级索引,一般需要用logical pointers来降低update频率


给出各个现有的数据库引擎,所以使用的MVCC的设计和实现,
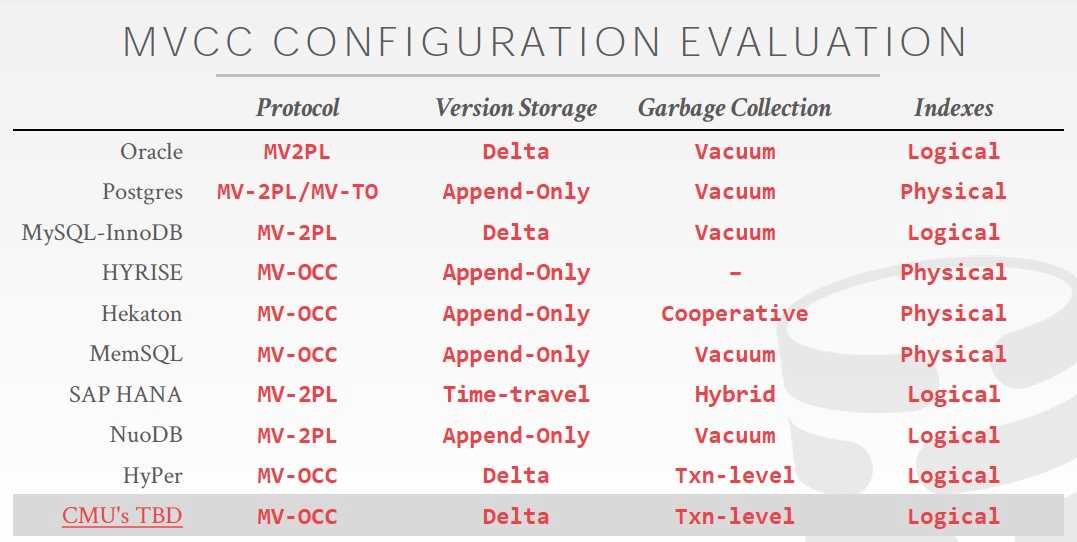
MV-OCC
下面看两个OCC的实现的例子,
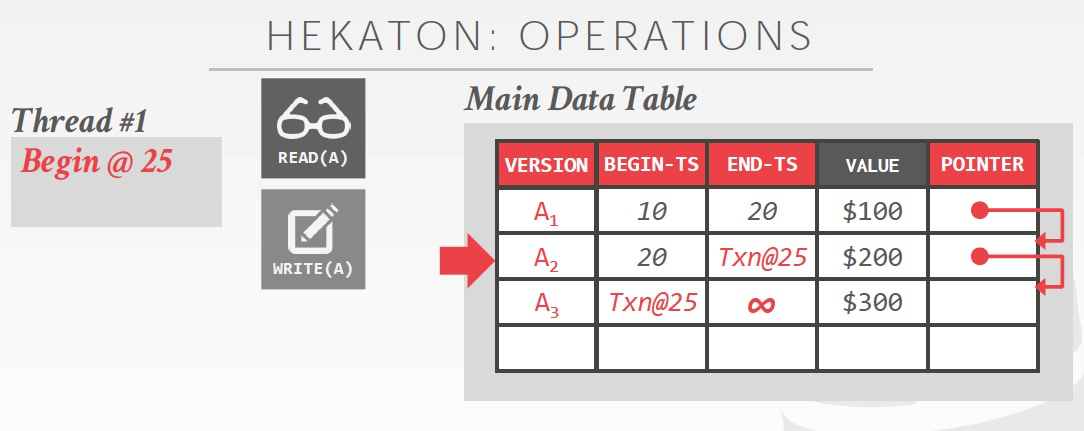
首先是mssql的Hekaton,
Hekaton是MVOCC,Append-only,所以多版本都存储在main table

OCC是乐观锁,冲突是通过validation来保证
所以读的时候,不需要做ts的更新,找到相应的ts段读取相应的版本
写的时候,增加新的版本,并更新ts,这个时候ts是个更新中的状态

