Overview
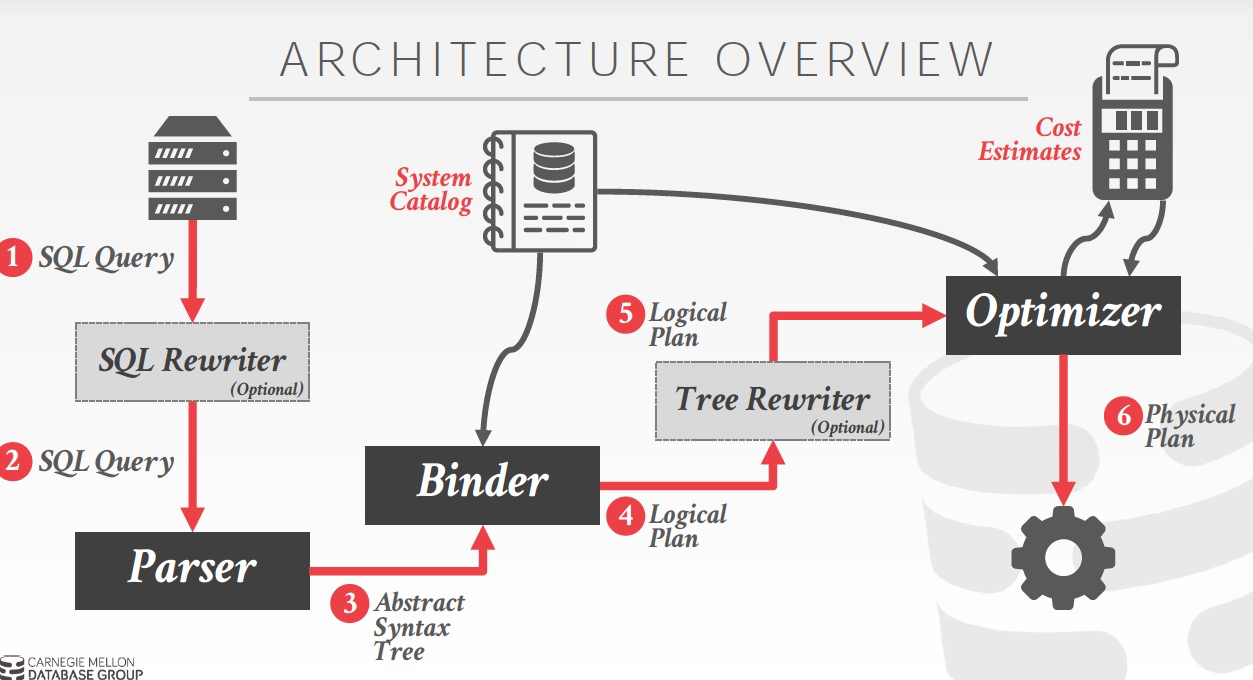
Optimizer模块所处在的位置如图,
那么做optimize的目的是,
找出所有‘correct’执行计划中‘cost’最低的

那么这里首先要明确的概念,‘correct’,关系代数等价,产生相同的结果集;所以所有优化的前提是需要是等价变换
但是等价集合,即所有等价的执行计划的集合,会非常大,所以这个问题是如果要穷举会是NP-Complete问题;所以需要研究‘Search算法’来限制search空间,提高search效率

在等价集合中,如何选择执行计划,通过‘cost’,如何定义和计算cost也是非常困难的工作,因为涉及查询cost的因素有很多

逻辑计划和物理计划
区别简单的说,逻辑计划是说‘做什么’,物理计划是说‘怎么做’

通常Optimization对OLAP意义更大,因为OLTP的查询一般都比较简单,并且通常都是sargable的

Design Decision
在设计Optimizer的时候需要考虑哪些点?
优化粒度
基于单条query或是多条query进行优化,明显基于多条query会效果更好,但是那样的search space会大很多,所以当前主要还是在研究单条query的优化

静态优化 v.s. 动态优化
动态优化比较理想化,但是难于实现和debug,所以现在主流都是静态优化;Hybrid方式,会在error超过阈值时,选择re-Optimize

Prepared Statements的优化
这种情况下是参数化的,所以当传入参数不同的时候,会影响筛选率,进而影响join的顺序
解决方法有3种,1. 每次都re-optimize;2. 生成多个plans,并把参数buckets化,参数落在什么buckets中就选相应的plan;3.用参数的平均值来生成plan


