http://blog.csdn.net/ruby97/article/details/7423088
经过一整天的折腾,参考了网上很多资料,我机器上的Hadoop似乎是配置成功了。下面分享一下详细的配置过程。也祝愿大家在配置的过程中少走弯路。
注意:本文的配置环境是:
- CygWin最新版本2.769下载地址
- Window7-64bit
- JDK1.6.0_31-win64 (JRE6)下载地址
- Eclipse-Indigo..
- Hadoop 0.20.2 (注意:0.20.203版本不可用,会导致tasktracker无法启动)下载地址
-----------------------------------------华丽分割------------------------------------
环境安装&配置:
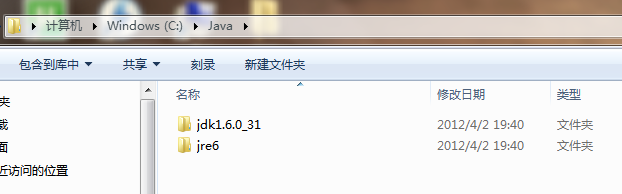
1.JDK,我的安装目录:C/Java,安装后视图
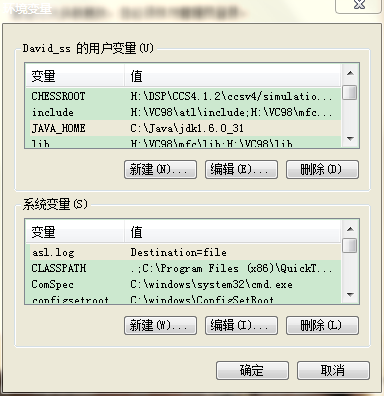
安装好了JDK,然后配置JAVA_HOME环境变量:
然后,把JDK下面的BIN目录追加到环境变量PATH后面。
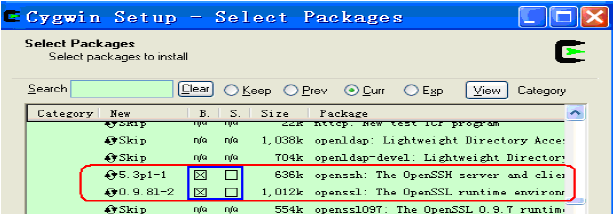
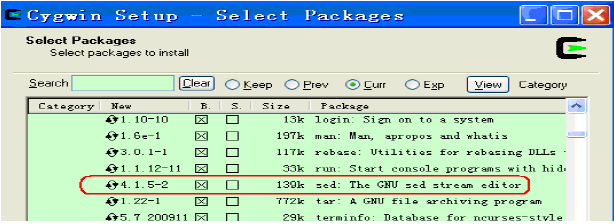
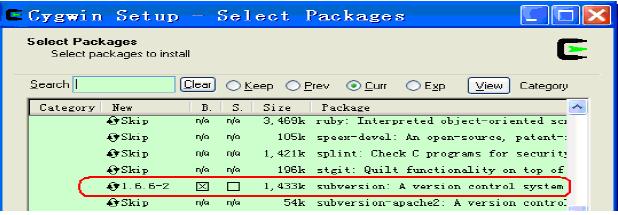
2.CygWin,安装过程中记得选择所需的包,这里需要的是:
Net Category下的:openssh,openssl
BaseCategory下的:sed (若需要Eclipse,必须sed)
Devel Category下的:subversion(建议安装)。具体请参考下面的图示:
安装完成后,把CygWin的bin目录以及usr/sbin 追加到系统环境变量PATH中。
3.Hadoop
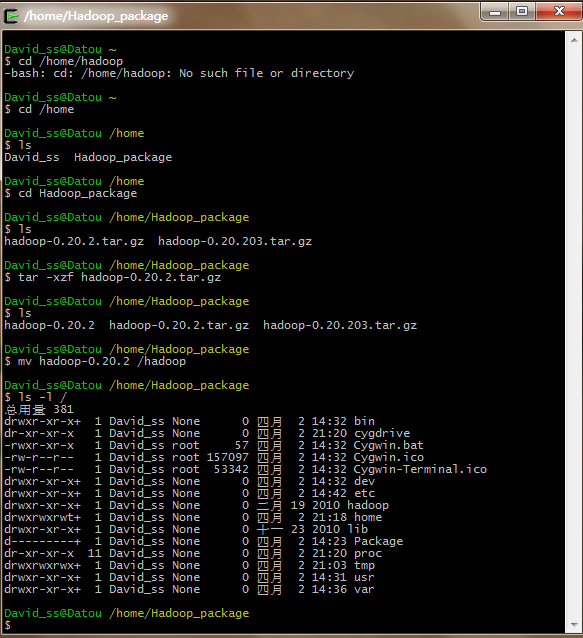
把下载的hadoop-0.20.2.tar.gz解压到指定目录。我把解压后的Hadoop程序放到了Cygwin根目录下的hadoop文件夹中。具体如下图示:
(不要使用0.20.203版本的Hadoop!!!)
