一、简介
Lucence.Net提供一组API,让我们能快速开发自己的搜索引擎,既全文搜索。
Lucene.Net是Apache基金会的开源项目。
dotNet版的可以在这里找到:http://incubator.apache.org/lucene.net/
最新源码可以直接使用SVN下载:https://svn.apache.org/repos/asf/lucene/lucene.net/tags/
源码网址有时会改变,具体下载不了时,可以到http://incubator.apache.org/lucene.net/查看。
二、简单示例
在下载到Lucence.Net源代码或是dll后,引入到我们的项目中。我们来作一个简单的实例
1。第一步:建立索引
- using Lucene.Net.Index;
- using Lucene.Net.Store;
- using Lucene.Net.Analysis;
- using Lucene.Net.Analysis.Standard;
- using Lucene.Net.Documents;
- /// <summary>
- /// 创建索引
- /// </summary>
- protected void CreatedIndex()
- {
- Analyzer analyzer = new StandardAnalyzer();
- IndexWriter writer = new IndexWriter("IndexDirectory", analyzer, true);
- AddDocument(writer, "SQL Server 2008 的发布", "SQL Server 2008 的新特性");
- AddDocument(writer, "ASP.Net MVC框架配置与分析", "而今,微软推出了新的MVC开发框架,也就是Microsoft ASP.NET 3.5 Extensions");
- writer.Optimize();
- writer.Close();
- }
- /// <summary>
- /// 建立索引字段
- /// </summary>
- /// <param name="writer"></param>
- /// <param name="title"></param>
- /// <param name="content"></param>
- protected void AddDocument(IndexWriter writer, string title, string content)
- {
- Document document = new Document();
- document.Add(new Field("title", title, Field.Store.YES, Field.Index.ANALYZED));
- document.Add(new Field("content", content, Field.Store.YES, Field.Index.ANALYZED));
- writer.AddDocument(document);
- }
第二步:使用索引(测试搜索)
- using Lucene.Net.Index;
- using Lucene.Net.Store;
- using Lucene.Net.Analysis;
- using Lucene.Net.Analysis.Standard;
- using Lucene.Net.Documents;
- using Lucene.Net.Search;
- using Lucene.Net.QueryParsers;
- /// <summary>
- /// 全文搜索
- /// </summary>
- /// <param name="title">搜索字段(范围)</param>
- /// <param name="content">搜索字段(范围)</param>
- /// <param name="keywords">要搜索的关键词</param>
- protected void Search(string title, string content, string keywords)
- {
- Analyzer analyzer = new StandardAnalyzer(); //分词器
- IndexSearcher searcher = new IndexSearcher("IndexDirectory"); //指定其搜索的目录
- MultiFieldQueryParser parser = new MultiFieldQueryParser(new string[] { title, content }, analyzer); //多字段搜索
- //QueryParser q = new QueryParser("indexcontent", new StandardAnalyzer()); //单字段搜索
- Query query = parser.Parse(keywords); //
- Hits hits = searcher.Search(query);
- for (int i = 0; i < hits.Length(); i++)
- {
- Document doc = hits.Doc(i);
- Response.Write(string.Format("字段{3}搜索到:{0} 字段{4}搜索到:{1}", doc.Get("title"), doc.Get("content"), title, content));
- }
- searcher.Close();
- }
Lucene.NET
----------------------------------------------------------------------
介绍一下Lucene.net的使用,使用了Lucene.Net.dll2.1 Highlighter.Net.dll 2.0(高亮) Lucene.Net.Analysis.Cn.dll 1.3(划词引擎):
1 添加索引
/// <summary>
/// 添加索引
/// </summary>
/// <param name="file">索引实体Files</param>
public void AddIndex(Files file) {
IndexWriter writer;
if (IndexReader.IndexExists(GetIndexPath)) {
//非第一次递加
writer = new IndexWriter(GetIndexPath, this.Analyzer, false);
}
else {
//第一次创建
writer = new IndexWriter(GetIndexPath, this.Analyzer, true);
}
Document doc = new Document();