Plan的稳定性
用户有时候更关心的是,相同query执行的稳定性
所以就算你的优化器99%的情况下比原来的好很多,但是会有1%的bad cases,用户的反馈可能反而是负面的
所以需要如下的方法去保障plan的稳定

Search算法的结束标准
这个search问题是个NP-Complete问题,一般没法完全穷举
算法结束可以用,时间,只能优化1s,到1s就结束;cost阈值,发现低于阈值的plan就结束;完成穷举,没法继续transform,结束

Optimization Search Strategy
这里重点描述优化的search算法的演进
Heuristic-based
基于启发式规则,把先验的经验定义成优化规则,简单容易实现,适用于早期的数据库


例子,一个3表join的查询,可以先拆分成3条单独的查询;由于结果集很小,第二步可以直接把每个查询替换成结果集


Heuristic+Cost-Based
在heuristic的基础上,加上cost-based来做join顺序的优化,是cost-based优化技术的初次尝试


System R的例子,


PG的例子,

Top-down v.s. Bottom-up
这里提出两种search的策略,没有说哪种一定好,当前流行的框架都用top-down,比如calcite,比较方便剪枝

Randomized
这是一个典型的优化算法的思路,比如经典算法模拟退火;
算法的缺点很明显,就是不确定性,所以往往会被用于极为复杂的查询优化,死马当活马医,反正也没有其他高效的优化方式;优点是overhead很低,很容易实现,运气好的话会有不错的效果



PG里面就实现了Genetic Optimizer

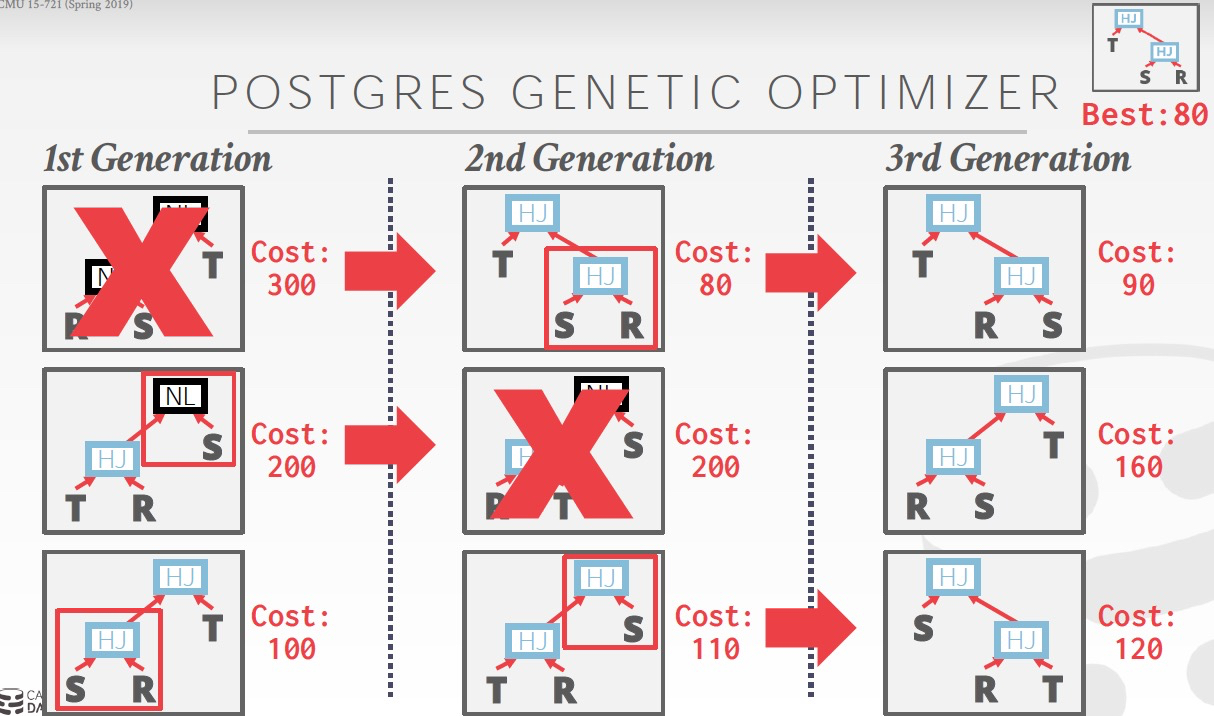
之前的Optimizer都是用程序语言写的,很难扩展或作为独立的组件
并且用程序语言写的Rule很难被理解和维护
所以大家想是否可以用DSL来维护rule,这样我们通过开发一个generator来根据DSL来生成Optimizer,这样形成framework