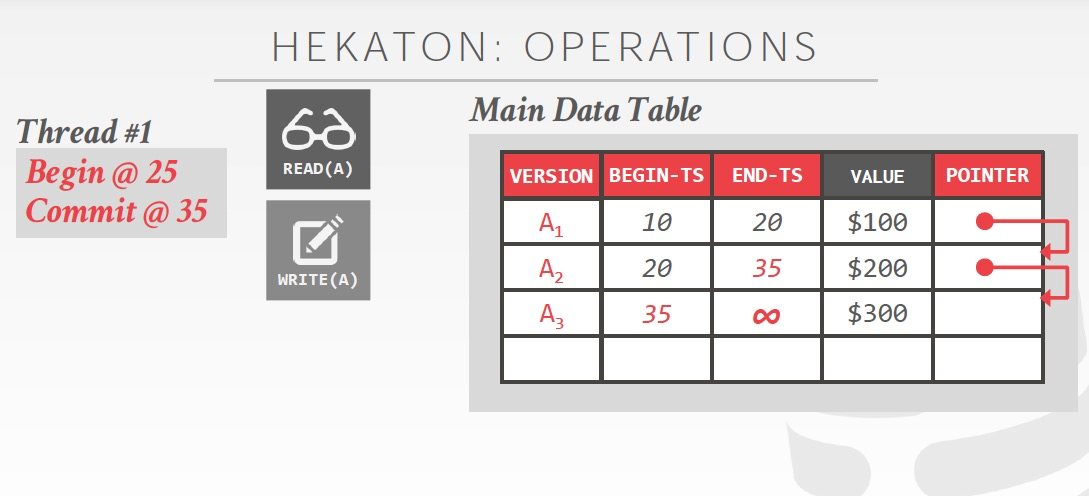
直到commit,ts才会更新成正常的commit ts
如果这个时候,发生写写冲突,如下图,看看这个txn@25,就知道已经被更新,抛出异常
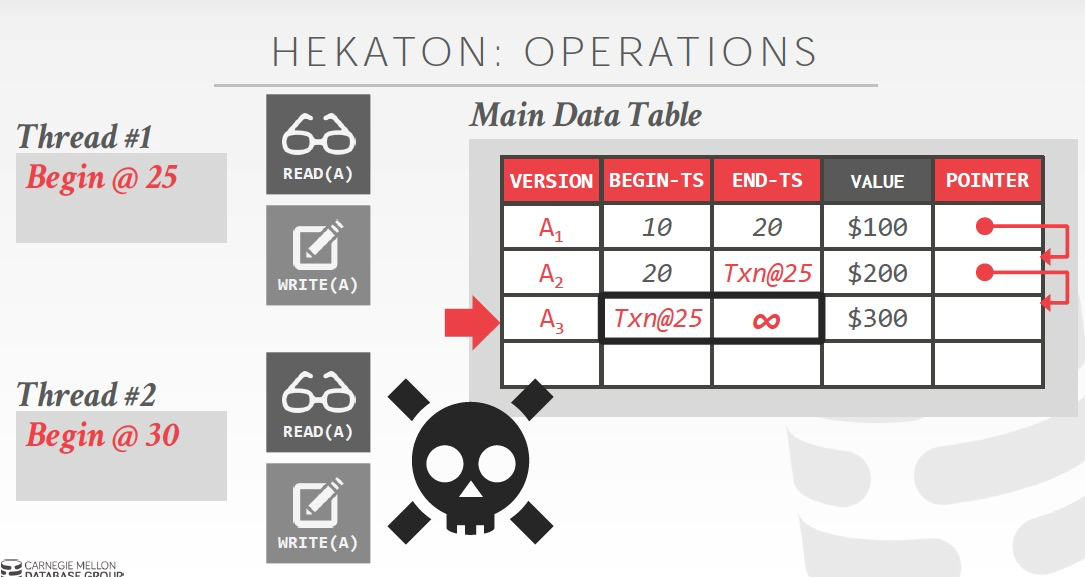
OCC比较关键的步骤是validating