下面开始配置Hadoop。需要配置的文件:(hadoop/conf目录下)
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
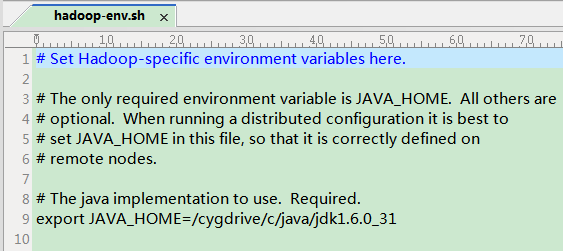
第一个文件 hadoop-env.sh
把里面的JAVA_HOME改掉,注意export前面的#号要去掉。
而且必须要使用linux的路径表达方式。我的jdk路径是 C:JAVAjdk1.6.0_31,在CygWin中对应的路径为: /cygdrive/c/java/jdk1.6.0_31
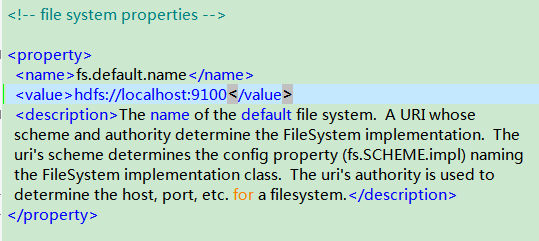
第二个文件:core-site.xml
首先删除它,然后把hadoop/src/core目录下的core-default.xml文件复制到conf目录下,并命名为core-site.xml。然后修改其中的fs.default.name变量,如下所示。
(确保端口号(我的是9100)未被占用)
第三个文件:hdfs-site.xml
首先把它删除,然后复制src/hdfs目录下的hdfs-default.xml到conf目录下,并改名为hdfs-site.xml
然后修改dfs.replication变量,如下图示:
该变量意思是文件系统中文件的复本数量。在单独的一个数据节点上运行时,HDFS无法将块复制到三个数据节点上。
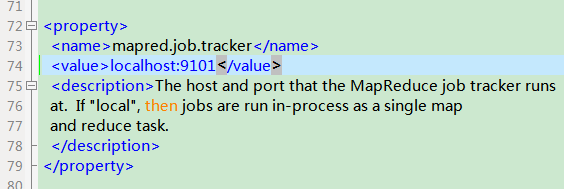
第四个文件:mapred-site.xml
首先删除它,然后复制src/mapred目录下的mapred-default.xml到conf目录下,并改名为mapred-site.xml,然后修改其mapred.job.tracker变量:
(同样确保端口号未被占用)
----------------------------------华丽分割-------------------------------------
配置SSH服务(首先确认安装了OpenSSH,OpenSSL两个包)
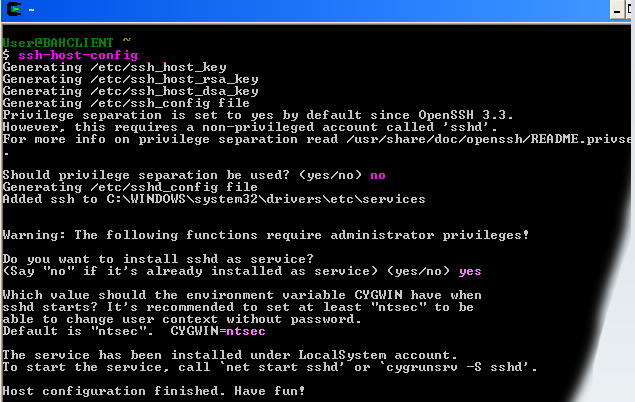
1.打开CygWin输入SSH-HOST-CONFIG
2.系统提示:should privilege separation be used ? 回答:no
3.系统提示:if sshd should be installed as service?回答:yes
4.系统提示:the value of CYGWIN environment variable 输入: ntsec
5.成功
下面是图示(我自己当时没记录,所以参考的是网络上的图片)
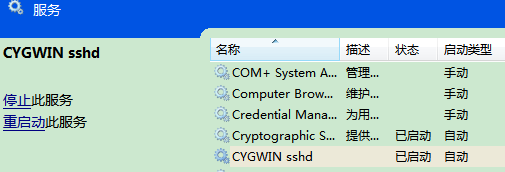