Stratified
优化分成多个Stage,
比如,stage1,Rule-base的logical plan的transformation;stage2,cost-based的从logical到physical plan的生成



Unified
和stratified相比,不区分stage,logical或physical的转换同时进行;同时使用动态规划和memoization来优化算法效率

比较有代表性的就是,Volcano,火山模型

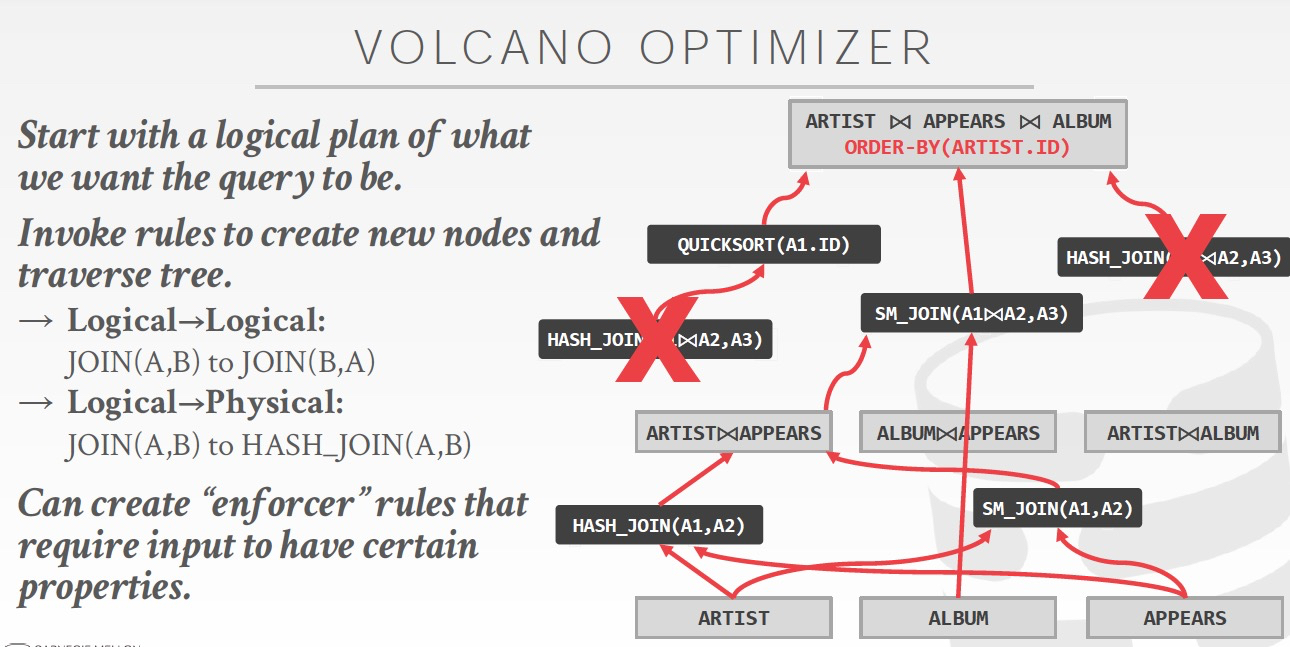

Cascades Optimizer
Valcano作为一种学术原型,而Cascades作为它的一种面向对象的实现


Cascades中的一些定义
Expression
Expression作为plan中的基本单元,有逻辑和物理两种

Groups
等价的逻辑和物理expression的集合

Multi-expression