如果要发现冲突,需要每个Transaction记录下Read,Write,Scan Set,还有Commit依赖


Hekaton的优点是无锁,除了获取全局自增的txn id
问题是,Read/Scan set validation可能非常的贵,如果txn访问了大量数据,所以这个适用于TP场景,如果是AP场景会有问题
AP如果要Scan数据,性能不高;Record级别的互斥比较粗,也许两个Transaction写的是相同record不同的column


Hyper是德国人做的学术性数据库
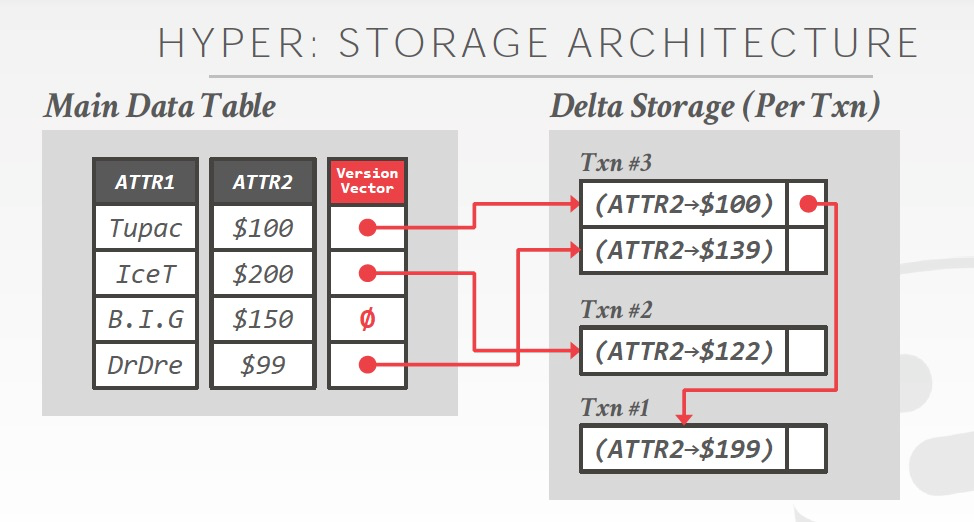
采用的是MVOCC,Delta存储的方式

存储格式如下图,
还是论文里面的图更清晰一些,
账号中,刚开始每个人都是10,现在通过3个Transaction,从Sally转1到henry,wendy,mike
Hyper在主表中存的是最新的数据,最新数据可以in-place更新,这样避免index的更新
通过一个单独的列,VersionVector来指向delta,delta记录的其实就是undo buffer的chain
例子中,T3,T5已经commit,T6还在进行中
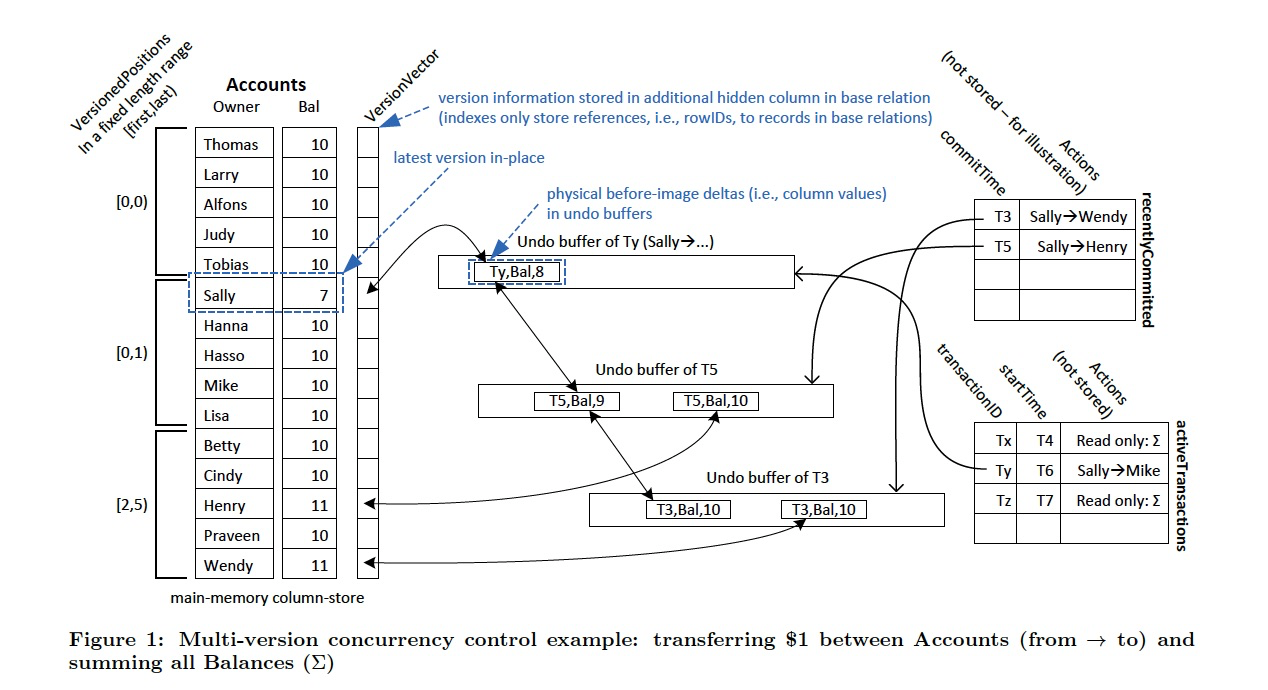
对于Hyper,最关键的创新在validation阶段,提出precision locking,来满足serializability