下一步,进入Window系统的服务菜单,打开Cygwin的SSHD服务:如下图所示:
下面继续回到CygWin环境:执行如下命令:
1.ssh-keygen然后一直回车
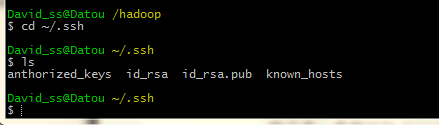
2.cd ~/.ssh
3. cp id_rsa_pub anthorized_keys
4.exit 退出cygwin,若不退出,可能出错
再次登录时查看一下:
5运行 ssh localhost 若有提示,则回车。
6执行 ps 若看到 有/usr/bin/ssh 进程,说明成功
------------------------------------华丽分割----------------------------------
启动Hadoop
第0步:为了避免jobtracker,info could only be replicated to 0 node,instead of 1错误,最好把 hadoop/conf目录下面的 masters和slaves文件全部改为127.0.0.1(原内容为:localhost)
第一步,在hadoop目录下创建目录logs,用于保存日志
第二步,格式化管理者,即namenode,创建HDFS
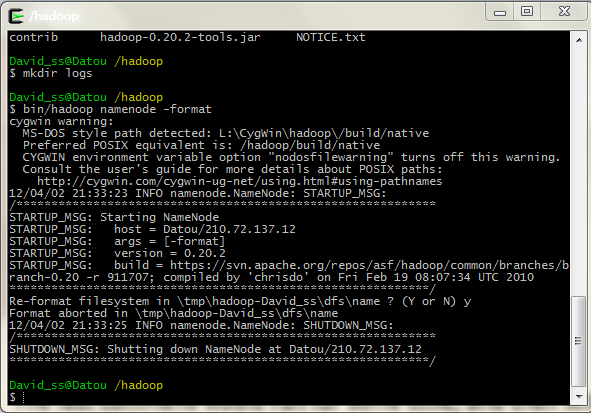
执行命令: bin/hadoop namenode -format,下面示代表成功
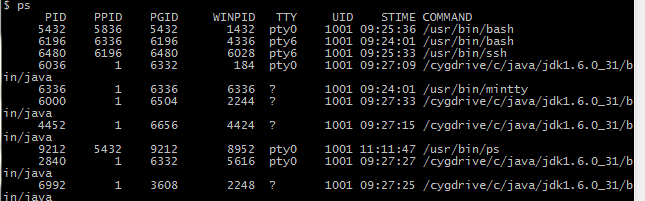
此时,执行ps,应该能看到ssh进程,且看不到java虚拟机进程。
第三步,启动Hadoop,执行命令: bin/start-all.sh
然后执行jps命令,你可能会看到如下图:
会发现Datanode ,Secondarynamenode以及TaskTracker都没有启动。网上有人说是JPS的问题,具体不是很清楚,但本文后面的文件系统可以使用。Datanode可以保存数据,继续看吧。
不过此时执行PS命令,能看到5个JVM进程。
不知道这算不算成功,但我的Logs日志文件夹里面没有报错。
------------------------------华丽分割---------------------------------------
文件系统操作
为了验证HDFS能够正常工作我们可以进行文件的上传操作。
执行命令:
bin/hadoop fs -mkdir In
bin/hadoop fs -put *.txt In
以上命令会在HDFS中建立In文件夹,然后把本地Hadoop目录下的所有文本文件上传到HDFS中,Hadoop目录下共用四个txt文件:
OK,上传的太少,不爽,再上传一部电影。比如,我要把一个视频文件movie.mpg上传到HDFS中,首先,在Hadoop根目录下建立文件夹local,然后把movie.mpg拷贝到其中