把所有等价的expression都写出来,太多太乱
Multi-expression是一种分层的,简单的表示方式

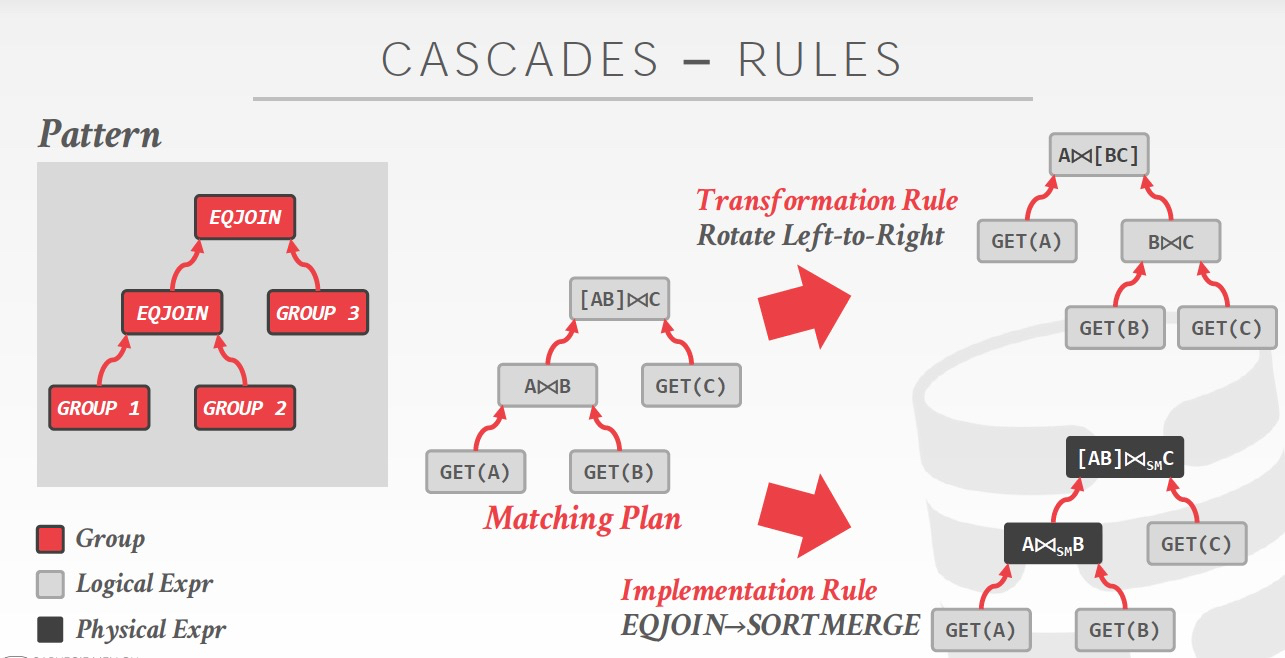
Rules
分为Transformation Rule和Implementation Rule分别对应为转换成Logical或Physical的expression
Rule有两部分组成,Pattern,定义何种logical expression适用于该rule;Substitute,定义如何转换

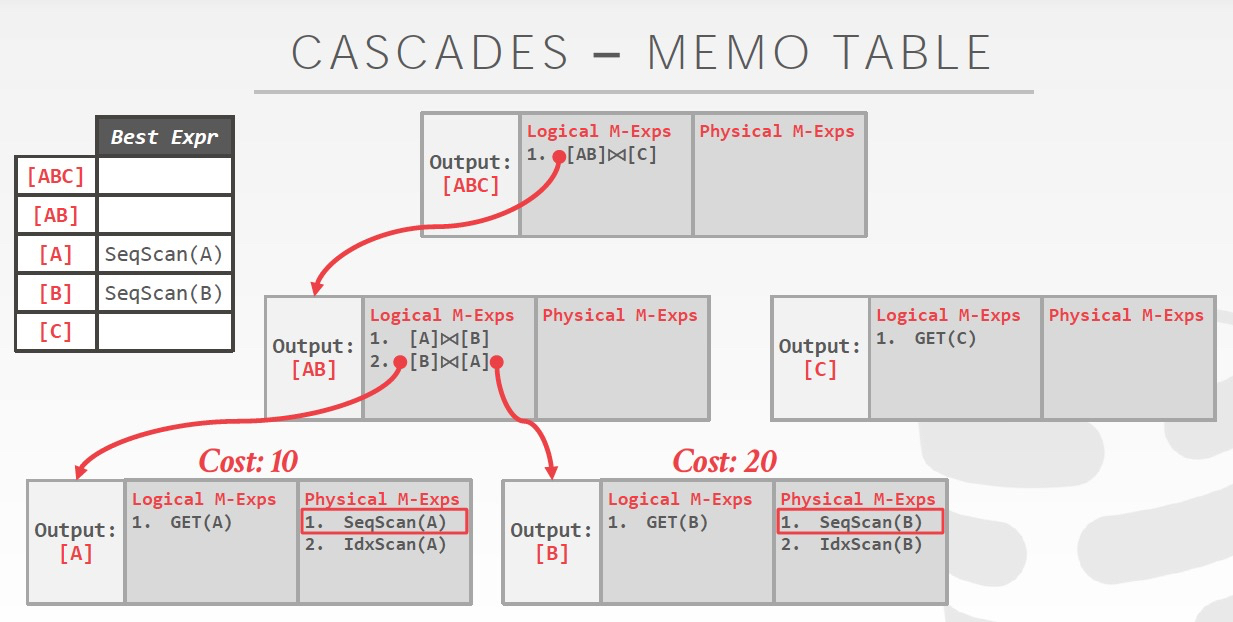
Memo Table
动态规划算法,用来缓存中间结果
可以使用Memo的前提假设,如右,如果当前plan是optimal,那么他的所有子plan也是optimal
这个其实不一定的,因为这个贪心算法的思路,有可能子plan非最优,但整体最优;
这里后面会通过enforcer来约束,保证假设成立