首先,只取validate,那些在当前txn开始后,committed的txns
因为如果之前就committed,你读到的一定是最新的值,如果之后commit,那就是他commit的时候需要validate,跟我无关
根据txn中每个sql的predicate的范围,看看哪些committed的txns所更新的值,是否在范围中
底下两张图是都不在范围中


这张图,发生了冲突,所以需要回滚
txn读到的数据,被txn#1003修改了,不可重复读

version vector有个问题是,Transaction完成后,delta会被回收掉,所以大部分version vector都是空的,所以要找出哪些非空会比较低效
所以synopses会标记出,什么范围内有非空的vector,这个例子中是在2,5之间会有

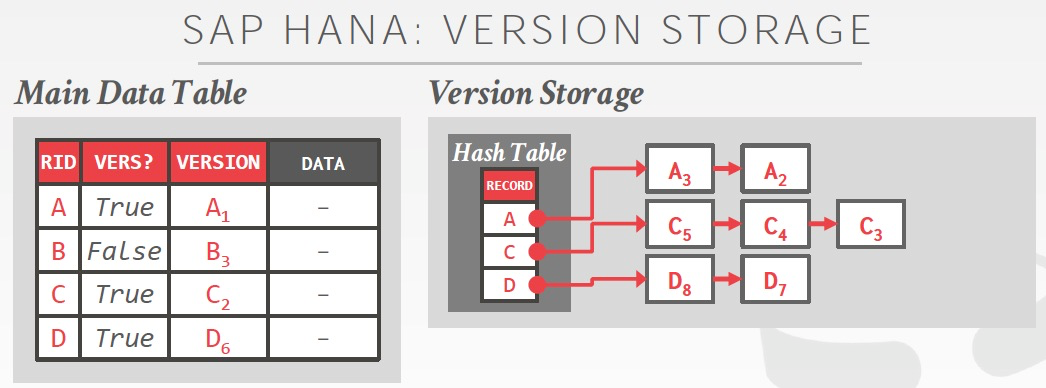
介绍一下Hana的MVcc设计,MV2PL,time-travel存储


比较奇葩,Hana是N2O,但是main table里面放的是oldest版本
用一个flag来标识是否有新版本,读新版本至少要多一跳,通过独立的hashtable
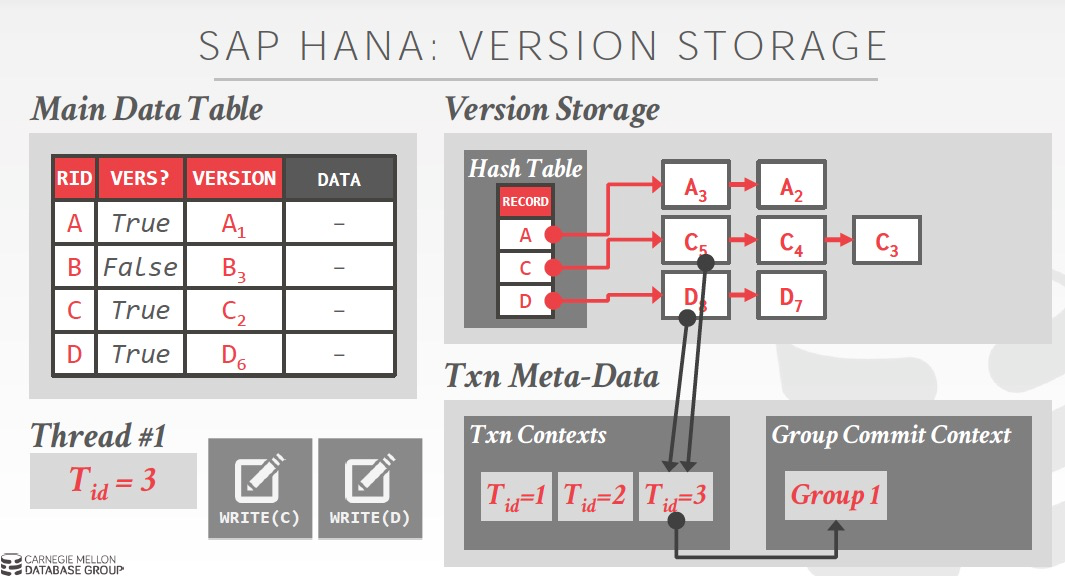
版本所对应的txn的meta也是通过pointer指向一个独立的Txn meta data的空间

MVCC问题,
版本一般是用chain保存,需要去search chain来找到版本
需要额外的GC模块来过期老的版本
id或ts的分配有全局瓶颈


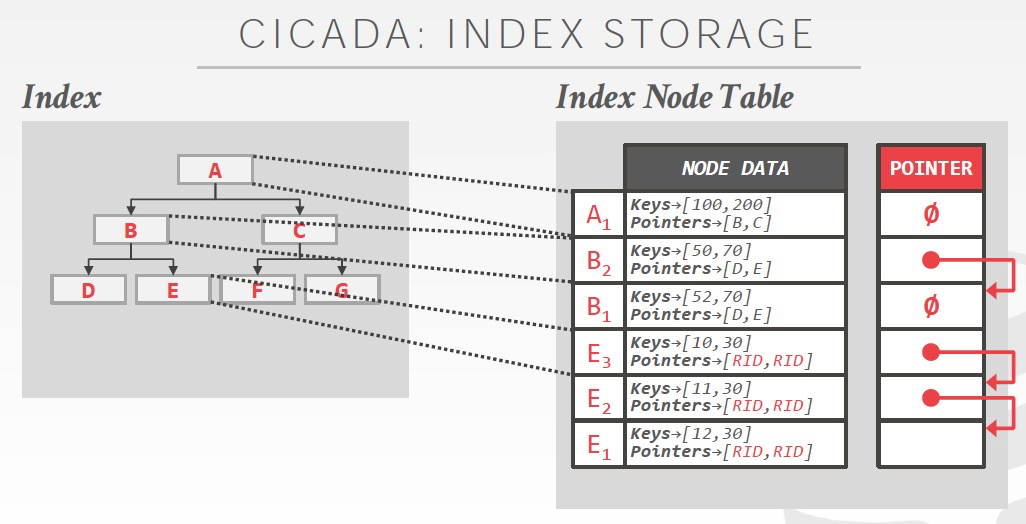
这里还介绍了一种CMU的CICADA,