doc.Add(new Field("FileId", file.ID, Field.Store.YES, Field.Index.UN_TOKENIZED));//Field.Index.UN_TOKENIZED 类似把这字段作为主键
doc.Add(new Field("Title", file.Title, Field.Store.YES, Field.Index.TOKENIZED));
switch (file.FileType) {
case FileType.Txt:
doc.Add(new Field("File", new StreamReader(file.Stream, System.Text.Encoding.Default)));
break;
case FileType.Word:
doc.Add(new Field("File", Doc2Text(file.FileName), Field.Store.YES, Field.Index.TOKENIZED));
break;
case FileType.Excel:
doc.Add(new Field("File", Xls2Text(file.FileName), Field.Store.YES, Field.Index.TOKENIZED));
break;
case FileType.Ppt:
doc.Add(new Field("File", Ppt2Text(file.FileName), Field.Store.YES, Field.Index.TOKENIZED));
break;
case FileType.Mht:
doc.Add(new Field("File", Doc2Text(file.FileName), Field.Store.YES, Field.Index.TOKENIZED));
break;
case FileType.Htm:
doc.Add(new Field("File", new StreamReader(file.Stream, System.Text.Encoding.Default)));
break;
default:
break;
}
writer.AddDocument(doc);
writer.Optimize();
writer.Close();
}
其中,把id 的index设为Field.Index.UN_TOKENIZED,差不多就是id做为主键,后面删除索引的时候,直接删除这个id就行
switch (file.FileType)就是根据附件类型,解析读取内容
2 搜索
/// <summary>
/// 搜索
/// </summary>
/// <param name="pSearchStr">查询字符</param>
/// <returns>返回结果集</returns>
public DataTable Search(string pSearchStr) {
if (!string.IsNullOrEmpty(pSearchStr)) {
IndexSearcher searcher = new IndexSearcher(this.GetIndexPath);
//单字段搜索
//QueryParser parser = new QueryParser("title", this.Analyzer);
//Query query = parser.Parse(this.TextBox2.Text.Trim());
//多字段搜索
Query query = MultiFieldQueryParser.Parse(new string[] { pSearchStr, pSearchStr } , new string[] { "Title", "File" }, this.Analyzer);
Hits h = searcher.Search(query);
Document doc;
//高亮显示
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<font color=\"red\">", "</font>");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
//关键内容显示大小设置
//highlighter.SetTextFragmenter(new SimpleFragmenter(400));
DataTable dt = new DataTable();
dt.Columns.Add("Id");//序号
dt.Columns.Add("FileId");//记录ID
dt.Columns.Add("Title");//标题
for (int i = 0; i < h.Length(); i++) {
doc = h.Doc(i);
#region 下载
//try {
// //string strFile=HttpUtility.UrlEncode( myTable.Rows[0]["FileName"].ToString(), System.Text.Encoding.GetEncoding("GB2312")).Replace("+"," ");
// string strFile = HttpUtility.UrlEncode(doc.GetField("title").StringValue(), System.Text.Encoding.UTF8);
// Response.AddHeader("Content-Disposition", "attachment;filename=" + strFile);
// Response.ContentType = ("application/unknown");
// byte[] myByte = doc.GetField("file").BinaryValue();
// Response.BinaryWrite(myByte);
// Response.End();
//}
//catch { }
#endregion
string title = doc.Get("Title");
//取出高亮显示内容
TokenStream tokenStream = (this.Analyzer).TokenStream("Title", new StringReader(title));
string newTitle = highlighter.GetBestFragments(tokenStream, title, 5, "
 ");
");if (!string.IsNullOrEmpty(newTitle)) {
title = newTitle;
}
this.AddRow(dt, i + 1, doc.Get("FileId"), title);
}
searcher.Close();
return dt;
}
return null;
}
现在只对标题(title)和内容(file)做了索引,所以只对这两个字段进行搜索. 最后,返回一个DataTable,包括FileID(记录ID,以便下载附件)和Title(标题). 其中对搜索结果使用了高亮显示Highlighter.