Memo使用的例子,
左图,算过[A] join [B],[A]和[B]的cost会被缓存,后面就可以直接用

Cascades模型当前的实现,

前面考虑的都是比较简单的join情况,如果考虑各种join,可能re-ordering是invalid的;具体解决方法这里不详细描述



优化的时候,谓词是个很关键的优化点
最常见的谓词下推,也可以在不同的阶段进行,方法二比较简单但是无法应对复杂谓词,所以一般方法一比较通用一些
对于谓词还需要考虑,哪个谓词先被执行,这个需要考虑两个方面,selectivity和computation cost



下面列举一些例子,
Orca,


Calcite

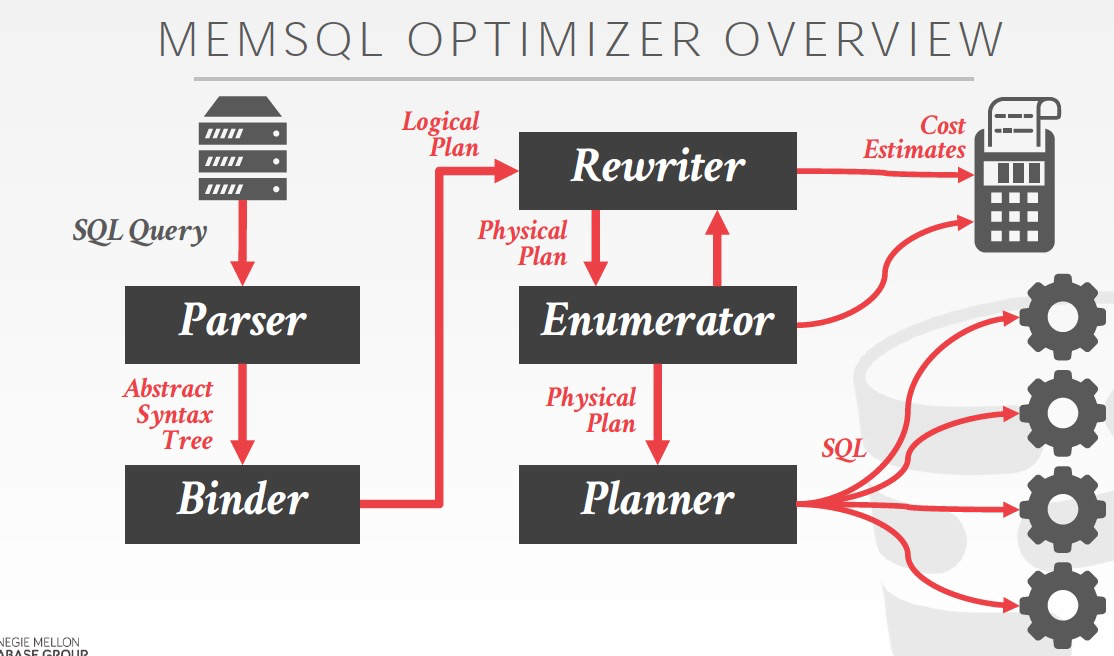
Memsql
特点是,在把优化过的physical plan重新转化成SQL,然后再发到各个子节点
因为对于分布式数据库,子节点上有更准确的数据分布信息,所以在子节点上再根据local的信息做一遍优化会更合理

Cost Model
cost模型用于评估query的某个plan的执行代价,这个本身是和search strategies是独立的
但是search过程中的评判标准需要cost模型给出,所以如果cost算的不准,那么search算法再好也是没有用的

Cost模型,需要包含很多方面,物理的cost,逻辑的cost,算法的cost等
但是其中某些因素是起到关键作用的,比如对于disk-based DB关键的是磁盘IO的次数,或顺序读和随机读;如果对于内存数据库,关键的就变成网络IO


