Unnesting Arbitrary Queries - T Neumann, A Kemper
The Complete Story of Joins (in HyPer) - Thomas Neumann, Viktor Leis, Alfons Kemper
Unnesting Arbitrary Queries
如其名,这篇paper讲的就是如何unnesting
看个简单的例子,这里称相关子查询为,dependent join

经过unnesting后得到下面的SQL
可以看到,unnesting的过程就是,把where中的标量子查询,放到from中成为一个derived table
所有的unnesting的思路,基本都是如此,把依赖外部的参数提出,剩下独立的sql生成临时derived table,然后再和外部的表进行join

定义
先给出inner join 的定义,
inner join就是对笛卡尔积,cross product,的一个selection

接着定义,dependent join,
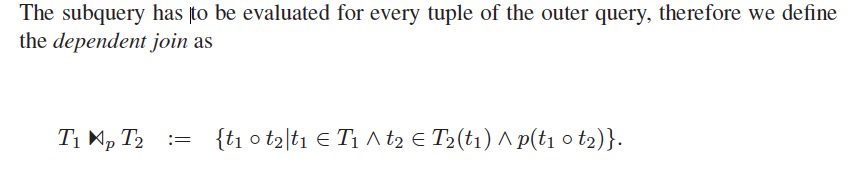
从公式中看出,T2是个function,t2是T2(t1)的输出结果,同时结果还需要满足selection p
这里叫join有些confuse,微软定义为apply算子跟容易理解些
Unnesting
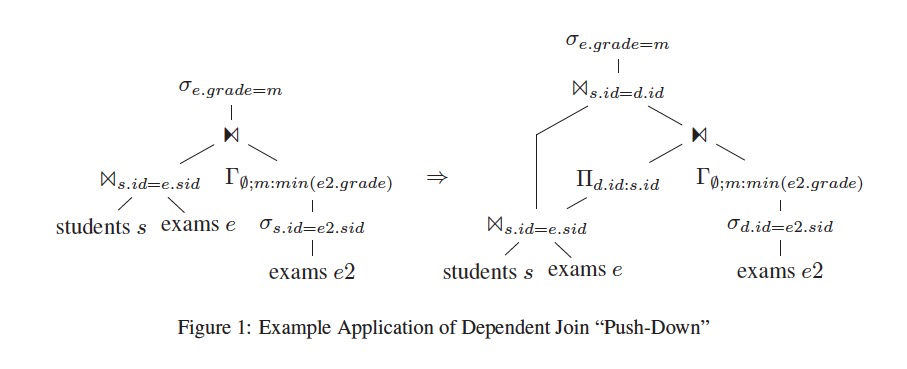
这里以TPCH-21为例子,
这里把selection上提,消除了l2的参数,转化为regular join

为什么把selection上提是合理的?
有selection的时候,对满足的条件的row执行sql,所以把selection上提后,就是对全量row执行sql
得到的结果是原来的超集
然后在外层再通过selection过滤,效果上是等价的
General Unnesting
上面只是一个例子,那么对于general的场景下,如何进行unnesting?
首先做一步转换,
D是个T1的子集,仅仅包含T2所需要的参数列的distinct
这样做的好处是,D是一个远小于T1的表,尤其如果T1的参数列有大量的重复的话
T2原先需要对T1的每一行都apply,但是现在只需要对distinct后的行

所以这里就把一个dependent join,转化成一个nicer的dependent join和一个regular join
以这个sql为例,
可以看出这个转换是等价的
再者,需要消除Dependent Join
消除的条件如下,
当D的输出列和T的参数列不相交的时候,就可以转化为regular join

如果不满足的,就需要用下面的公式去转换,
Selection
前面已经解释了,为什么selection上提是合理的

Join
对于inner join,本身是有交换和结合率的,所以可以简单的把和D没有依赖的join先提出
如果两边都依赖D的话,需要将D复制一份,分别和两个进行Dependent Join
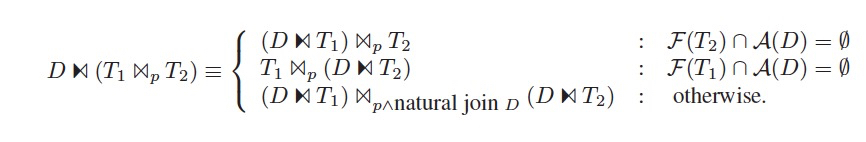
同样对于Outer Join和Semi Join这种不支持交换率的情况,也需要复制D
GroupBY
GroupBy在上提后,会需要加上join key