3 删除索引
/// <summary>
/// 删除索引
/// </summary>
/// <param name="pID"></param>
public void Delete(string pID) {
IndexReader reader = IndexReader.Open(GetIndexPath);
Term aTerm = new Term("FileId", pID);
reader.DeleteDocuments(aTerm);
reader.Close();//必须,真正删除
}
先创建个Term,然后用IndexReader删除
4 其他一些辅助属性
#region 属性
string INDEX_STORE_PATH = "index";
/// <summary>
/// 获取/设置index目录
/// </summary>
public string IndexPath {
get {
return INDEX_STORE_PATH;
}
set {
INDEX_STORE_PATH = value;
}
}
/// <summary>
/// 换成物理地址
/// </summary>
private string GetIndexPath {
get {
return HttpContext.Current.Server.MapPath(INDEX_STORE_PATH);
}
}
Analyzer _analyzer = new ChineseAnalyzer();
/// <summary>
/// 获取/设置分析器
/// </summary>
public Analyzer Analyzer {
get {
return _analyzer;
}
set {
_analyzer = value;
}
}
#endregion
5 通过com组件读取office文档内容
#region 利用com组件读取office
/// <summary>
/// 判断文件是否存在
/// </summary>
/// <param name="pFileName"></param>
private void IsExists(string pFileName) {
if (!File.Exists(pFileName)) {
throw new ApplicationException("指定目录下的无该文件");
}
}
//获得word文件的文本内容
public string Doc2Text(string docFileName) {
IsExists(docFileName);
//实例化COM
Word.ApplicationClass wordApp = new Word.ApplicationClass();
object fileobj = docFileName;
object nullobj = System.Reflection.Missing.Value;
//打开指定文件(不同版本的COM参数个数有差异,一般而言除第一个外都用nullobj就行了)
Word.Document doc = wordApp.Documents.Open(ref fileobj, ref nullobj, ref nullobj,
ref nullobj, ref nullobj, ref nullobj,
ref nullobj, ref nullobj, ref nullobj,
ref nullobj, ref nullobj, ref nullobj, ref nullobj, ref nullobj, ref nullobj, ref nullobj
);
//取得doc文件中的文本
string outText = doc.Content.Text;
//关闭文件
doc.Close(ref nullobj, ref nullobj, ref nullobj);
//关闭COM,关闭word程序
wordApp.Quit(ref nullobj, ref nullobj, ref nullobj);
GC.Collect();
//返回
return outText;
}
//获得excel文件的文本内容
public string Xls2Text(string xlsFileName) {
IsExists(xlsFileName);
Excel.Application xlsApp = new Excel.ApplicationClass();
object nullobj = System.Reflection.Missing.Value;
//打开Excel文档
Excel.Workbook excel = xlsApp.Workbooks.Open(xlsFileName, nullobj,
nullobj, nullobj, nullobj,
nullobj, nullobj, nullobj,
nullobj, nullobj, nullobj,
nullobj, nullobj, nullobj,
nullobj);
//遍历Excel工作表
Excel.Worksheet ews = null;
StringBuilder builder = new StringBuilder();
try
{
for (int k = 1; k <= excel.Worksheets.Count; k++)
{
ews = (Excel.Worksheet)excel.Worksheets[k];
//builder.Append(((Excel.Range)ews.UsedRange).Text);
if (ews.UsedRange.Value2 != null)
{