看下主要的数据库的cost model
PG是结合CPU和IO的cost,并根据设定的权重来计算cost
DB2作为商业数据库,会考虑的比较全面,甚至包含当时的执行环境
内存数据库,往往需要考虑cpu和内存,但是内存cost很难衡量,所以一般也是用处理的tuple数来预估cost



这里要介绍的一个概念是筛选率,
谓词,理解成where条件,会筛选掉部分的数据,降低查询成本,所以一般应该优先执行筛选率高的谓词
但是这个筛选率是未知的,同一个where条件,对于不同的数据集筛选率也是不同的
所以对于筛选率的预估,成为cost计算的核心,对于复杂的查询还是很困难的
筛选率的预估一般的方法有,
领域约束,比如字段是性别,条件是男的筛选率取决于人群的男女比例
预先统计,对每个字段有个预先的统计,这个成本会比较高
Histograms或近似算法
采样


近似方法和采样,是在可接受的成本范围内,比较好的预估方式


如果我们已经知道筛选率
那么input * 筛选率 = result cardinality
result又是下一个operator的输入,这样就可以算出整个pipeline上每个operator的处理的tuples数,即代价

我们在计算cardinality的时候,基于下面的假设,
均匀分布,比如性别字段,我们假设,男女各50%,这个和实际一定是不符合的
谓词独立,比如中间图的例子,品牌和型号两个谓词是相关的,accord只有honda有,所以筛选率计算要考虑;对于这个问题,后面给出一个方案,column group统计
第三个假设,不太理解



这里给出一个例子,如果计算一个query的result cardinality

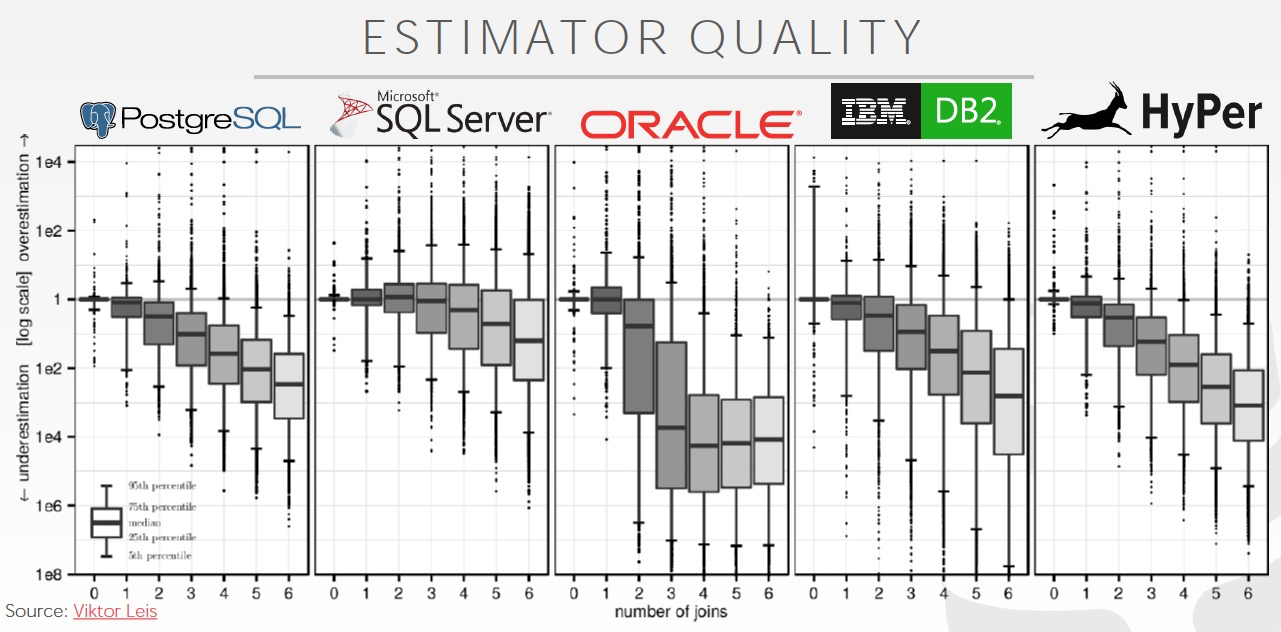
这篇paper讨论如何评价cardinality预估的准确性,
总体得到的经验,
总体当前优化器对于cardinality的预估都是低估的,并且join的表越多,相应低估的误差也越大