下面执行命令:
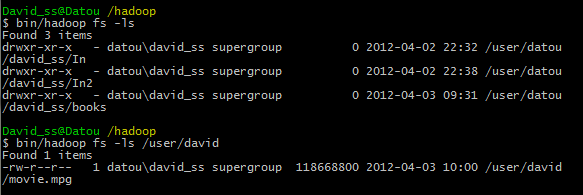
然后,查看文件系统是否有上述文件:
可以看到Movie.mpg在HDFS中。
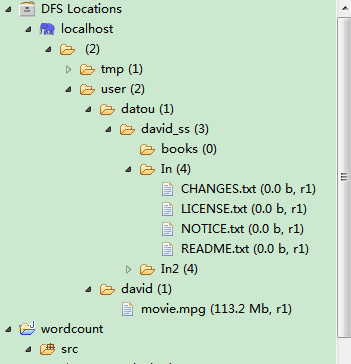
同样在Eclipse中也能看到哇:
OK,突然不能贴图了,我再接着写一篇吧。介绍一下常见的错误处理。
本文接上一篇:http://blog.csdn.net/ruby97/article/details/7423088
上一篇最后贴的图是在Eclipse下查看文件系统组成。
配置Eclipse插件请参考http://www.cnblogs.com/flyoung2008/archive/2011/12/09/2281400.html
------------------------------------------------------------------------------------------
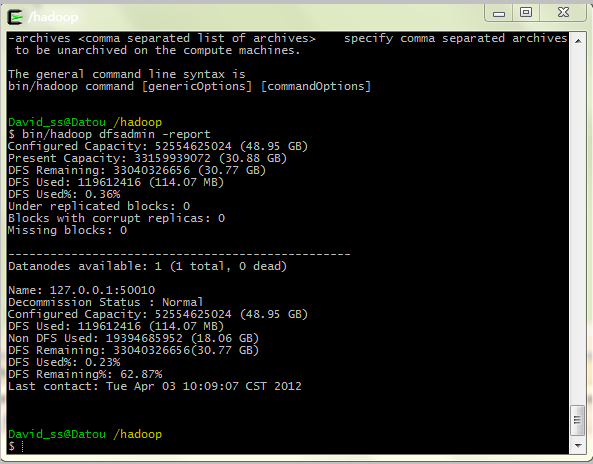
继续上一篇。上传完视频以后,可以通过如下几个命令查看系统的运行情况:
bin/hadoop dfsadmin -report
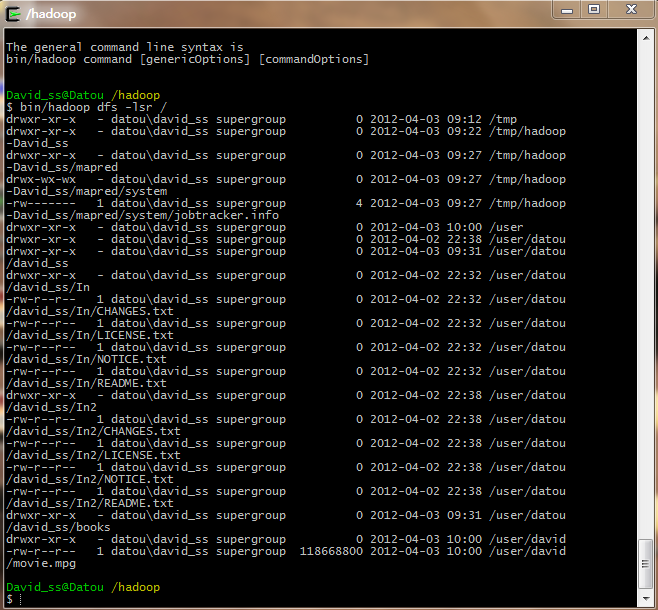
bin/hadoop dfs -lsr / 查看文件系统
OK。我在配置过程中主要遇到的错误是:
错误1. ...could only be replicated to 0 nodes,instead of 1
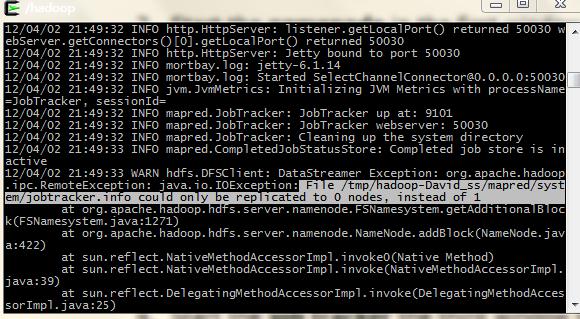
这个错误主要的解决方法是:
1.把 tmp文件全部删除。
2.然后把hadoop/conf目录下的slaves,masters文件内容全部改成 127.0.0.1
3.重新格式化namenode :(bin/hadoop namenode -format)
也许你不知道hadoop 的tmp文件在哪里,默认情况下应该才 cygwin根目录下的tmp文件夹内:
如下图所示:
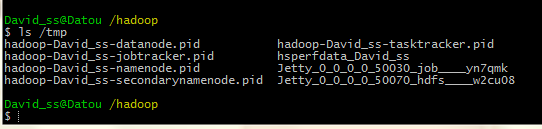
把它们都删掉。就OK了。 (cd /tmp , rm -rf *)
参考博客:http://albb0608.iteye.com/blog/1279495
错误2:
name node is in safe mode
直接输入命令: bin/hadoop dfsadmin -safemode leave 离开安全模式
----------------------------------华丽分割------------------------------
记录配置过程到此结束,如有错误,烦请指出,不胜感激。