for (int i = 1; i <= ews.UsedRange.Cells.Rows.Count; i++)
{
for (int j = 1; j <= ews.UsedRange.Cells.Columns.Count; j++)
{
if (((object[,])(ews.UsedRange.Value2))[i, j] != null)
{
builder.Append(((object[,])(ews.UsedRange.Value2))[i, j]).Append("|");
}
}
}
}
}
}
catch (Exception ex)
{
throw ex;
}
finally
{
excel.Close(nullobj, nullobj, nullobj);
xlsApp.Quit();
GC.Collect();
}
return builder.ToString();
}
//获得PPT文件的文本内容
public string Ppt2Text(string pptFileName) {
IsExists(pptFileName);
PowerPoint.Application pptApp = new PowerPoint.ApplicationClass();
object nullobj = System.Reflection.Missing.Value;
PowerPoint.Presentation ppt = pptApp.Presentations.Open(pptFileName,
Microsoft.Office.Core.MsoTriState.msoTrue,
Microsoft.Office.Core.MsoTriState.msoFalse,
Microsoft.Office.Core.MsoTriState.msoFalse);
StringBuilder builder = new StringBuilder();
try
{
foreach (PowerPoint.Slide slide in ppt.Slides)
{
foreach (PowerPoint.Shape shape in slide.Shapes)
{
if (shape.TextFrame.HasText == Microsoft.Office.Core.MsoTriState.msoTrue)
{
builder.Append(shape.TextFrame.TextRange.Text);
}
}
}
}
catch (Exception ex)
{
throw ex;
}
finally {
ppt.Close();
pptApp.Quit();
GC.Collect();
}
return builder.ToString();
}
#endregion
最后看下Demo的界面
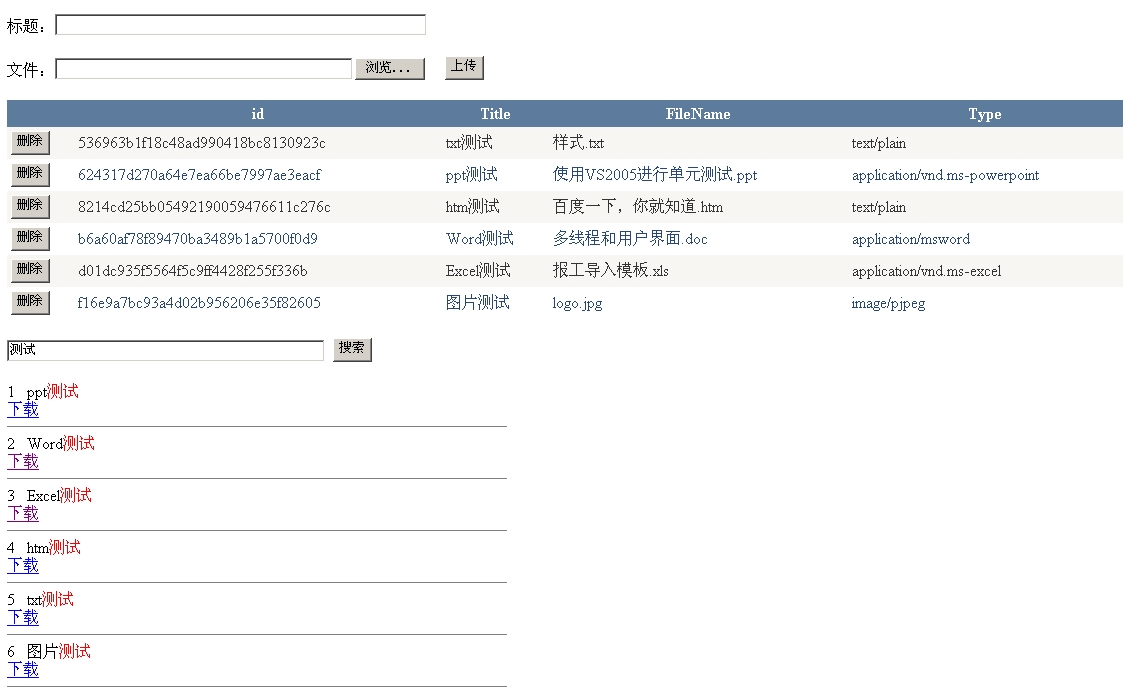
-------------------------------------------------------------------------
 Lucene.net
Lucene.net
 在网上看了一篇外文文章,里面介绍了提高Lucene索引速度的技巧,分享给大家。 阅读全文通常,Lucene的初学者们对Lucene.net索引文件的并发访问、IndexReader和IndexWriter的线程安全性存在一定的误解。而准确地理解这些内容是十分重要的。此文简单的论述下这两个问题。 阅读全文
在网上看了一篇外文文章,里面介绍了提高Lucene索引速度的技巧,分享给大家。 阅读全文通常,Lucene的初学者们对Lucene.net索引文件的并发访问、IndexReader和IndexWriter的线程安全性存在一定的误解。而准确地理解这些内容是十分重要的。此文简单的论述下这两个问题。 阅读全文 前面的文章,我们已经对要检索的数据创建了索引,现在要做的就是为用户提供全文搜索的功能。通过Lucene我们还可以简单而高效地对搜索结果进行访问。此文和大家简单的说说利用Lucene.net进行数据的搜索。 阅读全文Lucene.net提供了很全面的数据搜索操作,你可以利用Lucene.net检索磁盘中的文件,网页,数据库中的数据,但是前提是预先对数据创建索引。此文介绍下Lucene.net中的创建索引。 阅读全文在搜索引擎技术中,分词对于影响搜索引擎结果排序有着至关重要的作用。此文主要介绍下Lucene.net中的分词处理。阅读全文提到Lucene,想必园子中的老鸟们都有所耳闻,很多站点都是利用它搭建自己网站的站内搜索。由于最近也在做数据检索方面的东西,也学习了下Lucene.net的使用。我将利用几篇文章,和大家学习下Lucene.net创建索引,分词,检索等方面的知识。此文先来和大家了
前面的文章,我们已经对要检索的数据创建了索引,现在要做的就是为用户提供全文搜索的功能。通过Lucene我们还可以简单而高效地对搜索结果进行访问。此文和大家简单的说说利用Lucene.net进行数据的搜索。 阅读全文Lucene.net提供了很全面的数据搜索操作,你可以利用Lucene.net检索磁盘中的文件,网页,数据库中的数据,但是前提是预先对数据创建索引。此文介绍下Lucene.net中的创建索引。 阅读全文在搜索引擎技术中,分词对于影响搜索引擎结果排序有着至关重要的作用。此文主要介绍下Lucene.net中的分词处理。阅读全文提到Lucene,想必园子中的老鸟们都有所耳闻,很多站点都是利用它搭建自己网站的站内搜索。由于最近也在做数据检索方面的东西,也学习了下Lucene.net的使用。我将利用几篇文章,和大家学习下Lucene.net创建索引,分词,检索等方面的知识。此文先来和大家了