Projection
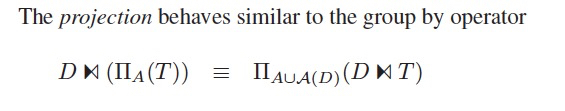
根据这些规则,消除的过程如下,
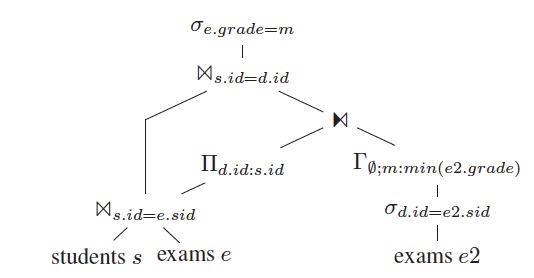
上提GroupBy,按照规则,上提后, group by的column加上d.id

上提selection
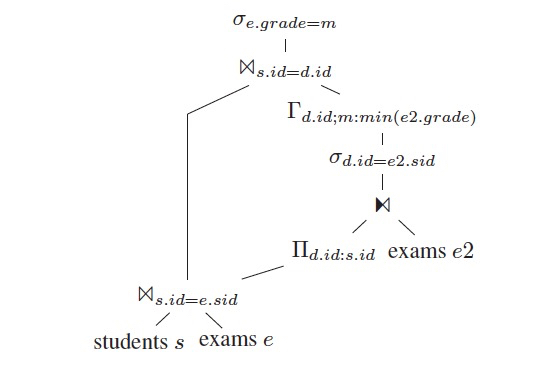
此时,dependent join的左右已经不相干,
所以将dependent join转换为regular join
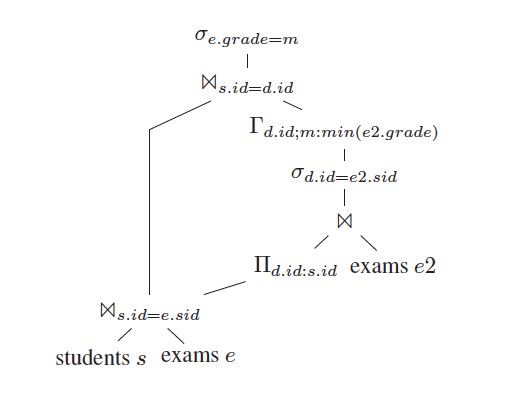
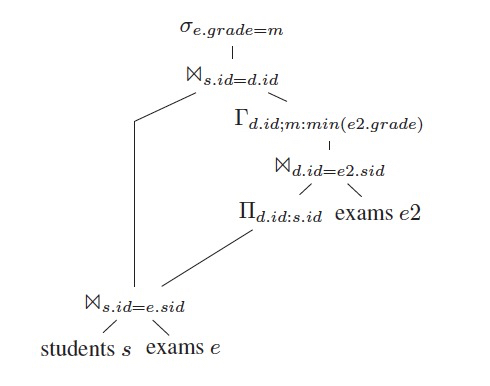
把selection下推到join上
The Complete Story of Joins (in HyPer)
主要介绍两种特殊的Join算子,
Single Join
对于下面的Sql,

子查询如果返回不止一条结果,需要报错
这就是需要加上Max1Row
而SingleJoin把Max1Row集成到算子内部,

Mark Join
看下这条Sql,

子查询后面有个or,Disjunction predicates
这样如果直接转成semi-join会有问题,因为那些可能满足or Sabbatical = true的行在join的时候会被筛选掉,上面拿不到
所以一个自然的想法就是,我们在join的时候不去筛选数据,把数据都保留下来,只是给每行打标,true,false,null

可以看到Mark Join的定义,多出一个m,用于标记是否满足join条件
因为Mark join没有筛选行,所以在最外层,我们可以自由的通过projection来挑选数据,
这里会选m为true,或者Sabbatical=true的行
MarkJoin在对null值的处理上也会很方便